Download Parallel Database Management Systems: Leveraging Parallelism for Efficient Data Processing and more Slides Database Management Systems (DBMS) in PDF only on Docsity!
Parallel DBMS
Why Parallel Access To Data?
1 Terabyte
10 MB/s
At 10 MB/s
1.2 days to scan
1 Terabyte
1,000 x parallel
1.5 minute to scan.
Parallelism: divide a big problem into many smaller ones to be solved in parallel. Docsity.com
DBMS: The || Success Story
- DBMSs are among most (only?) successful application
of parallelism.
- Teradata, Tandem vs. Thinking Machines,
- Every major DBMS vendor has some || server
- Workstation manufacturers depend on || DB server sales.
- Reasons for success:
- Bulk-processing (= partitioned ||-ism).
- Natural pipelining.
- Inexpensive hardware can do the trick!
- Users/app-prog. don’t need to think in ||
Some || Terminology
proportionally less time
for given amount of data.
- Scale-Up
- If resources increased in
proportion to increase in
data size, time is constant.
degree of ||-ism
Xact/sec. (throughput)
(^) Ideal
degree of ||-ism
sec./Xact (response time)
Ideal
Different Types of DBMS ||-ism
- Intra-operator parallelism
- get all machines working to compute a given operation (scan, sort, join)
- Inter-operator parallelism
- each operator may run concurrently on a different site (exploits pipelining)
- Inter-query parallelism
- different queries run on different site
We’ll focus on intra-operator ||-ism
Automatic Data Partitioning
Partitioning a table:
Range Hash Round Robin
Shared-disk and -memory less sensitive to partitioning, Shared nothing benefits from "good" partitioning!
A...E F...J^ K...N^ O...S^ T...Z^ A...E F...J^ K...N^ O...S^ T...Z^ A...E^ F...J^ K...N^ O...S T...Z
Good for group-by, range queries, and also equip-join
Good for equijoins (^) Good to spread load; Most flexible - but
Parallel Sorting
- New records again and again:
- 8.5 Gb/minute, shared-nothing; Datamation benchmark
in 2.41 secs (UCB students)
- Idea:
- Scan in parallel, and range-partition as you go.
- As tuples come in, begin “local” sorting on each
- Resulting data is sorted, and range-partitioned.
- Problem: skew!
- Solution: “sample” data at start to determine partition
points.
Parallel Joins
- Nested loop:
- Each outer tuple must be compared with each
inner tuple that might join.
- Easy for range partitioning on join cols, hard
otherwise!
- Sort-Merge (or plain Merge-Join):
- Sorting gives range-partitioning.
- Merging partitioned tables is local.
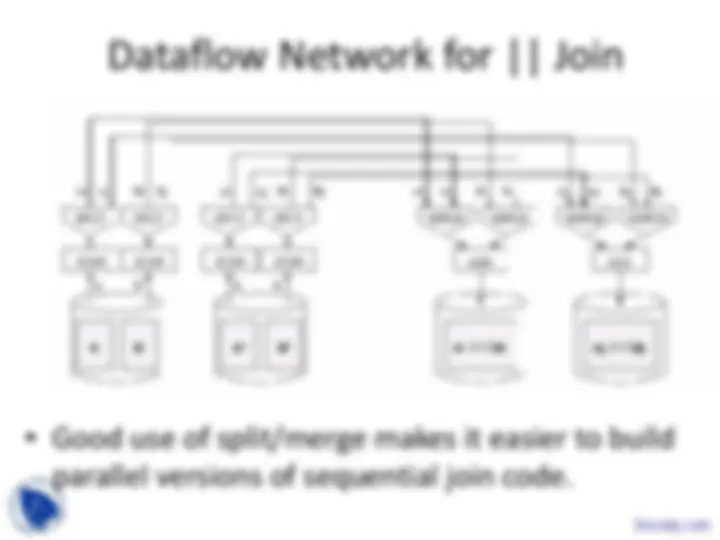
Dataflow Network for || Join
- Good use of split/merge makes it easier to build
parallel versions of sequential join code.
Complex Parallel Query Plans
- Complex Queries: Inter-Operator parallelism
- Pipelining between operators:
- sort and phase 1 of hash-join block the pipeline!!
- Bushy Trees
A B R S
Sites 1-4 Sites 5-
Sites 1-
Observations
- It is relatively easy to build a fast parallel
query executor
- It is hard to write a robust high-quality parallel
query optimizer:
- There are many tricks.
- One quickly hits the complexity barrier.
Parallel Query Optimization
- Common approach: 2 phases
- Pick best sequential plan (System R algo)
- Pick degree of parallelism based on current system
parameters.
- “Bind” operators to processors
- Take query tree, “decorate” with assigned
processor
Parallel DBMS Summary
- ||-ism natural to query processing:
- Both pipeline and partition ||-ism!
- Shared-Nothing vs. Shared-Mem
- Shared-disk too, but less standard
- Shared-memory easy, costly.
- Shared-nothing cheap, scales well.
- Intra-op, Inter-op & Inter-query ||-ism possible.
|| DBMS Summary, cont.
- Data layout choices important!
- Most DB operations can be done partition-||
- Sort-merge join, hash-join.
- Complex plans.
- Allow for pipeline-||ism, but sorts, hashes block the
pipeline.
- Partition ||-ism achieved via bushy trees.