Download Introduction to Parallel Prefix-sum Algorithm: Shared-Memory Parallelism and Concurrency and more Slides Programming Languages in PDF only on Docsity!
A Sophomoric Introduction to Shared-Memory
Parallelism and Concurrency
Parallel Prefix, Pack, and Sorting
Outline
Done:
- Simple ways to use parallelism for counting, summing, finding
- Analysis of running time and implications of Amdahl’s Law
Now: Clever ways to parallelize more than is intuitively possible
- Parallel prefix:
- This “key trick” typically underlies surprising parallelization
- Enables other things like packs
- Parallel sorting: quicksort (not in place) and mergesort
- Easy to get a little parallelism
- With cleverness can get a lot
Parallel prefix-sum
- The parallel-prefix algorithm does two passes
- Each pass has O ( n ) work and O ( log n ) span
- So in total there is O ( n ) work and O ( log n ) span
- So like with array summing, parallelism is n / log n
- First pass builds a tree bottom-up: the “up” pass
- Second pass traverses the tree top-down: the “down” pass
Historical note:
- Original algorithm due to R. Ladner and M. Fischer at the University of Washington in 1977
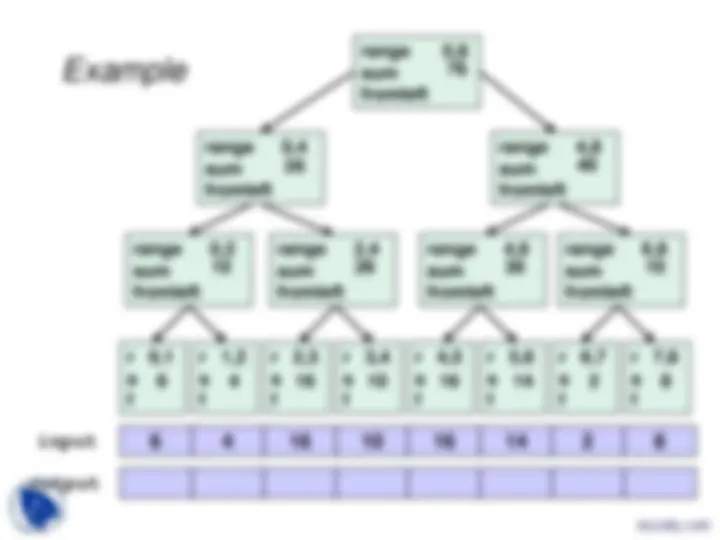
Example
input
output
range 0, sum fromleft
range 0, sum fromleft
range 4, sum fromleft
range 6, sum fromleft
range 4, sum fromleft
range 2, sum fromleft
range 0, sum fromleft
r 0, s f
r 1, s f
r 2, s f
r 3, s f
r 4, s f
r 5, s f
r 6, s f
r 7, s f
6 4 16 10 16 14 2 8
10 26 30 10
36 40
76
The algorithm, part 1
- Up: Build a binary tree where
- Root has sum of the range [ x,y )
- If a node has sum of [ lo,hi ) and hi>lo ,
- Left child has sum of [ lo,middle )
- Right child has sum of [ middle,hi )
- A leaf has sum of [ i,i+1 ), i.e., input[i]
This is an easy fork-join computation: combine results by actually building a binary tree with all the range-sums
- Tree built bottom-up in parallel
- Could be more clever with an array like with heaps
Analysis: O ( n ) work, O ( log n ) span
The algorithm, part 2
- Down: Pass down a value fromLeft
- Root given a fromLeft of 0
- Node takes its fromLeft value and
- Passes its left child the same fromLeft
- Passes its right child its fromLeft plus its left child’s sum (as stored in part 1)
- At the leaf for array position i , output[i]=fromLeft+input[i]
This is an easy fork-join computation: traverse the tree built in step 1 and produce no result
- Leaves assign to output
- Invariant: fromLeft is sum of elements left of the node’s range
Analysis: O ( n ) work, O ( log n ) span
Parallel prefix, generalized
Just as sum-array was the simplest example of a common pattern,
prefix-sum illustrates a pattern that arises in many, many problems
- Minimum, maximum of all elements to the left of i
- Is there an element to the left of i satisfying some property?
- Count of elements to the left of i satisfying some property
- This last one is perfect for an efficient parallel pack…
- Perfect for building on top of the “parallel prefix trick”
- We did an inclusive sum, but exclusive is just as easy
Pack
[Non-standard terminology]
Given an array input , produce an array output containing only elements such that f(elt) is true
Example: input [17, 4, 6, 8, 11, 5, 13, 19, 0, 24]
f: is elt > 10 output [17, 11, 13, 19, 24]
Parallelizable?
- Finding elements for the output is easy
- But getting them in the right place seems hard
Pack comments
- First two steps can be combined into one pass
- Just using a different base case for the prefix sum
- No effect on asymptotic complexity
- Can also combine third step into the down pass of the prefix sum
- Again no effect on asymptotic complexity
- Analysis: O ( n ) work, O ( log n ) span
- 2 or 3 passes, but 3 is a constant
- Parallelized packs will help us parallelize quicksort…
Quicksort review
Recall quicksort was sequential, in-place, expected time O ( n log n )
Best / expected case work
**1. Pick a pivot element O(1)
- Partition all the data into: O(n)** A. The elements less than the pivot B. The pivot **C. The elements greater than the pivot
- Recursively sort A and C 2T(n/2)**
How should we parallelize this?
Doing better
- O ( log n ) speed-up with an infinite number of processors is okay, but a bit underwhelming - Sort 10^9 elements 30 times faster
- Google searches strongly suggest quicksort cannot do better because the partition cannot be parallelized - The Internet has been known to be wrong - But we need auxiliary storage (no longer in place) - In practice, constant factors may make it not worth it, but remember Amdahl’s Law
- Already have everything we need to parallelize the partition…
Parallel partition (not in place)
- This is just two packs!
- We know a pack is O ( n ) work, O ( log n ) span
- Pack elements less than pivot into left side of aux array
- Pack elements greater than pivot into right size of aux array
- Put pivot between them and recursively sort
- With a little more cleverness, can do both packs at once but no effect on asymptotic complexity
- With O ( log n ) span for partition, the total best-case and expected-case span for quicksort is T( n ) = O ( log n ) + 1T( n /2) = O ( log^2 n )
Partition all the data into: A. The elements less than the pivot B. The pivot C. The elements greater than the pivot
Now mergesort
Recall mergesort: sequential, not-in-place, worst-case O ( n log n )
**1. Sort left half and right half 2T(n/2)
- Merge results O(n)**
Just like quicksort, doing the two recursive sorts in parallel changes the recurrence for the span to T( n ) = O ( n ) + 1T( n /2) = O ( n )
- Again, parallelism is O ( log n )
- To do better, need to parallelize the merge
- The trick won’t use parallel prefix this time
Parallelizing the merge
Need to merge two sorted subarrays (may not have the same size)
Idea: Suppose the larger subarray has m elements. In parallel:
- Merge the first m /2 elements of the larger half with the “appropriate” elements of the smaller half
- Merge the second m /2 elements of the larger half with the rest of the smaller half