



Prof. Saman Amarasinghe, MIT. 1 6.189 IAP 2007 MIT
6.189 IAP 2007
Lecture 11
Parallelizing Compilers



























































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
This document, presented by prof. Saman amarasinghe in the iap 2007 course at mit, outlines the concepts of parallel execution, parallelizing compilers, dependence analysis, and increasing parallelization opportunities. It covers types of parallelism, iteration space, dependence definition, data dependence analysis, and techniques for increasing parallelization opportunities such as scalar privatization, reduction recognition, induction variable identification, array privatization, interprocedural parallelization, loop transformations, and granularity of parallelism.
Typology: Slides
1 / 68

This page cannot be seen from the preview
Don't miss anything!
Prof. Saman Amarasinghe, MIT.
1
2
4
5
Programmer Defined Parallel Loop ●^ FORALL^ ^ No “loop carrieddependences”^ ^ Fully parallel Prof. Saman Amarasinghe, MIT.
●^ FORACROSS^ ^ Some “loop carrieddependences”
7
8
10
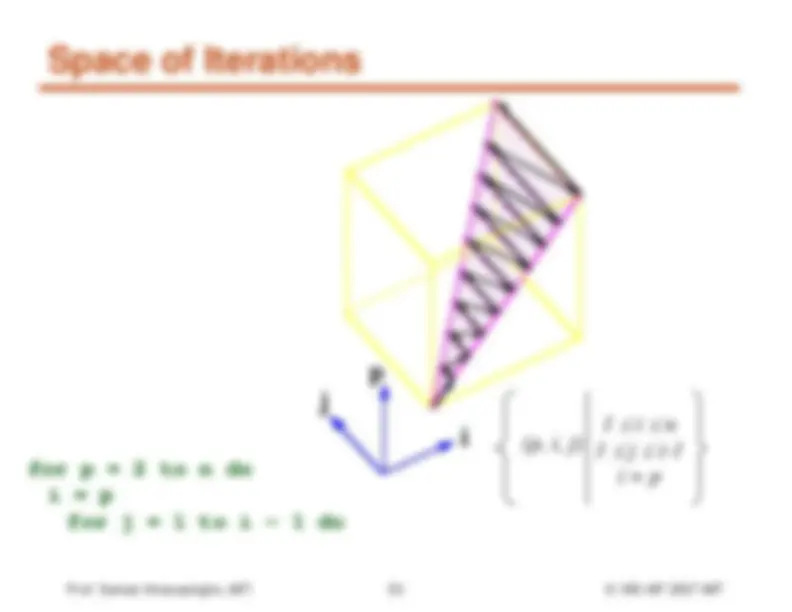
n-dimensional discretecartesian space Normalized loops: assume step size = 1 FOR^ I^ =^0 to^
(^6) FOR J = I to^7 ●^ Iterations are represented ascoordinates in iteration space^ ^ i̅^ = [i, i, i^1
,…, i] 3 n^
(^012) I Æ 3 4 5 6
11
n-dimensional discretecartesian space Normalized loops: assume step size = 1 FOR^ I^ =^0 to^
(^6) FOR J = I to^7 ●^ Iterations are represented ascoordinates in iteration space ●^ Sequential execution order of iterations^ Î^ Lexicographic order[0,0], [0,1], [0,2], …, [0,6], [0,7],[1,1], [1,2], …, [1,6], [1,7],[2,2], …, [2,6], [2,7],
………[6,6], [6,7],
(^012) I Æ 3 4 5 6
13
n-dimensional discretecartesian space Normalized loops: assume step size = 1 FOR^ I^ =^0 to^
(^6) FOR J = I to^7 ●^ An affine loop nest^ ^ Loop bounds are integer linear functions ofconstants, loop constant variables andouter loop indexes^ ^ Array accesses are integer linear functionsof constants, loop constant variables andloop indexes
(^012) I Æ 3 4 5 6
14
n-dimensional discretecartesian space Normalized loops: assume step size = 1 FOR^ I^ =^0 to^
(^6) FOR J = I to^7 ●^ Affine loop nest
Æ^ Iteration space as aset of liner inequalities 0 ≤ I I ≤ (^6) I ≤ J J ≤ 7
(^012) I Æ 3 4 5 6
16
17
19
FOR I = 0 to 5A[I] = A[I] + 1 0 1 2^3 4
Iteration Space^5
Data Space
= A[I]A[I]= A[I]A[I]= A[I]A[I]= A[I]A[I]= A[I]A[I]= A[I]A[I]
20
FOR I = 0 to 5A[I+1] = A[I] + 1 0 1 2^3 4
Iteration Space^5
Data Space
= A[I]A[I+1]= A[I]A[I+1]= A[I]A[I+1]= A[I]A[I+1]= A[I]A[I+1]= A[I]A[I+1]