Recap: Lecture 9
Single cycle verses multi cycle datapath
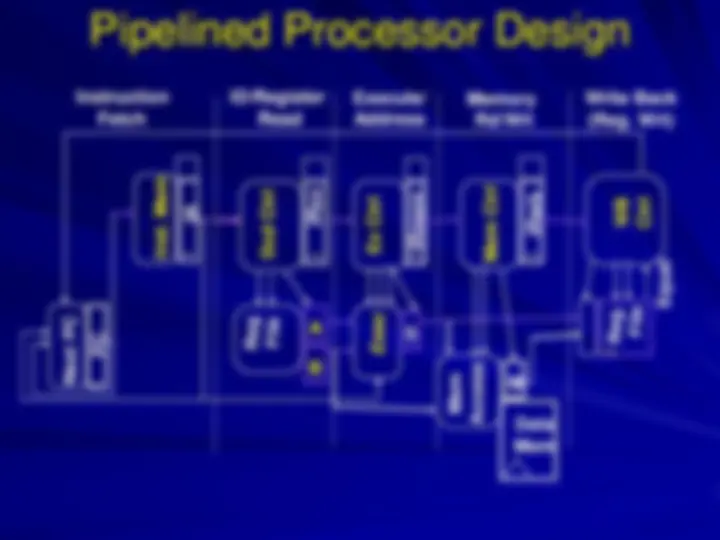
Key components of multi cycle data path
Design and information flow in multi cycle
data path
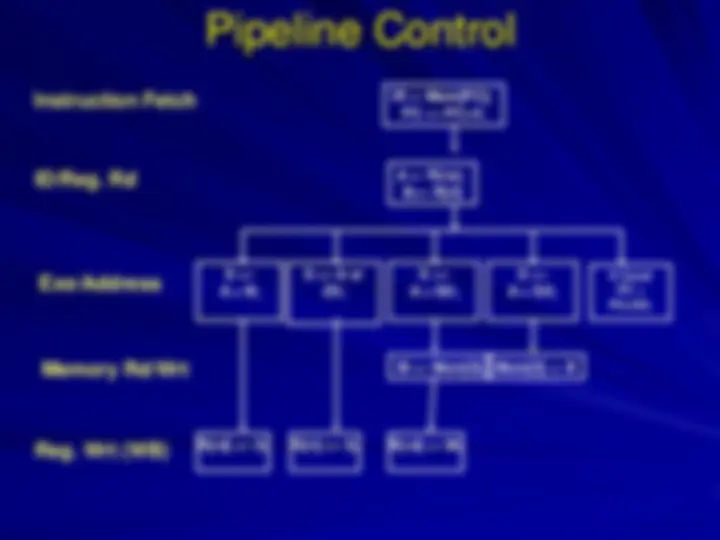
Multi cycle control unit design
Finite State Machine–based control Unit
Microprogram-based controller
docsity.com