


CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois 1
Intel IXP 2850
& IXA Architecture
CS 433
Processor Presentation Series
Prof. Luddy Harrison










































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of the intel ixp2800/2850 processor, focusing on its key architectural components, applications, and the significance of its integrated security functionality. The processor is used for high-performance network processing and routing, with speeds ranging from oc-3 to oc-192. Its unique feature is the integration of security functionality into the core, allowing for faster speeds and lower power requirements.
Typology: Study notes
1 / 52

This page cannot be seen from the preview
Don't miss anything!
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois
These slide presentations were prepared bystudents of CS433 at the University of Illinois atUrbana-Champaign
All the drawings and figures in these slides weredrawn by the students. Some drawings are basedon figures in the manufacturer’s documentation forthe processor, but none are electronic copies ofsuch drawings
You are free to use these slides provided that youleave the credits and copyright notices intact
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois IXP 2800/2850 Applications
High performance network processing and routing z Speeds from OC-3 (155 Mbps) to OC-192 (10 Gbps)
Found in situations operating with heavy traffic andprocessing requirements z Internet core and edge routers/switches z Storage Area Networks (SANs) z Datacenter or enterprise routers/switches
Advanced traffic management z Deep packet inspection z Load balancing z High speed packet forwarding
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois IXP 2850 Specific Applications
Base package identical to IXP
2 security specific functional units (“blocks”) handle: z Cryptographic algorithms: DES, SHA-1, AES, etc z Encrypting/Decrypting IPsec packets at OC-192 speeds z Able to do this on one 10Gbps connection or severalindividual 1Gbps connections simultaneously
These capabilities allow for acceleration of: z Web services: TCP/SSL encryption, E-Commerce apps z VPNs: Require constant encryption, fast connections z Most other applications that require end to end encryption
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois Hardware Configuration z Typically found in multiprocessorconfigurations z Most common setup involves oneprocessor for “ingress” packets and onefor “egress” packets z Processor configuration usually resideson an industry standard board, multiplesof which may fit inside an ATCA case z Typical packet path through network: z Packets ingress from a SONET networkor some other type of physical interfaceto the first IXP z Packets are inspected for where theyneed to go and are passed to thebackplane z Backplane decides if packet needs to goto the resident egress processor fortransmission back onto the Internet, or toanother IXP egress processor on aseparate card connected to the switchfabric Framing/Mac Device (i.e. SONET) Uses SPI-4 Protocol
Switch Fabric(i.e. Infiniband) Flow Control TxDATA TxDATA RxDATA RxDATA
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois Hardware Configuration Details z Incoming packets arrive in one physical form or another (usually optical) and aretransferred into the processors via the SPI-4 protocol which performs a translationfrom the physical medium to a data stream the processor can understand z The gasket is another translation device which takes data from the ingressprocessor, turns it into wider (memory-wise) data for use on the switch fabric if it issupported, and then converts it back again for egress z The switch fabric can use any number of protocols and is the means by whichnetwork processors talk to one another across cards such as in an ATCAconfiguration. In this way, packets can be forwarded across the fabric amongstrouters in the same box, rather than having to make the hop on some form ofnetwork transmission cable z The ingress and egress processors perform separate but complementary functions: Ingress Egress 2800/ Inspection, Forwarding decisions,Metering (i.e. for billing), Policing (isconnection allowed?), etc Traffic shaping, Quality ofService enforcement, etc 2850 only Decryption, Authentication (inbound) Encryption, Authentication(outbound)
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois
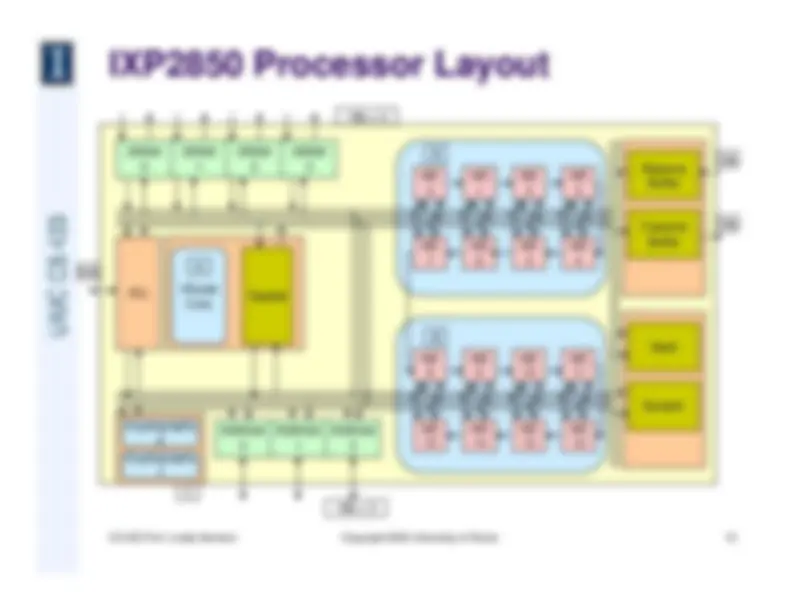
Hash ReceiveBuffer TransmitBuffer^ Scratch ME^1 ME 2 ME^3 ME 7 ME^6 ME 5 ME^4 ME^9 ME^10 ME^11 ME^15 ME^14 ME^13 ME^12 ME 8 ME 0 RDRAM 0 RDRAM 1 RDRAM 2 SRAM 0 SRAM 1 SRAM 2 SRAM 3 XScale Core Gasket PCI 18b x 3 18b x 3 64b 16b 16b B C A B Cryptography 0 Cryptography 1
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois A) XScale Core Layout Subset and Memory z Coprocessor Support z Allows for add in cards to interface asquickly as possible z Example would be security add in cardswith an IXP2800 (which 2850 rectifies) z 32b wide bus with 16 registers providedto help move data into core memory z Instruction and Data Caches and Supporting Units z Both 32kb and are fed by a Memory Management Unit (MMU) for address translation z Both are 32 set / 2 way associative z Data has a 2kb mini cache for frequently changing data streams; helps avoid thrashingin main data cache z Branch target buffer – 128 entries; provides history and prediction from insn cache z Write buffer – 8 entries deep, 1 entry = 16 bytes, holds data until core bus can handle z Internal Memory System z Transfers 32bit words (1 load, 1 store) per cycle z 4.8 GBytes/sec total data rate (bidirectional bus, 600 MHz)
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois B) Microengine Layout Subset and Memory z Execution core z Minimal with high frequency instructions z Very high speed in comparison to rest of processor z Memory z 2 banks of 128 General Purpose Registers z 16 slot Context Addressable Memory provides coherency across engines z 2 banks of 128 registers for static memory access (in/out) z 2 banks of 128 registers for dynamic memory access (in/out) z 640 word local memory z Next Neighbor z 128 registers for data from previousengine z Circuitry for forwarding data to nextneighbor z Allows engines to keep pipelines full whilewaiting for loads/stores to complete
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois MicroEngine Core Execution Core (Mult,Add, Shift, First Bit) CAM 128 GPR 128 GPR 128 NextNeighbor 128 SRAM tx in 128 RDRAM tx in 128 RDRAM tx out 128 SDRAM tx out 8k InstructionControl Store a^ b S-Bus in R-Bus in R-Bus out S-Bus out To next neighbor From next neighbor 640 Words Local Memory
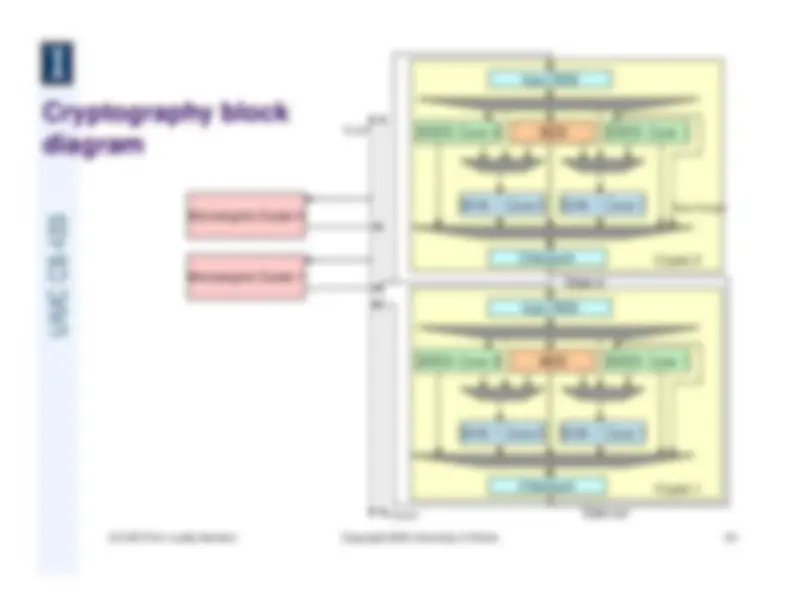
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois Cryptographic Algorithm Implementation Overview z 3DES z Supports Cipher Block Chaining (diagram). 3 unique keys are then applied through theDES algorithm once each to produce the final cipher text z Because DES algorithm is run 3 times to produce “3DES”, the unit will first grab all keys tobe used at once and then use the same block three times in a row InitializationVector (IV) Clear Text XOR CryptoAlgorithm Unique Key Cipher Text z AES z Algorithm is designed for fast encryption, yet decryption must run at same rate z Algorithm supports three different key lengths (128,192,256) z Requires implementation of Key Scheduler which can support all three possible key sizesthat AES supports. Performs necessary computation to keep decryption keys in line withencryption keys z SHA-1 z Can operate either on data straight from memory bus or data already encrypted using amethod listed above z Has a 512 bit block size, thus necessitating an accumulator buffer to store up ciphered data z Includes ability to compute HMACs (Hash Message Authentication Code) which is used forverifying data integrity and authenticity
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois Internet Exchange Architecture (IXA) Defined z The model through which the IXP2850 (and most of Intel’s othernetwork processors) are programmed z Defined by three distinct components: z
z
z
z
z
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois z End goal is to make processing as parallel as possible z Each microengine is a miniature RISC processor which uses 8“contexts” for parallelization (2 sets worth for the IXP2800/ z Automates tasks previously left up to programmer: z Handling competition for shared memory between microengines z Taking the standalone packet processing algorithm andtranslating it into a highly parallel algorithm z Handling communication which allows microengines to movedata and control amongst each other in order to fill the pipeline Auto-Partitioning PPS_0 PPS_N (.c & .h files) C Compiler Linker XScale 0 16 1 2 Microengine arrays PPS_
CS 433 Prof. Luddy Harrison Copyright 2005 University of Illinois Programming Model As a Whole z You, the programmer, write a set of .c files and performancespecification files z The compiler takes these inputs and produces its code based onthree core constructs: z
z
z
pipe pipe Memory Hierarchy (SRAM, RDRAM, internal memory, etc)