Download Reinforcement Learning: Maximizing Rewards and Policies and more Study notes Programming Languages in PDF only on Docsity!
Reinforcement
Learning, Cont’d
Useful refs: Sutton & Barto, Reinforcement Learning: An Introduction , MIT Press 1998. http://www.cs.ualberta.ca/~sutton/book/the-book.html Kaelbling, Littman, & Moore, ``Reinforcement Learning: A Survey,'' Journal of Artificial Intelligence Research ,Volume 4,
http://people.csail.mit.edu/u/l/lpk/public_html/ papers/rl-survey.ps
Administrivia
Mid-class survey results (momentarily)
Reading 2 due today
New assignments:
Final project proposal
Due Nov 5 (Fri), 5:00 PM
To me or in my mailbox
Paper preferred
Reading 3: Due Nov 9
Bentivegna, D. C. and Atkeson, C. G. “Learning How to Behave from Observing Others” SAB'02-Workshop on Motor Control in Humans and Robots , Edinburgh, UK, August, 2002.
Survey Results: Lectures
Pacing 0.00 0.50 1.00 1.50 2.00 2.50 3.00 3.50 4. 1 2 3 4 5 6 7 Content Math Intuition Slides Access. Too little Too much
Survey Results: Exercises
0.00 0.50 1.00 1.50 2.00 2.50 3.00 3.50 4. 1 2 3 4 Useful? (binary) Quantity Length Graded? (binary) Too little Too much
Start with an easy case
V. simple maze:
Whenever Mack goes left, he gets cheese
Whenever he goes right, he gets shocked
After reward/punishment, he’s reset back to start of maze
Q: how can Mack learn to act well in this world?
Reward functions
In general, we think of a reward function:
R () tells us whether Mack thinks a particular outcome is good or bad
Mack before drugs:
R (cheese)=+
R (shock)=-
Mack after drugs:
R (cheese)=-
R (shock)=+
Behavior always depends on rewards (utilities)
R : outcomes →
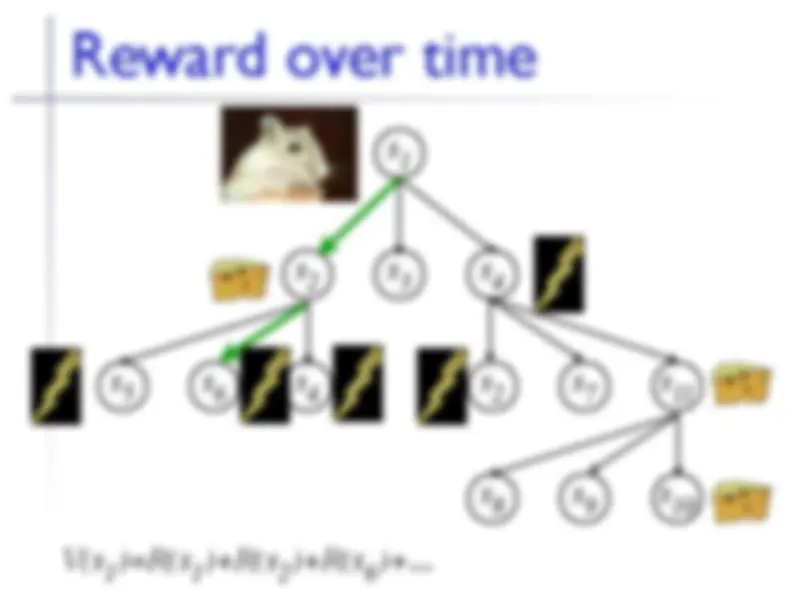
Reward over time
In general: agent can be in a state s i at any time t
Can choose an action a j to take in that state
Rwd associated with a state:
R ( s i
Or with a state/action transition:
R ( s i ,a j
Series of actions leads to series of rewards
( s 1 ,a 1 )→ s 3 : R ( s 3 ); ( s 3 , a 7 )→ s 14 : R ( s 14
Reward over time
s 1 s 2 s 3 s 4 s 5 s 6 s 4 s 2 s 7 s 11 s 8 s 9 s 10
Reward over time
s 1 s 2 s 3 s 4 s 5 s 6 s 4 s 2 s 7 s 11 s 8 s 9 s 10 V(s 1 )=R(s 1 )+R(s 2 )+R(s 6
Where can you go?
Definition : Complete set of all states agent could be in is called the state space : S
Could be discrete or continuous
We’ll usually work with discrete
Size of state space: | S |
Definition : Complete set of actions an agent could take is called the action space: A
Again, discrete or cont.
Again, we work w/ discrete
Again, size: | A |
Experience & histories
In supervised learning, “fundamental unit of experience”: feature vector+label
Fundamental unit of experience in RL:
At time t in some state s i , take action a j , get reward r t , end up in state s k
Called an experience tuple or SARSA tuple
Set of all experience during a single episode up to time t is a history:
〈X, y〉
〈si , aj , rt , sk 〉
h T = {〈st=1 , at=1 , rt=1 〉, 〈st=2 , at=2 , rt=2 〉,... ,
〈st=T , at=T , rt=T 〉}