Download Statistics Q&A Exercises and more Exercises Statistics in PDF only on Docsity!
Statistics
Introduction to Statistics: -
Stats Definition : - Stats is the science of collecting, organizing and analyzing data. Data : - Facts or pieces of information E.g.: - 1. Height of student in classroom
- No. of sales in term of revenue of a company
- IQ of students in classroom Type of Statistics : -
- Descriptive Statistics
- Inferential Statistics 1. Descriptive Statistics: - it consists of organizing summarizing and Visualizing data.
I. Measure of Central Tendency: -
II. Measures of Dispersion: -
III. Different type of distribution of data: - i. Bernoulli Distribution ii. Uniform Distribution iii. Binomial Distribution iv. Normal or Gaussian Distribution v. Exponential Distribution vi. Poisson Distribution
2. Inferential Statistics : - Inferential statistics are used to make conclusions about the population by using analytical tools on the sample data. Measures of inferential statistics are T-test Z-test CHI Square Test Anova test Hypothesis testing P-Value Significance value
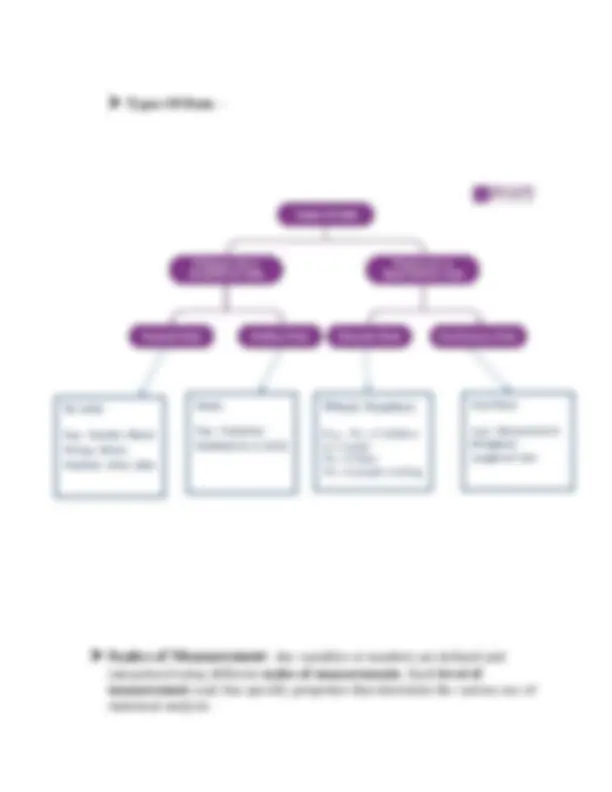
➢ Types Of Data : - ➢ Scales of Measurement : - the variables or numbers are defined and categorized using different scales of measurements. Each level of measurement scale has specific properties that determine the various use of statistical analysis Whole Numbers E.g.:- No. of children in a family No. of bikes No. of people working e.g.:- No. of children in a Family Any Value e.g.:- House price in Bengaluru Length of river No ranks E.g.:- Gender, Blood Group, Colors, location, cities, days Ranks E.g.:- Customer feedback {1, 2,3,4,5}
There are four different scales of measurement.
- Nominal Scale
- Ordinal Scale
- Interval Scale
- Ratio Scale I. Nominal Scale data: - A nominal scale is the 1st^ level of measurement scale in which the numbers serve as “tags” or “labels” to classify or identify the objects. A nominal scale usually deals with the non-numeric variables or the numbers that do not have any value
- Qualitative/ Categorical Data
- E.g.: - Gender, color, Labels
- Order or rank does not matter II. Ordinal Scale Data: - The ordinal scale is the 2nd^ level of measurement that reports the ordering and ranking of data without establishing the degree of variation between them. Ordinal represents the “order.”
scale has a unique feature. It possesses the character of the origin or zero points.
- The order matters
- Differences are measurable (Ratio)
- Contant a “0” Starting point
- E.g.: - o Students marks in a class ❖ Descriptive Statistics
1. Measure of Central Tendency: -
o Mean o Median o Mode ➢ Mean : - The mean represents the average value of the dataset. It can be calculated as the sum of all the values in the dataset divided by the number of values. ➢ Median : - Median is the middle value of the dataset in which the dataset is arranged in the ascending order or in descending order. When the dataset contains an even number of values, then the median value of the dataset can be found by taking the mean of the middle two values. Consider the given dataset with the odd number of observations arranged in descending order – 23, 21, 18, 16, 15, 13, 12, 10, 9, 7, 6, 5, and 2
Here 12 is the middle or median number that has 6 values above it and 6 values below it. Now, consider another example with an even number of observations that are arranged in descending order – 40, 38, 35, 33, 32, 30, 29, 27, 26, 24, 23, 22, 19, and 17 When you look at the given dataset, the two middle values obtained are 27 and 29. Now, find out the mean value for these two numbers. i.e., (27+29)/2 = Therefore, the median for the given data distribution is 28.
I. Variance: -
- The sample variance is divided by n-1 so that we can create an Unbiased estimator of the population variance
- More the spread more the variance II. Standard Deviation: - The square root of the variance is known as the standard deviation i.e. S.D. = √σ.
- A standard deviation is used to determine how estimations for a group of observations (i.e., data set) are spread out from the mean (average or expected value).
- How many STD Xi is away from mean
➢ Random Variables: - A random variable is a process of mapping the output of a random process or experiment to a number. E.g.: - Tossing a coin Rolling a dice ➢ Sets: - A= {1,2,3,4,5,6,7,8} B= {3,4,5,6,7} I. Intersection: - A ∩ B = {3,4,5,6,7} II. Union: - A ∪ B = {1,2,3,4,5,6,7,8} III. Difference: - A-B= {1,2,8} IV. Subset: - A B = False B A= True
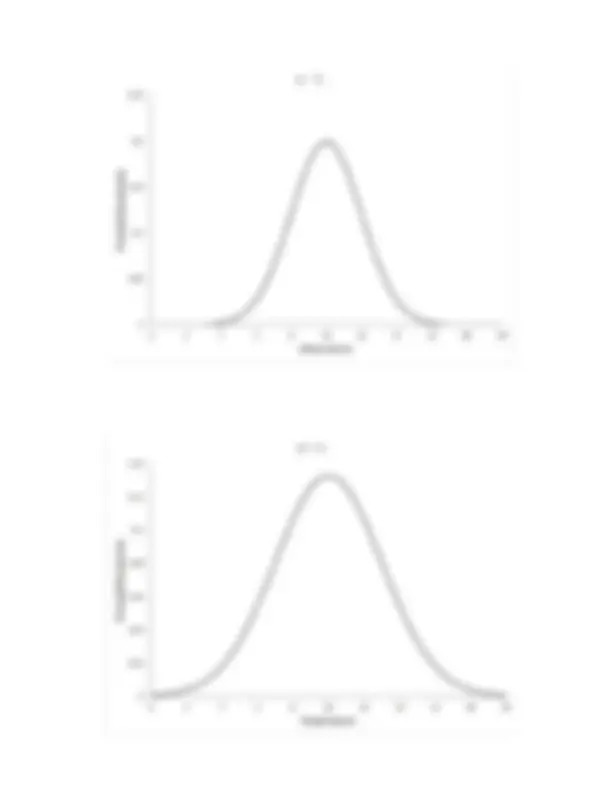
A. No Skewed: - B. Right Skewed: - Mean > Median > Mode
C. Left Skewed: - Mean < Median < Mode
❖ sampling Techniques: -
E. Purposive sampling:- This type of sampling, also known as judgement sampling, involves the researcher using their expertise to select a sample that is most useful to the purposes of the research. It is often used in qualitative research, where the researcher wants to gain detailed knowledge about a specific phenomenon rather than make statistical inferences, or where the population is very small and specific. An effective purposive sample must have clear criteria and rationale for inclusion. Always make sure to describe your inclusion and exclusion criteria and beware of observer bias affecting your arguments. Example: Purposive sampling:- You want to know more about the opinions and experiences of disabled students at your university, so you purposefully select a number of students with different support needs in order to gather a varied range of data on their experiences with student services. F. Cluster sampling:- Cluster sampling also involves dividing the population into subgroups, but each subgroup should have similar characteristics to the whole sample. Instead of sampling individuals from each subgroup, you randomly select entire subgroups. If it is practically possible, you might include every individual from each sampled cluster. If the clusters themselves are large, you can also sample individuals from within each cluster using one of the techniques above. This is called multistage sampling. This method is good for dealing with large and dispersed populations, but there is more risk of error in the sample, as there could be substantial differences between clusters. It’s difficult to guarantee that the sampled clusters are really representative of the whole population. Example: Cluster sampling: - The company has offices in 10 cities across the country (all with roughly the same number of employees in similar roles). You don’t have the capacity to travel to every office to collect your data, so you use random sampling to select 3 offices – these are your clusters.
A. Pearson correlation coefficient : - The Pearson correlation coefficient ( r ) is the most common way of measuring a linear correlation. It is a number between – 1 and 1 that measures the strength and direction of the relationship between two variables. Pearson correlation coefficient ( r ) Correlation type Interpretation Example Between 0 and 1 Positive correlation When one variable changes, the other variable changes in the same direction. Baby length & weight: The longer the baby, the heavier their weight. 0 No correlation There is no relationship between the variables. Car price & width of windshield wipers: The price of a car is not related to the width of its windshield wipers. Between 0 and – 1 Negative correlation When one variable changes, the other variable changes in the opposite direction. Elevation & air pressure: The higher the elevation, the lower the air pressure. where
- cov is the covariance
- σx is the standard deviation of X
- σy is the standard deviation of Y B. Spearman's rank correlation coefficient:- A correlation can easily be drawn as a scatter graph, but the most precise way to compare several pairs of data is to use a statistical test - this establishes whether the correlation is really significant or if it could have been the result of chance alone. Spearman's Rank correlation coefficient is a technique which can be used to summarise the strength and direction (negative or positive) of a relationship between two variables. The result will always be between 1 and minus 1.
❖ Probability Distribution Function: - a distribution function is a
mathematical expression that describes the probability of different possible outcomes for an experiment. Let us say we are running an experiment of tossing a fair coin. The possible events are Heads , Tails. And for instance, if we use X to denote the events, the probability distribution of X would take the value 0.5 for X=heads, and 0.5 for X=tails o Data Types : - we have Qualitative and Quantitative data. And in Quantitative data, we have Continuous and Discrete data types. ➢ Continuous data is measured and can take any number of values in a given finite or infinite range. It can be represented in decimal format. And the random variable that holds continuous values is called the Continuous random variable. Examples: A person’s height, Time, distance, etc. ➢ Discrete data is counted and can take only a limited number of values. It makes no sense when written in decimal format. And the random variable that holds discrete data is called the Discrete random variable. Example: The number of students in a class, number of workers in a company, etc.