



Statistics - DADE
◼Topic 6
◼Hypothesis Testing: Two Populations
◼Professor Dr. Carlos Alberto Lastras Rodríguez































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Is about maths applying the hypothesis testing. There are the different formulas in order to understand the subject.
Typology: Cheat Sheet
1 / 43

This page cannot be seen from the preview
Don't miss anything!
◼ Professor Dr. Carlos Alberto Lastras Rodríguez
After completing this chapter, you should be able to: ◼ Test hypotheses for the difference between two population means ◼ Two means, matched pairs ◼ Independent populations, population variances known ◼ Independent populations, population variances unknown but equal ◼ Complete a hypothesis test for the difference between two proportions (large samples) ◼ Use the F table to find critical F values ◼ Complete an F test for the equality of two variances
Tests Means of 2 Related Populations ◼ Paired or matched samples ◼ Repeated measures (before/after) ◼ Use difference between paired values: ◼ Assumptions: ◼ Both Populations Are Normally Distributed Dependent Samples
i
i
- y i
Tests of the Difference Between Two Normal Population Means: Dependent Samples
where n s d t d = sd = sample standard dev. of differences n = the sample size (number of pairs) Population Means, Dependent Samples n d d i For tests of the = following form: H 0 : μ x
H 0 : μx – μy ≤ 0 H 0 : μ x
◼ Assume you send your salespeople to a “customer service” training workshop. Has the training made a difference in the number of complaints? You collect the following data:
Number of Complaints: (2) - (1) Salesperson Before (1) After (2) Difference, d i C.B. 6 4 - 2 T.F. 20 6 - 14 M.H. 3 2 - 1 R.K. 0 0 0 M.O. 4 0 - 4
- 21
di n
n 1 (d d) S 2 i d = − − =
◼ Has the training made a difference in the number of complaints (at the a = 0.05 level)? d = - 4.
d
0 : μ x
1 : μ x
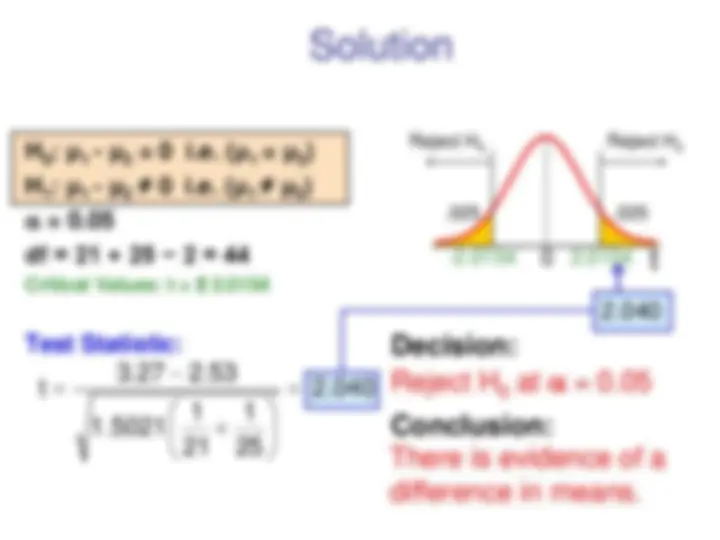
Test Statistic: Critical Value = ± 2. d.f. = n − 1 = 4 Reject a /
- 2.776 2. Decision: Do not reject H 0 (t stat is not in the reject region) Conclusion: There is not a significant change in the number of complaints.
Reject a /
- 1. a =.
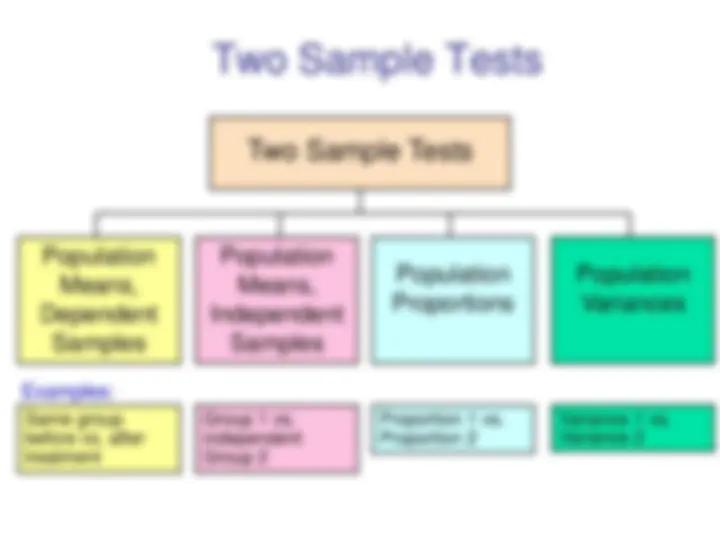
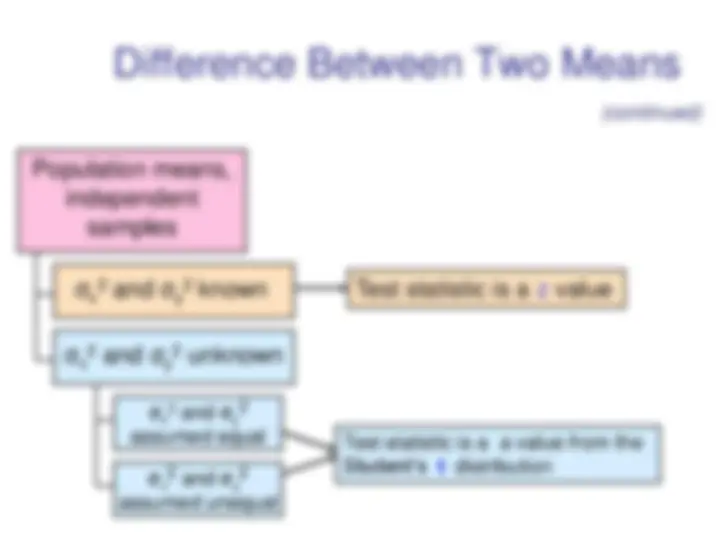
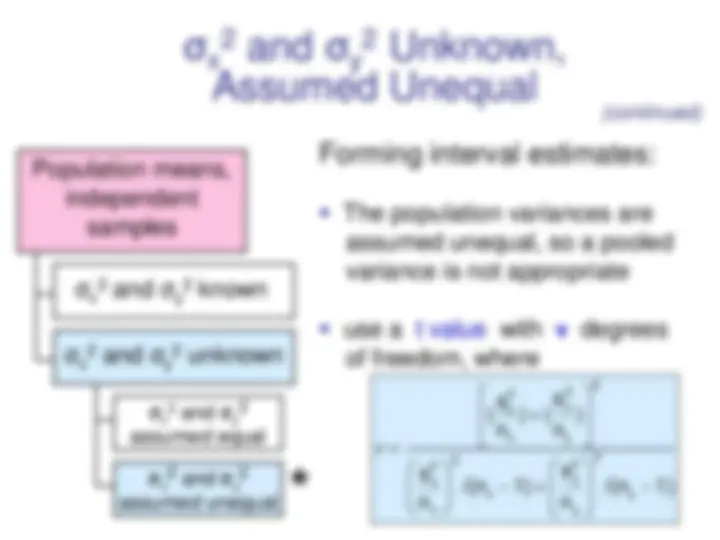
Population means, independent samples Test statistic is a z value Test statistic is a a value from the Student’s t distribution σx 2 and σy 2 assumed equal σ x 2 and σ y 2 known σ x 2 and σ y 2 unknown σx 2 and σy 2 assumed unequal (continued)
Population means, independent samples
▪ Samples are randomly and independently drawn ▪ both population distributions are normal ▪ Population variances are known
σ x 2 and σ y 2 known σ x 2 and σ y 2 unknown
Population means, independent samples
σ x 2 and σ y 2 known σ x 2 and σ y 2 unknown
y 2 y x 2 x
μ x
H :μ μ 0 0 x y − =
Lower-tail test: H 0 : μx μy H 1 : μx < μy i.e., H 0 : μ x
1 : μ x
Upper-tail test: H 0 : μx ≤ μy H 1 : μx > μy i.e., H 0 : μ x
1 : μ x
Two-tail test: H 0 : μx = μy H 1 : μx ≠ μy i.e., H 0 : μ x
1 : μ x
Two Population Means, Independent Samples
Population means, independent samples
▪ Samples are randomly and independently drawn ▪ Populations are normally distributed ▪ Population variances are unknown but assumed equal
σx 2 and σy 2 assumed equal σ x 2 and σ y 2 known σ x 2 and σ y 2 unknown σx 2 and σy 2 assumed unequal
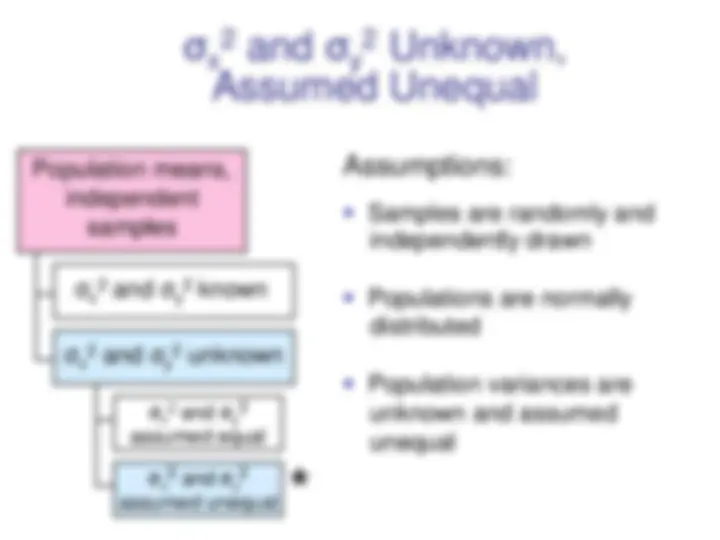
Population means, independent samples (continued) ▪ The population variances are assumed equal, so use the two sample standard deviations and pool them to estimate σ ▪ use a t value with (n x
σx 2 and σy 2 assumed equal σ x 2 and σ y 2 known σ x 2 and σ y 2 unknown σx 2 and σy 2 assumed unequal
Lower-tail test: H 0 : μx – μy 0 H 1 : μ x
Upper-tail test: H 0 : μx – μy ≤ 0 H 1 : μ x
Two-tail test: H 0 : μx – μy = 0 H 1 : μ x
a
a/ Reject H 0 if t < - t (^) (n1+n2 – 2), a Reject H 0 if t > t (^) (n1+n2 – 2), a Reject H 0 if t < - t (^) (n1+n2 – 2), a/2 or t > t (^) (n1+n2 – 2), a/ Two Population Means, Independent Samples, Variances Unknown
You are a financial analyst for a brokerage firm. Is there a difference in dividend yield between stocks listed on the NYSE & NASDAQ? You collect the following data: NYSE NASDAQ Number 21 25 Sample mean 3.27 2. Sample std dev 1.30 1. Assuming both populations are approximately normal with equal variances, is there a difference in average yield (a = 0.05)?