Download Vector Processing - Multimedia Signal Processing - Lecture Slides and more Slides Electronics engineering in PDF only on Docsity!
Lecture 6:
Vector Processing
- Speculation: Out-of-order execution, In-order commit (reorder buffer+renameReview registers)=>precise exceptions
- Branch Prediction
- – Branch History Table: 2 bits for loop accuracyRecently executed branches correlated with next branch?
- – Branch Target Buffer: include branch address & predictionPredicated Execution can reduce number of branches, number of mispredicted branches
- Software Pipelining – Symbolic loop unrolling (instructions from different iterations) to optimize pipeline with little code expansion, little overhead
- Superscalar and VLIW(“EPIC”): CPI < 1 (IPC > 1) – Dynamic issue vs. Static issue
- – More instructions issue at same time => larger hazard penalty# independent instructions = # functional units X latency
Review: Instructon Level Parallelism
- High speed execution based on instruction level parallelism (ilp): potential of short instruction sequences to execute in parallel
- High-speed microprocessors exploit ILP by:
- pipelined execution: overlap instructions
- superscalar execution: issue and execute multiple instructions per clock cycle
- Out-of-order execution (commit in-order)
- Memory accesses for high-speed microprocessor? - Data Cache, possibly multiported, multiple levels
Problems with conventional approach
- Limits to conventional exploitation of ILP:
- pipelined clock rate : at some point, each increase in clock rate has corresponding CPI increase (branches, other hazards)
- instruction fetch and decode : at some point, its hard to fetch and decode more instructions per clock cycle
- cache hit rate : some long-running (scientific) programs have very large data sets accessed with poor locality; others have continuous data streams (multimedia) and hence poor locality
Properties of Vector Processors
- Each result independent of previous result => long pipeline, compiler ensures no dependencies => high clock rate
- Vector instructions access memory with known pattern => highly interleaved memory => amortize memory latency of over 64 elements => no (data) caches required! (Do use instruction cache)
- Reduces branches and branch problems in pipelines
- Single vector instruction implies lots of work ( loop) => fewer instruction fetches
Operation & Instruction Count:
RISC v. Vector Processor
Spec92fp Operations (Millions)(from F. Quintana, U. Barcelona.) Instructions (M) Program RISC Vector R / V RISC Vector R / V swim256 115 95 1.1x 115 0.8 142x hydro2d 58 40 1.4x 58 0.8 71x nasa7 69 41 1.7x 69 2.2 31x su2cor 51 35 1.4x 51 1.8 29x tomcatv 15 10 1.4x 15 1.3 11x wave5 27 25 1.1x 27 7.2 4x mdljdp2 32 52 0.6x 32 15.8 2x
Vector reduces ops by 1.2X, instructions by 20X
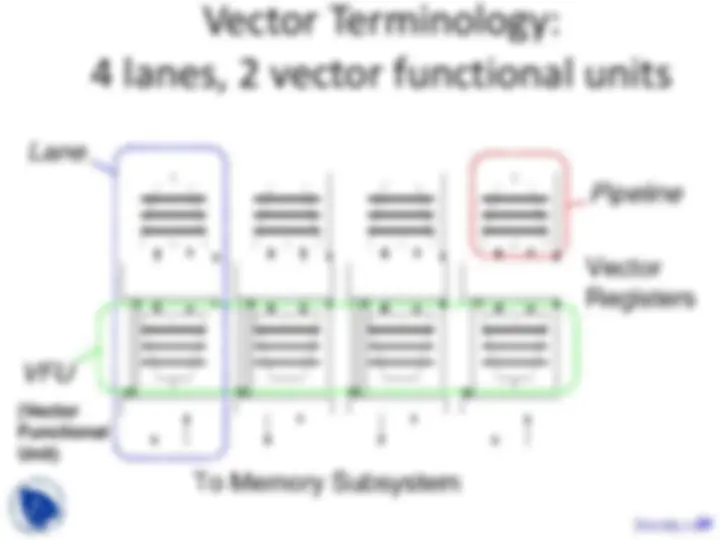
Components of Vector Processor
- Vector Register : fixed length bank holding a single vector - has at least 2 read and 1 write ports - typically 8-32 vector registers, each holding 64- 64-bit elements
- Vector Functional Units (FUs) : fully pipelined, start new operation every clock - typically 4 to 8 FUs: FP add, FP mult, FP reciprocal (1/X), integer add, logical, shift; may have multiple of same unit
“DLXV” Vector
Instr. Operands OperationInstructions Comment
- ADDV V1,V2,V3 V1=V2+V vector + vector
- ADDSV V1,F0,V2 V1=F0+V
scalar + vector
- MULTV V1,V2,V3 V1=V2xV vector x vector
- MULSV V1,F0,V2 V1=F0xV
scalar x vector
- LV V1,R1 V1=M[R1..R1+63] load, stride=1Docsity.com
DAXPY (Y = a * X + Y)
LD F0,a ADDI R4,Rx,#512 ;last address to load loop: LD F2, 0(Rx) ;load X(i) MULTD F2,F0, F2 ;aX(i) LD F4, 0(Ry) ;load Y(i) ADDD F4,F2, F4 ;aX(i) + Y(i) SD F4 ,0(Ry) ;store into Y(i) ADDI Rx,Rx,#8 ;increment index to X ADDI Ry,Ry,#8 ;increment index to Y SUB R20,R4,Rx ;compute bound BNZ R20,loop ;check if done
LD F0,a ;load scalar a LV V1,Rx ;load vector X MULTS V2,F0,V1 ;vector-scalar mult. LV V3,Ry ;load vector Y ADDV V4,V2,V3 ;add SV Ry,V4 ;store the result
Assuming vectors X, Y are length 64 Scalar vs. Vector
578 (2+964) vs. 321 (1+564) ops (1.8X) 578 (2+964) vs. 6 instructions (96X) 64 operation vectors + no loop overhead also 64X fewer pipeline hazards*
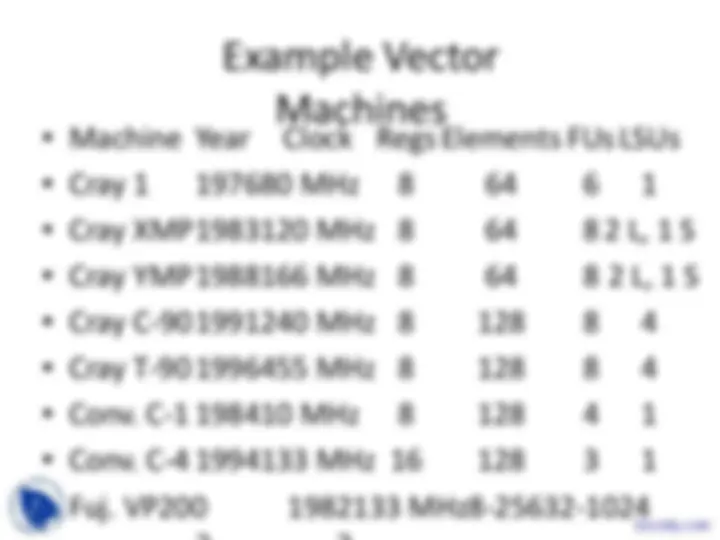
Example Vector Machines
- Machine Year Clock Regs Elements FUs LSUs
- Cray 1 197680 MHz 8 64 6 1
- Cray XMP 1983120 MHz 8 64 8 2 L, 1 S
- Cray YMP 1988166 MHz 8 64 8 2 L, 1 S
- Cray C-90 1991240 MHz 8 128 8 4
- Cray T-90 1996455 MHz 8 128 8 4
- Conv. C-1 198410 MHz 8 128 4 1
- Conv. C-4 1994133 MHz 16 128 3 1
- Fuj. VP200 1982133 MHz8-25632-1024Docsity.com
CS 252 Administrivia
- Get your photo taken by Joe Gebis! (or give URL)
- Exercises for Lectures 3 to 7
- Due Thursday Febuary 12 at 5PM homework box in 283 Soda (building is locked at 6:45 PM)
- 4.2, 4.10, 4.19, 4.14 parts c) and d) only, B.
- Done in pairs, but both need to understand whole assignment; Anyone need a partner?
- Study groups encouraged, but pairs do own work
- Turn in (copy of)photo with name on it Docsity.com
Computers in the News
- IBM researchers announced (at ISSCC ‘98) they have demonstrated the world's first experimental CMOS microprocessor that can operate at 1000 MHz
- The chip contains 1 million transistors and uses 0.25-micron circuit technology
- Integer only, 4 stage pipeline, + caches; innovations include: - A multifunctional unit, which combines addition and rotation operations into a single circuit Docsity.com
Virtial Processor Vector Model
- Vector operations are SIMD (single instruction multiple data)operations
- Each element is computed by a virtual processor (VP)
- Number of VPs given by vector length
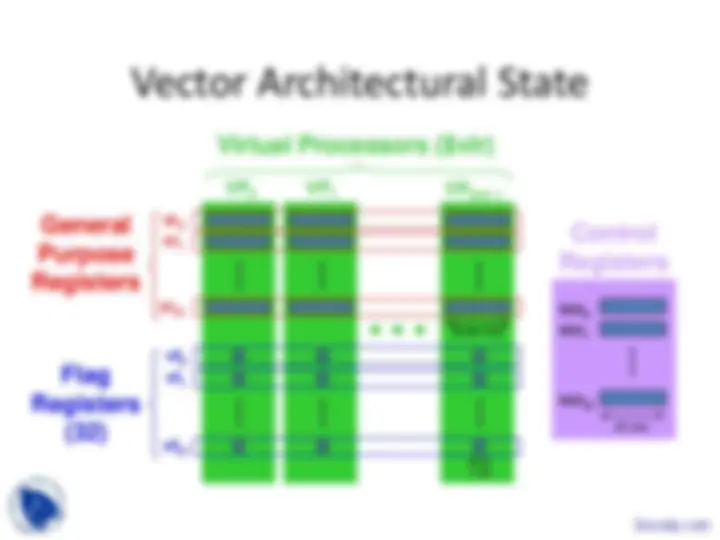
Vector Architectural State
General Purpose Registers
Flag Registers (32)
VP 0 VP 1 VP$vlr- vr (^0) vr (^1)
vr (^31) vf (^0) vf (^1)
vf (^31)
$vdw bits
1 bit
Virtual Processors ($vlr)
vcr (^0) vcr (^1)
vcr (^31)
Control Registers
32 bits