¡Descarga Correlaciones entre Escolarización, Hijos e Ingresos Familiares y más Apuntes en PDF de Derecho Constitucional solo en Docsity!
SEMINARIO 8
En primer lugar debemos comprobar si las variables recogen los casos perdidos. En esta base de
datos las variables a estudiar están limpias, es decir, no recogen datos perdidos.
Cuando en el gráfico no tenemos claro lo que hay, tenemos que recurrir a la R de Pearson.
La R de Pearson puede tomar valores de entre -1 y +1.
SPSS, Guía para el análisis de datos 11. Es un manual de SPSS. Si no lo tuviéramos, ahora
tenemos a Google que nos saca del entuerto.
Los que hemos conseguido hacer la correlacion, veréis que a veces aparecen unas estrellitas.
Quieren decir que cuando el valor crítico es menor que 0,05 es una estrellita. Cuando el valor
crítico es menor que 0.01 te pone dos estrellitas: quiere decir que hay mucha o muchísima
confianza.
Podemos decir que con un nivel de confianza del 99%, podemos decir que en EEUU hay una
relación significativa, inversa y lineal entre nivel de estudios y el número de hijos.
En la correlación podemos decir que nos comprar la correlación de dos variables o de muchas
variables. Si ponemos todas las variables que nos interesan en el menú de correlaciones,
podremos hacerlo.
Si en un menú de variables ponemos todas las variables, nos creará una tabla en la que se
contrastan todas las variables.
Correlaciones Número de hijos Años de escolarizació n
Número ideal de hijos
Ingresos familiares 1991 totales Número de hijos Correlación de Pearson
1 -,237 **^ ,157 -,
Sig. (bilateral) ,004 ,127 , N 149 149 96 143 Años de escolarización Correlación de Pearson
-,237**^1 -,021 ,437 **
Sig. (bilateral) ,004 ,840 , N 149 150 96 143 Número ideal de hijos Correlación de Pearson
Sig. (bilateral) ,127 ,840 , N 96 96 96 93 Ingresos familiares 1991 totales
Correlación de Pearson
-,051 ,437 **^ -,035 1
Sig. (bilateral) ,543 ,000 , N 143 143 93 143 **. La correlación es significativa al nivel 0,01 (bilateral).
Ahora hacemos los mismo, pero en vez de darle a aceptar, Le damos a pegar.
Ponemos ‘with’ entre ‘hijos’ y ‘educación’. Es decir, ponemos ‘with’ entre la VD y todas las
demás. Me correlaciona solamente la VD con todas las demás, la tabla es mucho más legible.
Seleccionamos todo y le damos a Control + R. o le damos al botón verde de play.
Y nos sale esto:
Correlaciones Años de escolarización
Número ideal de hijos
Ingresos familiares 1991 totales
Edad del encuestado
Número de hijos Correlación de Pearson -,237**^ ,157 -,051 ,404 ** Sig. (bilateral) ,004 ,127 ,543 , N 149 96 143 149 **. La correlación es significativa al nivel 0,01 (bilateral).
Él en el trabajo no quiere las tablas, solo los valores. Pero en el caso de esta última tabla, no le
importa. Lo que no quiere es la tabla doble y gorda de antes. (Habría que quitarle las líneas,
ponerle el título y la fuente).
Las estrellitas de la parte de abajo es la leyenda de la tabla. Nos pone la estrellita en las
correlaciones que con significativas.
Si el valor crítico (sig) fuera igual a 0.05, no puede ser. No puede ser igual a 0.05, porque si
hacemos doble clic sobre él nos salen más decimales. Pero en cualquier caso, 0.05 no es menor
que 0.05, por lo que no nos vale.
Pero cuidado, estamos trabajando con algunas variables que no son continuas, y la R de Pearson
solo nos vale para variables continuas.
Tenemos dos opciones: o quitamos esas variables de la base de datos o las tratamos como
variables ordinales.
Ahora, cuando queremos estudiar la relación entre variables ordinales o una variable ordinal y
una continua, debemos hacerlo con la Tau-b de Kendall y Spearman, que están en la parte
inferior de la pantalla.
Esto se hace cuando alguna de las variables o todas son ordinales.
Le damos ahora a pegar, nos sale sintaxis y hacemos esto, que lo hacemos para quitar los
valores perdidos:
Sig. (bilateral) ,001. , N 964 965 930 Ingresos familiares 1991 totales
Coeficiente de correlación
Sig. (bilateral) ,641 ,. N 1431 930 1434 **. La correlación es significativa al nivel 0,01 (bilateral).
Los valores de Kendall y Spearman son igual que los de Pearson, van de -1 a +1.
De este modo observamos que existe una realidad directa entre el número ideal de hijos y el
número de hijos que se tiene.
Ahora aprenderemos como recodificar una variable
Seleccionamos años de escolarización.
Lo primero es describir la variable que queremos recodificar.
Años de escolarización Frecuencia Porcentaje Porcentaje válido
Porcentaje acumulado Válidos 0 2 ,1 ,1 , 2 4 ,3 ,3 , 4 7 ,5 ,5 , 5 7 ,5 ,5 1, 6 20 1,3 1,3 2, 7 26 1,7 1,7 4, 8 59 3,9 3,9 8, 9 45 3,0 3,0 11, 10 55 3,7 3,7 15, 11 81 5,4 5,4 20, 12 445 29,7 29,7 50, 13 135 9,0 9,0 59, 14 166 11,1 11,1 70, 15 70 4,7 4,7 75, 16 208 13,9 13,9 88, 17 46 3,1 3,1 92, 18 71 4,7 4,7 96, 19 24 1,6 1,6 98, 20 25 1,7 1,7 100, Total 1496 99,7 100, Perdidos 98 4 , Total 1500 100,
Las recodificaciones las dirige a teoría, es decir, somos nosotros quienes decidimos los puntos
de corte.
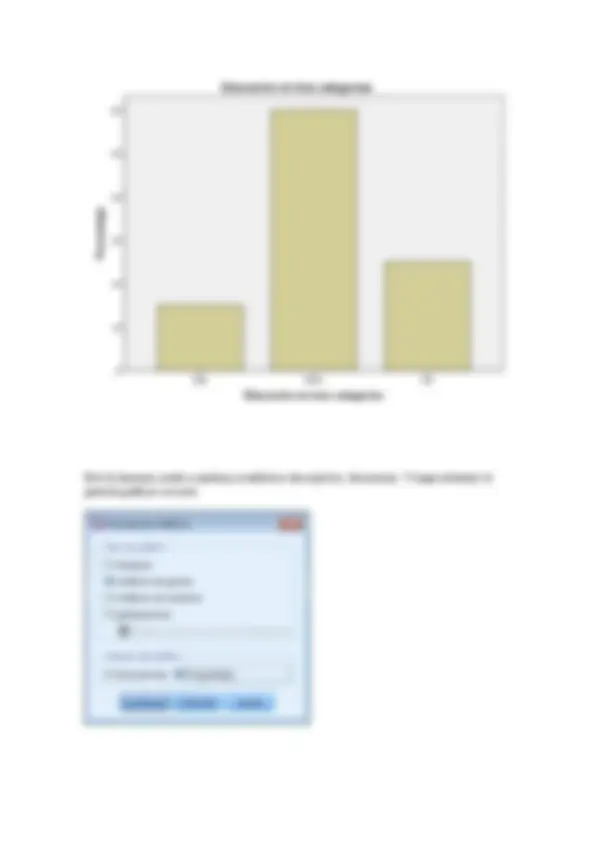
Vamos a hacer u histograma para elegir esto.
Podemos hacer tres grupos: hasta 10 años, hasta 15 y hasta 20. Ésta será nuestra nueva variable.
Se llamará Educ_3.
Para ello partiremos de la variable Educ. esta tiene valores desde 0 hasta 20. Los valores de
Educ_3 serán:
0 – Bajo
1 – Medio
2 – Alto
Las variables de Educ son
Educ Educ_
De 0 a 10 0 – Bajo
De 11 a 15 1 – Medio
De 15 a 20 2 – Alto
Ahora nos vamos a transformar.
Le damos a cambiar. Ahora educ es educ_3.
Ahora le damos a valores antiguos y nuevos.
Creamos los nuevos valores.
Pero mejor definimos un rango, porque este sistema es mejor para valores específicos.
Todos los demás de la damos a perdidos por el sistema.
Ahora le damos a continuar y aceptar y ya tenemos nuestra nueva variable, que aparecerá al
final de la base de datos.
Le damos a frecuencia y analizar.
Tenemos que etiquetar los valores.