Investigación: La distribución normal 1/12
www.fisterra.com Atención Primaria en la Red
La distribución normal
Pértegas Díaz S., Pita Fernández S.
Unidad de Epidemiología Clínica y Bioestadística. Complexo Hospitalario Juan Canalejo. A Coruña.
Cad Aten Primaria 2001; 8: 268-274.
Actualización 10/12/2001.
__________________________________
1. Introducción
Al iniciar el análisis estadístico de una serie de datos, y después de la etapa de detección y corrección de
errores, un primer paso consiste en describir la distribución de las variables estudiadas y, en particular, de
los datos numéricos. Además de las medidas descriptivas correspondientes, el comportamiento de estas
variables puede explorarse gráficamente de un modo muy simple. Consideremos, como ejemplo, los
datos de la Figura 1a, que muestra un histograma de la tensión arterial sistólica de una serie de pacientes
isquémicos ingresados en una unidad de cuidados intensivos. Para construir este tipo de gráfico, se divide
el rango de valores de la variable en intervalos de igual longitud, representando sobre cada intervalo un
rectángulo con área proporcional al número de datos en ese rango1. Uniendo los puntos medios del
extremo superior de las barras, se obtiene el llamado polígono de frecuencias. Si se observase una gran
cantidad de valores de la variable de interés, se podría construir un histograma en el que las bases de los
rectángulos fuesen cada vez más pequeñas, de modo que el polígono de frecuencias tendría una
apariencia cada vez más suavizada, tal y como se muestra en la Figura 1b. Esta curva suave "asintótica"
representa de modo intuitivo la distribución teórica de la característica observada. Es la llamada función
de densidad.
Una de las distribuciones teóricas mejor estudiadas en los textos de bioestadística y más utilizada en la
práctica es la distribución normal, también llamada distribución gaussiana2, 3, 4, 5. Su importancia se
debe fundamentalmente a la frecuencia con la que distintas variables asociadas a fenómenos naturales y
cotidianos siguen, aproximadamente, esta distribución. Caracteres morfológicos (como la talla o el peso),
o psicológicos (como el cociente intelectual) son ejemplos de variables de las que frecuentemente se
asume que siguen una distribución normal. No obstante, y aunque algunos autores6, 7 han señalado que el
comportamiento de muchos parámetros en el campo de la salud puede ser descrito mediante una
distribución normal, puede resultar incluso poco frecuente encontrar variables que se ajusten a este tipo
de comportamiento.
El uso extendido de la distribución normal en las aplicaciones estadísticas puede explicarse, además, por
otras razones. Muchos de los procedimientos estadísticos habitualmente utilizados asumen la normalidad
de los datos observados. Aunque muchas de estas técnicas no son demasiado sensibles a desviaciones de
la normal y, en general, esta hipótesis puede obviarse cuando se dispone de un número suficiente de
datos, resulta recomendable contrastar siempre si se puede asumir o no una distribución normal. La
simple exploración visual de los datos puede sugerir la forma de su distribución. No obstante, existen
otras medidas, gráficos de normalidad y contrastes de hipótesis que pueden ayudarnos a decidir, de un
modo más riguroso, si la muestra de la que se dispone procede o no de una distribución normal. Cuando
los datos no sean normales, podremos o bien transformarlos8 o emplear otros métodos estadísticos que no
exijan este tipo de restricciones (los llamados métodos no paramétricos).
A continuación se describirá la distribución normal, su ecuación matemática y sus propiedades más
relevantes, proporcionando algún ejemplo sobre sus aplicaciones a la inferencia estadística. En la sección
3 se describirán los métodos habituales para contrastar la hipótesis de normalidad.
2. La Distribución Normal
La distribución normal fue reconocida por primera vez por el francés Abraham de Moivre (1667-1754).
Posteriormente, Carl Friedrich Gauss (1777-1855) elaboró desarrollos más profundos y formuló la
ecuación de la curva; de ahí que también se la conozca, más comúnmente, como la "campana de
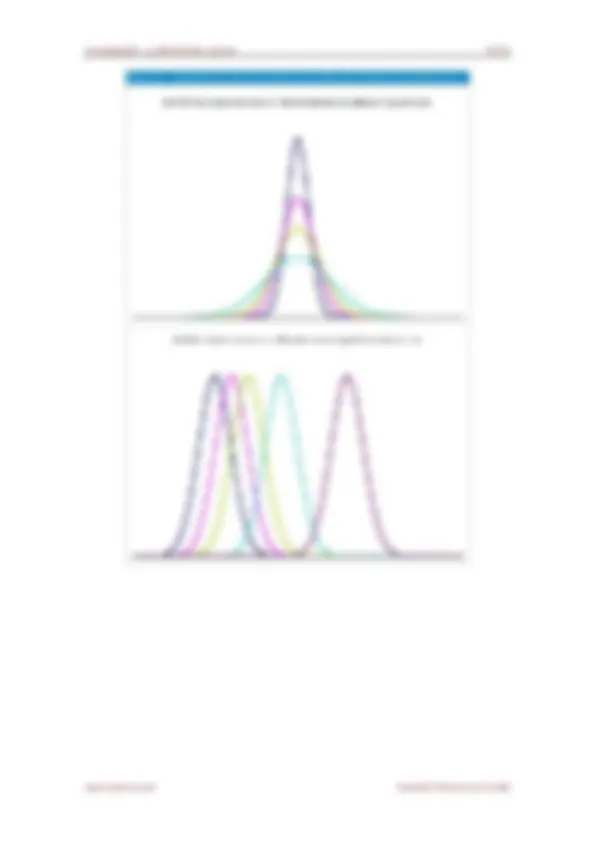
Gauss". La distribución de una variable normal está completamente determinada por dos parámetros, su
media y su desviación estándar, denotadas generalmente por y . Con esta notación, la densidad de
la normal viene dada por la ecuación: