1.3 El ADN Repetitivo
Como hemos visto al principio de este Capítulo, hasta un 50% del Genoma Humano está constituido por
ADN repetitivo, antiguamente conocido como "ADN basura". Por su importancia, a continuación
estudiamos con mayor detalle su composición y los distintos tipos de secuencias que lo forman. Ya se ha
mencionado que podemos encontrar ADN repetitivo tanto en el ADN codificante (en los genes y secuencias
relacionadas) como en el ADN no-codificante, pero la mayor parte se encuentra en el ADN no-codificante.
Quizás el único ejemplo de ADN repetitivo codificante que merece la pena reseñar es el correspondiente
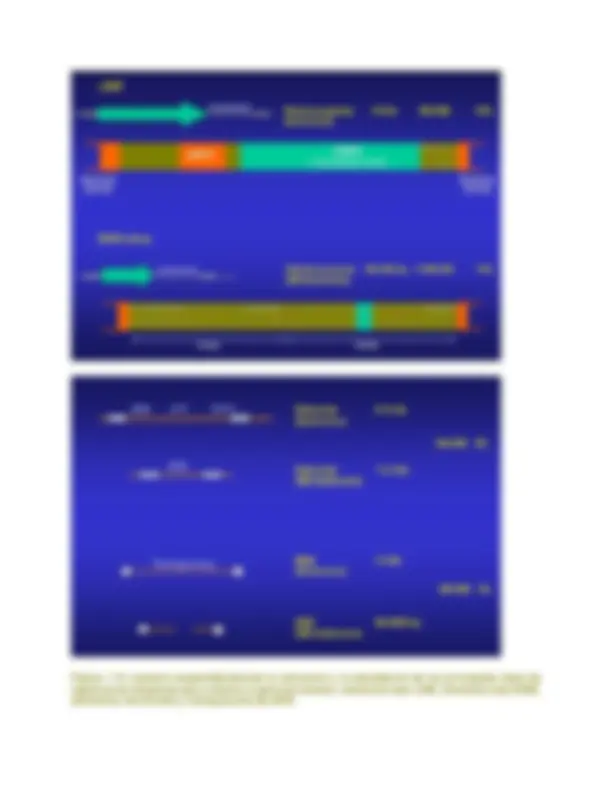
al ADN ribosomal, que se concentra en los brazos cortos de los cromosomas acrocéntricos (13, 14, 15,
21 y 22) y está formado por tres genes que dan lugar a los tres ARN ribosomales de 5,8S, de 18S y de
28S. Los tres genes están juntos formando un bloque que mide unas 13 kilobases. Estos bloques se
encuentran repetidos unas 50 veces, separados entre sí por un espaciador intergénico que mide unas 30
kilobases. En conjunto, el ADN ribosomal ocupa un tamaño de unas 2 Megabases.
En el ADN no-codificante, tanto intragénico (es decir, intrones y otras regiones no-codificantes
relacionadas con genes) como extragénico, podemos encontrar diversos tipos de elementos repetidos. En
general, se trata de una secuencia de ADN que se repite en el genoma cientos o miles de veces. Estas
repeticiones pueden encontrarse en tándem (es decir, seguidas una detrás de otra) o dispersas.
El ADN repetido en tandem se divide en varios grupos según el tamaño total que origina la repetición:
El genoma humano contiene en total unas 250 Mb de ADN satélite (llamado así porque al separar
el ADN genómico en gradientes de densidad aparece como 3 bandas "satélites" de la banda
principal). El ADN satélite está formado por la repetición de una secuencia de ADN miles de veces
en tandem, es decir unas copias pegadas a otras. Esto da lugar a regiones repetidas con tamaños
que van desde 100 kb hasta varias megabases. Por ejemplo, el ADN Satélite 1 es una secuencia
de 42 nucleótidos, mientras que en el Satélite 2 la secuencia repetida es (ATTCCATTCG) y en el
Satélite 3 se repite el pentámero (ATTCC). Un tipo de ADN satélite muy importante es el ADN
alfoide ó Satélite alfa, en el que la secuencia repetida tiene un tamaño de 171 nucleótidos, y que
forma parte del ADN de los centrómeros de los cromosomas humanos. Otros tipos de ADN satélite
son el Satélite beta (repetición de 68 nucleótidos) y el Satélite gamma (repetición de 220
nucleótidos), que también se encuentran en la cromatina centromérica de varios cromosomas.
El ADN de tipo Minisatélite está formado por secuencias de 6 - 25 nucleótidos que se repiten en
tándem hasta dar un tamaño total entre 100 nucleótidos y 20 kb. Un ejemplo de ADN Minisatélite
es la repetición que forma los telómeros de los cromosomas humanos, en los que el
hexanucleótido (TTAGGG) se repite miles de veces en tándem dando lugar a bloques de 5 - 20 kb
de tamaño. Algunas repeticiones de este tipo son polimórficas, y dan lugar a los marcadores de
tipo VNTR que hemos mencionado en un apartado anterior.
El ADN de tipo Microsatélite está formado por secuencias de 2, 3 ó 4 nucleótidos que se repiten
hasta dar bloques con un tamaño total habitualmente no superior a 150 nucleótidos. Hay
repeticiones de este tipo por todo el genoma humano, y muchas de ellas son muy útiles como
marcadores genéticos porque el número de repeticiones varía entre individuos. Ejemplos de ADN
microsatélite son los dinucleótidos (CA), ó las repeticiones de trinucleótidos (CAG).
El ADN repetido disperso está formado por secuencias que se repiten miles de veces en el genoma
humano, pero no en tándem sino de manera dispersa. Este tipo de repeticiones constituyen un 45% de
todo el genoma humano, y se clasifican en función del tamaño de la unidad repetida:
Los SINE (Short Interspersed Nuclear Elements, elementos nucleares dispersos cortos) suponen
un 13% del genoma humano. Son secuencias cortas repetidas miles de veces en el genoma
humano de forma dispersa. El principal SINE es la familia de elementos Alu, que es específica de
primates y constituye un 10% de nuestro genoma. Un elemento Alu está formado por una