



OPENMARKOV
TUTORIAL
www.openmarkov.org
Version 0.4.0
June 9, 2021
CISIAD
UNED




























































Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
An overview of decision analysis networks (dans), a type of probabilistic graphical model used for decision making. Dans contain chance, decision, and utility nodes, and allow the user to evaluate the expected utility of different decisions based on probabilities and utilities. The document also covers the implementation of ids in openmarkov and the concept of imposing policies on decision nodes.
Tipo: Apuntes
1 / 72

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
3.1 Effectiveness of the therapies............................... 21
5.1 Cost of each intervention................................. 41 5.2 Optimal policy for therapy on the scenario Do test? = yes and Result of test = positive........................................... 47
6.1 Transition probabilities for monotherapy........................ 49 6.2 Transition probabilities for the first three years of combined therapy......... 49 6.3 Annual costs per states and therapy type........................ 50 6.4 withDirichlet distribution parameters for transition probabilities.......... 57 6.5 Direct medical and community care cost means associated with each state..... 58
v
vi
This section offers a brief overview of OpenMarkov’s graphical user interface (GUI). The main screen has the following elements (see Figure 1.1):
Figure 1.1: A Bayesian network consisting of two nodes.
If you wish to move a node, click on the Selection tool icon and drag the node. It is also possible to move a set of selected nodes by dragging any of them.
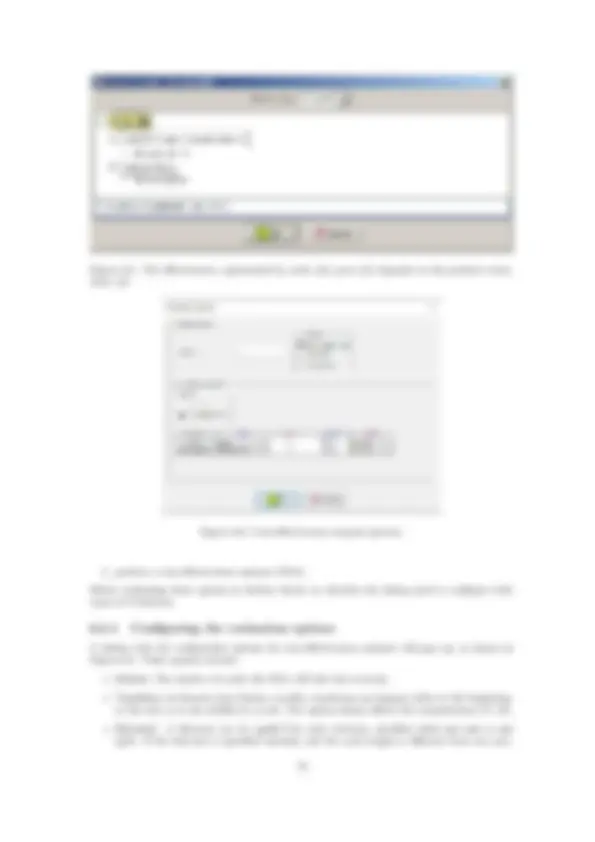
Once we have the nodes and links, we have to introduce the numerical probabilities. In the case of a Bayesian network, we must introduce a conditional probability table (CPT) for each node. The CPT for the variable Disease is given by its prevalence, which, according with the state- ment of the example, is P ( Disease = present ) = 0_._ 14. We introduce this parameter by right-clicking on the Disease node, selecting the Edit probability item in the contextual menu, choosing Table as the Relation type, and introducing the value 0.14 in the corresponding cell. If we leave the edition of the cell (by clicking a different element in the same window or by pressing Tab or Enter), the value in the bottom cell changes to 0.86, because the sum of the probabilities must be one (see Figure 1.2).
Figure 1.2: Conditional probability for the variable Disease.
The CPT for the variable Test is built by taking into account that the sensitivity (90%) is the probability of a positive test result when the disease is present, and the specificity (93%) is the probability of a negative test result when the disease is absent (see Figure 1.3):
Figure 1.3: Conditional probability for the variable Test.
A shortcut for opening the potential associated to a node (either a probability or a utility potential) is to alt-click on the node.
1.3 Inference
Click the Inference button ( ) to switch from edit mode to inference mode. As the option prop- agation is set to automatic by default, OpenMarkov will compute and display the prior probability of the value of each variable, both graphically (by means of horizontal bars) and numerically—see
Figure 1.4. Note that the Edit toolbar has been replaced by the Inference toolbar, whose buttons are described below.
Figure 1.4: Prior probabilities for the network BN-disease-test.pgmx.
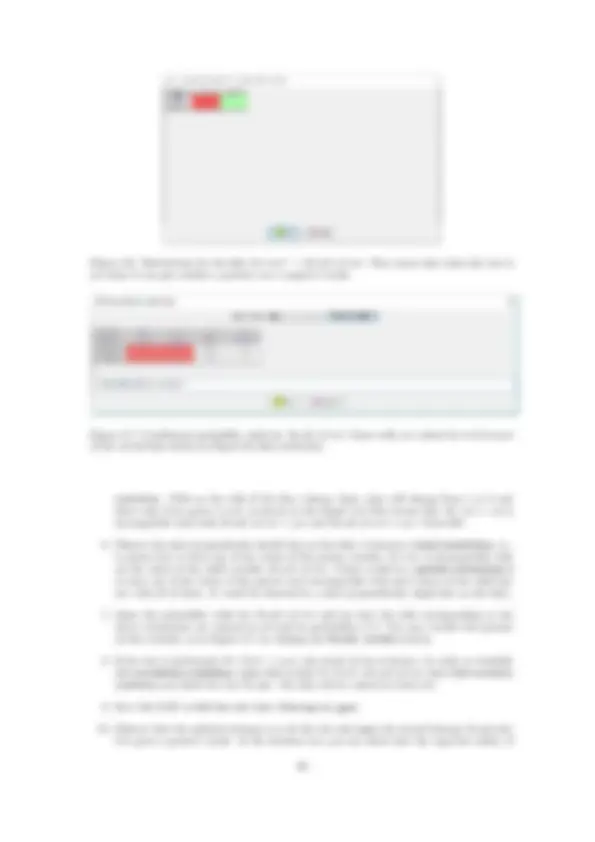
A finding consists of the assignment of a value to a variable as a consequence of an observation. A set of findings is called an evidence case. The probabilities conditioned on a set of findings are called posterior probabilities. For example, a finding may be the test has given a positive result: Test = positive. Intro- duce it by double-clicking on the state positive of the node Test (either on the string, or on the bar, or on the numerical value) and observe that the result is similar to Figure 1.5: the node Test is colored in gray to denote the existence of a finding and the probabilities of its states have changed to 1.0 and 0.0 respectively. The probabilities of the node Disease have changed as well, showing that P ( Disease = present | Test = positive ) = 0_._ 6767 and P ( Disease = absent | Test = positive ) = 0_._ 3233. Therefore we can answer the first question posed in Example 1.1: the positive predictive value (PPV) of the test is 67.67%. An alternative way to introduce a finding would be to right-click on the node and select the Add finding option of the contextual menu. A finding can be removed by double-clicking on the corresponding value or by using the contextual menu. It is also possible to introduce a new finding that replaces the old one.
In order to compute the negative predictive value (NPV) of the test, click on the icon Create a new evidence case ( ) and introduce the finding { Test = negative }. The result must be similar to that of Figure 1.6. We observe that the NPV is P ( Disease = absent | Test = negative ) = 0_._ 9828. In this example we have two evidence cases: { Test = positive } and { Test = negative }. The probability bars and the numeric values for the former are displayed in red and those for the second in blue.
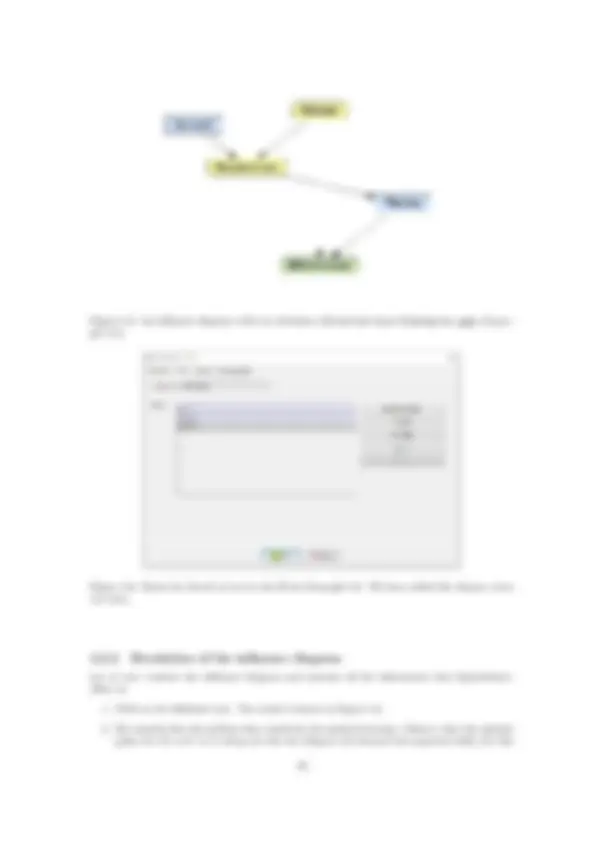
Figure 1.7: A network containing four nodes. The probability of E will be specified using a noisy OR model.
Figure 1.8: Canonical parameters of a noisy OR model.
shown in Figure 1.8. The value 0.95 means that the probability that A causes E when the other parents of E are absent is 95%. The value 0.01 means that the probability that the causes of E not explicit in the model (i.e., the causes different from A , B , and C ) produce E when the explicit causes are absent is 1%.
There are two main ways to build a Bayesian network. The first one is to do it manually , with the help of a domain expert, defining a set of variables that will be represented by nodes in the graph and drawing causal arcs between them, as explained in Section 1.2. The second method to build a Bayesian network is to do it automatically , learning the structure of the network (the directed graph) and its parameters (the conditional probabilities) from a dataset, as explained in Section 2.2. There is a third approach, interactive learning [4], in which an algorithm proposes some modifications of the network, called edits (typically, the addition or the removal of a link), which can be accepted or rejected by the user based on their common sense, their expert knowledge or just their preferences; additionally, the user can modify the network at any moment using the graphical user interface and then resume the learning process with the edits suggested by the learning algorithm. It is also possible to use a model network as the departure point of any learning algorithm, or just to indicate the positions of the nodes in the network learned, or to impose some links, etc. This approach is explained in Section 2.3. When learning any type of model, it is always wise to gain insight about the dataset by inspecting it visually. The networks used in this chapter are in the format Comma Separated Values (CSV). They can be opened with a text editor, but this way it is very difficult to see the values of the variables. A better alternative is to use a spreadsheet, such as OpenOffice Calc or LibreOffice Calc. In some regional configurations, Microsoft Excel does not open these files properly because it assumes that in .csv files the values are separated by semicolons, because the comma is used as the decimal separator; a workaround to this problem is to open the file with a text editor, replace the commas with semicolons, save it with a different name, and open it with Microsoft Excel.
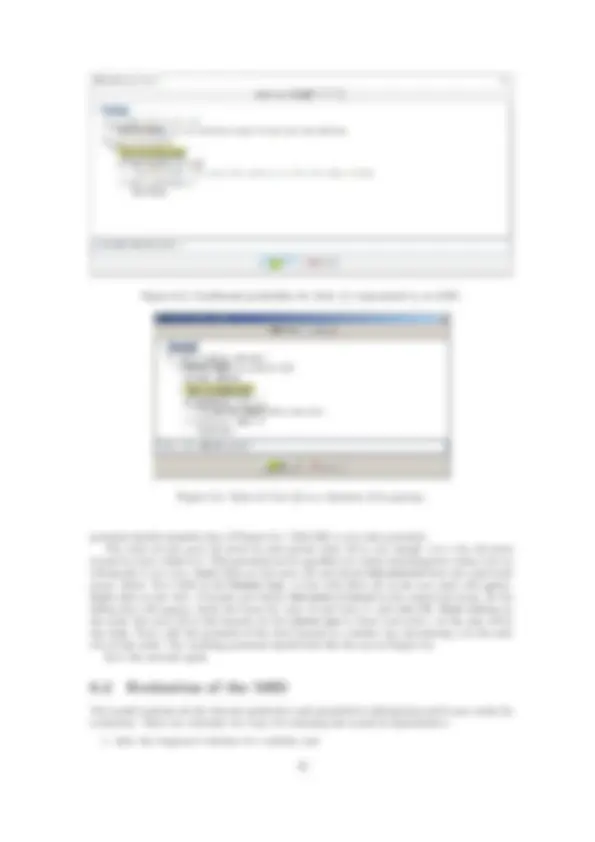
In this first example we will learn the Asia network [26] with the hill climbing algorithm, also known as search-and-score [19]. As a dataset we will use the file asia10K.csv, which contains 10,000 cases randomly generated from the Bayesian network BN-asia.pgmx (Figure 2.1).
Figure 2.3: Network Asia learned automatically.
For those who are familiar with the Asia network as presented in the literature [26], it would be convenient to place the nodes of the network learned in the same positions as in Figure 2.1 to see more easily which links differ from those in the original network. One possibility is to drag the nodes after the network has been learned. Another possibility is to make OpenMarkov place the nodes as in the original network; the process is as follows:
The network learned has the same links as in Figure 2.3, but the nodes are in the same positions as in Figure 2.1. The facility for positioning the nodes as in the model network is very useful even when we do not have a network from which the data has been generated: if we wish to learn several networks from the same dataset—for example by using different learning algorithms or different parameters—we drag the nodes of the first network learned to the positions that are more intuitive for us and then use it as a model for learning the other networks; this way all of them will have their nodes in the same positions.
In OpenMarkov there are three options for preprocessing the dataset:
In this example we will illustrate the first two options; the third one is explained in Section 2.2.4.
Figure 2.4: Selection and discretization of variables.