¡Descarga PARA INFORME NUMERO 14 y más Apuntes en PDF de Biología Celular solo en Docsity!
FACULTAD DE CIENCIAS DE LA SALUD
ESCUELA ACADÉMICO PROFESIONAL DE MEDICINA
HUMANA
Biología Celular y Molecular Pràctica
ACTIVIDAD N° 13
Título de la Actividad : CODIGO GENÈTICO
Apellidos y nombres:
Bañez Benites, Cinthia Catherine
Nina Flores Yessenia Vanessa
Pahuachón Huayta Fiorella
Ciclo: I
Sección: MD1T
Docente: Esqueche Ángeles Carlos
2022
PRÁCTICA Nº 13
CÓDIGO GENÉTICO
I. MARCO TEÓRICO
La información genética en los seres vivos está contenida en el ADN (ácido desoxirribonucleico), bajo la forma de genes, que codifica la síntesis de un ARN y/o de una proteína. Cada gen es una secuencia de nucleótidos, que a su vez contienen ácidos nucleicos, los cuales son el depósito de información de todas las secuencias de aminoácidos de todas las proteínas de la célula. Cada nucleótido del ADN puede presentar una de 4 bases nitrogenadas: adenina (A), guanina (G), citosina (C) y timina (T); en el caso delARN (ácido ribonucleico), las bases son las mismas, con excepción de timina, que es sustituida por uracilo (U). Las proteínas que se conocen están formadas únicamente por 20 aminoácidos diferentes, llamados aminoácidos proteicos o canónicos (Se conocen otros 150 aa que no forman parte de las proteínas). Existe una correlación entre ambas secuencias: a una secuencia de 3 nucleótidos (codón) en el ARN corresponde 1 aminoácido en una proteína. La descripción de esta correlación es lo que se denomina CÓDIGO GENÉTICO. Este código es universal y se encuentra conservado en todos los organismos vivos (con pocas excepciones) FIG. 1. CÓDIGO GENÉTICO
UACCCCCGGGGCAACACACCU CGAUGAGUCAUAUCA U A C A C UUUUUUU a) El número de aminoácidos = 48 AMINOÀCIDOS b) El número de codones que dió origen al polipéptido = 16 codones c) El número de nucleótidos del ARNm que originó el polipéptido = 48 d) El número de ARNt que se utilizó para la síntesis del polipéptido = 15 e) El codón de terminación. = CAU PROCEDIMIENTO ACTIVIDAD 1 ARNm3´ Codón de terminación ARNm5´ Codón de INICIO HIS
ACTIVIDAD 2:
Dada la siguiente secuencia de nucleótidos de un segmento de ADN que se traduce a un polipéptido de seis aminoácidos y empleando el código genético: ADN 3’ T A C G A T A A T G G C C C T T T T A T C 5’ ADN 5’ A T G C T A T T A C C G G G A A A A T A G 3’ a) Deduzca la secuencia de ribonucleotidos en el ARN mensajer b) Escriba la secuencia de aminoácidos del polipéptidoproducto
PROCEDIMIENTO
Actividad 4. Si parte de la secuencia del ARN mensajero que será utilizado para sintetizar una proteína es AUG CCG ACG GAA ¿Cuál debe ser la secuencia del molde del ADN que le dio origen? a) 5´ UAC – GGC – UGC - CUU 3´ b) 5´ TAC – GGC – TGC – CTT 3´ c) 3´ UAC – GGC – UGC - CUU 5´ d) 3´ ATC – GGC – AGC – CAA 5´ e) 3´ TAC – GGC – TGC – CTT 5´
VI. CUESTIONARIO
1. Investigue qué es el genoma humano, cuántos genes contiene, y
cuántas proteínas codifican.
¿QUÈ ES EL GENOMA HUMANO?
Aunque el verdadero origen de la palabra “genoma” es conocido, hay quien piensa que procede de la contracciòn de dos tèrmino: “gen” (o genotipo) y “cromosomas”. El cromosoma es cada una de las estructuras microscòpicas en que se encuentran alojados los genes, presentes en la mayorìa de las cèlulas. El gen, aunque los continuos descubrimientos modifican constantemente su signifcado mpas amplio, puede definirse como la “unidad hereditaria”, es decir, el menor fragmento de material hereditario”, es decir, el menor fragmento de matterial hereditario que puede trnasmitir informaciòn a travès de sus constituyentes bioquìmicos. Una forma màs simple de definir el genoma es la de “gene`s home”, el lugar donde viven los genes. Casi todas las cèlulas humanas poseen dos genomas diferentes. El màs pequeñoo està localizado en unas organelas productoras de energìa, las mitocondrias. Su informaciòn se transmite de una generaciòn a la siguiente a trvès del òvulo femenino, por lo que puede utilizarse para conocer las lìneas femeninas (y sòlo femeninas) de descendenca en la
proporciona la explicaciòn a la similitud biològica que existe entre todos los hombres, e incluso entre todos los seres vivos, y tanto en el momento actual como a lo largo de toda la Historia. Las moficifaciones genèticas, o mutaciones, pueden darse tanto en las regiones no codificantes de ADN, que con frecuencia estàn compuestas por fragmentos de bases repetidas en muchas veces, como en la codificanttes. Los conjunto de los genes y sus interacciones. Es decir, que mientras la genètica se refiere a un ùnico gen, oa un pequeño grupo de genes, genòmica hace referencia a un anàlisis comprensible de còmo el conjunto de genes interactùa para determinar el fenotipo. Sìntesis del ARN y las proteìnas Al principio de los años cuarente, los genetistas demostraron que los genes determinan la estructura de las distintas preteìnas. La transferencia de informaciòn del ADN a las proteìnas depende de la sìntesis de una molècula intermedia, denominada Arn. El ARN, lo mismo que el ADN, està formado por una secuencia lineal de nucleòtidos compuestos por cuatro bases complementarias. El ARN se diferencia del ADN en dos aspectos: Su esqueleto de azùcar-fosfato contiene como azùcar ribosa en lugar de desoxirribosa. La timina (T) es sustituida por el uracilo (U), una base muy parecida que se empareja con la adenina (A). Las molèculas de ARN se sintetizan a partir del ADN mediante un proceso conocido como transcripcion del ADN, para el que se emplea una de las hebras de ADN a modo de plantilla. La transcripcion del ADN se diferencia de la replicaciòn por el hecho de que el ARN se sintetiza como una molècula de una sola hebra y es relativamente màs corto que el ADN. Se ontienen varias clases de transcripciòn de ARN: ARNm, ARNt y ARNr. Aunque todas estas molèculas de ARN intervienen en la traducciòn de la informaciòn del ARN a las proteìnas, solo el ARNm actùa como plantilla. La sìntesis del ARN es un proceso muy selectivo, y solo el 1% de toda la secuencia de nucleòtidos del ADN humano se transcribe a secuencias funcionales de ARN. Aunque todas las cèlulas contienen el mismo material genètico, solo se transcriben determinados genes. La transcripcion del ARN està controladas por proteìnas reguladoras que se unen a puntos especìficos del ADN cercanos a la secuencia de codificaciòn de un gen. Esta regulaciòn tan compleja de la transcripcion de los genes se produce durante el desarrollo de expresion genètica. Tras la transcripcion se procesa el ARNm para su transporte fuera del nùcleo. Un importante es el acoplamiento del ARN, que elimina las secuencias no codificadoras o intrones. Una vez que llega al citoplasma, el ARN dirige la sìntesis de una determinada proteìna mediante un proceso denominado traducciòn del ARN. Las secuencias de nucleòtidos del ARN se traducen en las secuencias de aminoàcidos de una proteìna. Cada trìo de nucleòtidos forma un codòn que especifica un aminoàcido. Dado que el ARN està formado por cuatro tipos de nucleòtidos, existen 64 trìos de codones posibles (4x4x4). Sin embargo, en las proteìnas solo se encuentran normalmente 20 aminoàcidos, del modo que la mayorìa de los aminoàcidos estàn codificados por varios codones. Se conoce como còdigo genètico la regla por la que los diferentes codones se traducen en los aminoàcidos. Para la traducciòn proteìna se necesitan los ribosomas, que estàn constituidos por màs de 50 proteìnas diferentes y varios ARNr. Los ribosomas se unen a una molècula de ARNm por el codòn de inicio (AUG) y comienzan a traducir en la direcciòn de 5´- 3´. La sìntesis proteìna cesa cuando se encuentra uno de los tres codones de interrupciòn. La velocidad de la sìntesis proteìnica està controlada por unos factores de iniciaciòn que responden a factores externos,
como el factor de crecimiento y los nutrientes. Estos factores reguladores ayudan a coordinar el crecimiento y la proliferaciòn de la cèlula.
2. ¿Por qué se producen las mutaciones genéticas?
Las principales causas de las mutaciones que se producen de forma natural o
normal en las poblaciones son tres:
- Errores durante la replicación.
- Lesiones o daños fortuitos en el ADN.
- Los elementos genéticos transponibles.
ERRORES EN LA REPLICACIÓN
Vamos a considerar tres tipos de errores durante la replicación del ADN:
La tautomería: las bases nitrogenadas se encuentran habitualmente en su
forma cetónica y con menos frecuencia aparecen en su forma tautomérica
enólica o imino. Las formas tautoméricas o enólicas de las bases nitrogenadas
(A, T, G* y C) muestran relaciones de apareamiento distintas: A-C, T*-G,
G-T y C-A. El cambio de la forma normal cetónica a la forma enólica produce
transiciones. Los errores en el Apareamiento incorrecto de las bases
nitrogenadas pueden ser detectados por la función correctora de pruebas del
ADN polimerasa III.
Las mutaciones de cambio de fase o pauta de lectura: se trata de inserciones o
deleciones de uno o muy pocos nucleótidos. Según un modelo propuesto por
Streisinger,estas mutaciones se producen con frecuencia en regiones con
secuencias repetidas. En las regiones con secuencias repetidas, por ejemplo,
AAAAAAAAAAA..., o, por ejemplo, ATATATATATATATAT...., durante la
replicación se puede producir el deslizamiento de una de las dos hélices (la
hélice molde o la de nueva síntesis) dando lugar a lo que se llama el
"apareamiento erróneo deslizado". El deslizamiento de la hélice de nueva
síntesis da lugar a una adición, mientras que el deslizamiento de la hélice
molde origina una deleción. En el gen lac I (gen estructural de la proteína
represora) de E. coli se han encontrado puntos calientes (regiones en las que
la mutación es muy frecuente) que coinciden con secuencias repetidas: un
ejemplo es el punto caliente CTGG CTGG CTGG.
Deleciones y duplicaciones grandes: las deleciones y duplicaciones de
regiones relativamente grandes también se han detectado con bastante
frecuencia en regiones con secuencias repetidas. En el gen lac I de E. coli se
han detectado deleciones grandes que tienen lugar entre secuencias repetidas.
Se cree que estas mutaciones podrían producirse por un sistema semejante al
propuesto por Streisinger ("Apareamiento erróneo deslizado") o bien por
sobrecruzamiento desigual. Del sobrecruzamiento desigual hablaremos más
adelante en el curso.
ELEMENTOS GENÉTICOS TRANSPONIBLES
Los elementos genéticos transponibles son secuencias de ADN que tienen la
propiedad de cambiar de posición dentro del genoma, por tal causa también
reciben el nombre de elementos genéticos móviles. Por tanto, cuando cambian
de posición y abandonan el lugar en el que estaban, en ese sitio, se produce un
deleción o pérdida de bases. Si el elemento transponible estaba insertado en el
interior de un gen, puede que se recupere la función de dicho gen. De igual
forma, si el elemento genético móvil al cambiar de posición se inserta dentro de
un gen se produce una adición de una gran cantidad de nucleótidos que tendrá
como consecuencia la pérdida de la función de dicho gen. Por consiguiente, los
elementos genéticos transponibles producen mutaciones.
3. ¿Qué antibióticos producen inhibición de las síntesis de proteínas?
¿Cuál es el fundamento?
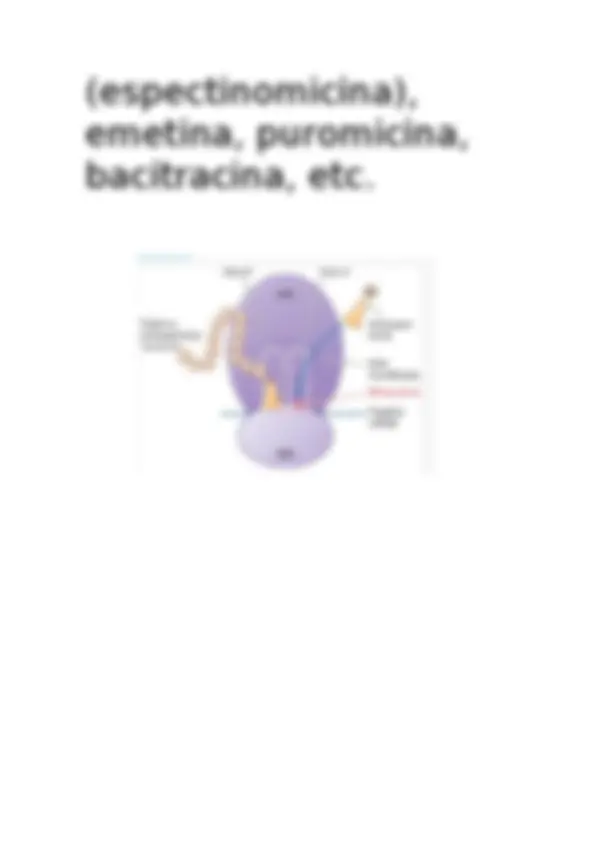
Las tetraciclinas y glicilciclinas inhiben la síntesis bacteriana de proteínas al
unirse con el ribosoma 30S bacteriano e impedir el acceso del aminoacil tRNA
al sitio aceptor (A) en el complejo-mRNA-ribosoma. Estos fármacos entran a
las bacterias gramnegativas por difusión pasiva a través de los conductos
formados por las porinas en la membrana celular externa y por transporte
activo que bombea a las tetraciclinas a través de la membrana citoplásmica.
Inhibición de la síntesis proteínica bacteriana por las tetraciclinas. El mRNA se
une con la subunidad 30S del RNA ribosómico bacteriano.
El sitio P (peptídico) de la subunidad de RNA ribosómica 50S contiene la
cadena poli peptídica naciente; en condiciones normales, el aminoacil tRNA
cargado con el siguiente aminoácido (aa) que se agrega se mueve al sitio A
(aceptor), con emparejamiento de bases complementarias entre la secuencia
de anti codón de tRNA y la secuencia de codón del mRNA. Las tetraciclinas se
unen con la subunidad 30S, bloquean la unión de tRNA con el sitio A y, por
tanto, inhiben la síntesis de proteína.
Algunos antibióticos
que producen
inhibición de síntesis
de proteínas son:
las tetraciclinas;
dentro de las
cuales encontramos,
clortetraciclina,
demeclociclina,
oxitetraciclina; entre
otras, otros
antiobióticos que
inhiben
(espectinomicina),
emetina, puromicina,
bacitracina, etc.
Algunos antibióticos
que producen
inhibición de síntesis
de proteínas son:
las tetraciclinas;
dentro de las
cuales encontramos,
clortetraciclina,
demeclociclina,
oxitetraciclina; entre
otras, otros
antiobióticos que
inhiben
la síntesis de
proteínas son;
glicilciclinas,
cloranfenicol,
macrólidos y
cetólidos,
lincosamidas
(clindamicina),
estreptograminas
(quinupristina/
dalfopristina),
oxazolidinonas
(linezolida) y
aminociclitoles
VII. FUENTES DE INFORMACIÓN
1. LODISH, H. F., ZIPURSKY, S. L. y DARNELL, J. E.: Biología Celular y
Molecular. 7a ed. Editorial Médica Panamericana. 2016.
2. https://www.youtube.com/watch?v=xD5s6W501y0 : Cómo utilizar las tablas
de código genético (bases y aminoácidos).
3. http://www.wwpdb.org/ : Worldwide Protein Data Bank
4. https://www.ncbi.nlm.nih.gov/genbank/ : GenBank
5. Educación YP, De LA, Silva CT, Contreras NC, Fonseca • Bogotá J, Resumen DC.
The utility of cytogenetics in modern medicine. Historical view and application [Internet]. Org.co. [citado el 18 de junio de 2022]. Disponible en: http://www.scielo.org.co/pdf/amc/v33n4/v33n4a9.pdf
- Redalyc.org. [citado el 18 de junio de 2022]. Disponible en: https://www.redalyc.org/pdf/106/10637211.pdf