



ASIGNATURA : MÉTODOS ESTADÍSTICOS
CICLO : III
SEMESTRE ACADEMICO : 2020-0















Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
clases de metodos estadisticos
Tipo: Transcripciones
1 / 26

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
UNIVERSIDAD PRIVADA SAN JUAN BAUTISTA FACULTAD DE CIENCIAS DE LA SALUD ESCUELA PROFESIONAL DE MEDICINA HUMANA “Dr. Wilfredo Erwin Gardini Tuesta” ACREDITADA POR SINEACE RE ACREDITADA INTERNACIONALMENTE POR RIEV
DOCENTE RESPONSABLE DE LA ASIGNATURA VERA NUÑEZ, GRISELDA GLADYS
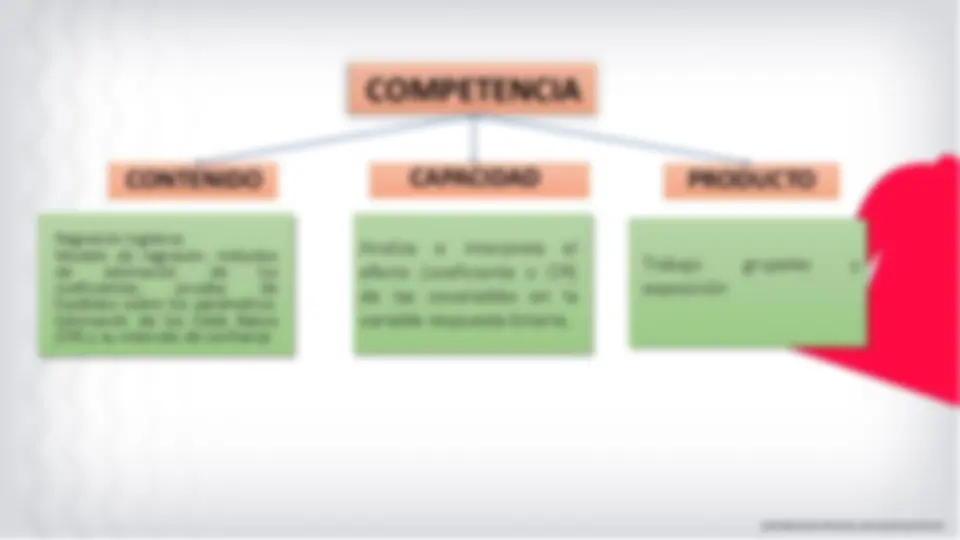
La regresión logística es el conjunto de modelos estadísticos utilizados cuando se desea conocer la relación entre:
González-Revaldería, Fernández, García, & Queraltó (2007) y A. Field, Miles, & Field (2012).
Por otra parte nos interesa estudiar la relación entre una o más variables independientes o explicativas: X 1 , X 2 , ..., Xp y la variable Y. El modelo logístico establece la siguiente relación entre la probabilidad de que ocurra el suceso, dado que el individuo presenta los valores X 1 =x 1 , X 2 =x 2 ,...,Xp=xp:
EJEMPLOS DE USOS DE LA REGRESIÓN LOGÍSTICA ESTUDIOS DESCRIPTIVOS: La regresión logística puede utilizarse como método descriptivo cuando se desea estudiar desde una perspectiva epidemiológica la aparición de un determinado evento en un grupo de individuos, por ejemplo: - los pacientes de una determinada enfermedad desarrollan un cierto signo propio de ésta. - los niños dejan la lactancia materna exclusiva. - el fallecimiento de individuos de una cohorte. EJEMPLO: Se seleccionan al azar n ( 300 ) historias clínicas de enfermos de la patología en estudio, se determina la fecha de detección de la enfermedad td, si el paciente tiene el signo de interés se toma la fecha en que apareció ts, si el paciente no tiene el signo se toma la fecha de la última consulta te. Con estos datos definimos la variable dependiente Y como 1 si el paciente no tiene el signo, y como 0 si lo tiene, y la variable independiente t como la diferencia en días de la fecha de aparición.
EJEMPLO Se desea conocer la probabilidad de que un paciente que se ingresa en una sala de terapia intensiva sobreviva. Para este tipo de estudios es recomendable la definición de grupos diagnósticos (conjunto de entidades o enfermedades que tienen en común afectar a un mismo sistema del organismo), por tanto en nuestro ejemplo nos limitaremos a algunas de las variables que puedan influir el pronóstico de la evolución de pacientes con Enfermedades del Sistema Cardiocirculatorio (ESCC): Edad (años) X 1 Enfermedad Hipertensiva (S/N) X 2 Insuficiencia Cardiaca (S/N) X 3 Disrritmia (S/N) X 4 Infarto Agudo del Miocardio (S/N) X 5 Enfermedad Pulmonar Obstructiva Crónica y afecciones afines (S/N) X 6 Ingresos anteriores por estas causas (#) X 7
Se estudiarán entonces un grupo de pacientes que ingresen a la sala de terapia intensiva con diagnóstico de ESCC, se les medirán las variables anteriores, que definiremos como 1 si hay presencia del problema y como 0 si no. Se espera entonces al egreso de cada paciente, si egresa vivo la variable Y toma valor 1 , en caso contrario toma valor 0. La matriz de los datos de este estudio puede ser, por ejemplo:
Consideremos dos factores de exposición X 1 y X 2 (variables dicotómicas) podemos definir el riesgo Rij=Pr( D= 1 | X 1 =i, X 2 =j ) para los distintos niveles de exposición a X 1 y X 2 , y calcular el OR para cada uno de estos niveles por: La hipótesis nula de no interacción bajo un modelo multiplicativo es: H 0 :OR 11 =OR 10 OR 01 , que puede contrastarse utilizando el siguiente modelo de regresión logística:
Se quiere establecer una relación entre el hecho de tener anticuerpos a determinado virus con la zona de residencia (norte, sur, este y oeste) y el factor RH. Para ello, se da la siguiente estructura: variable nominal Virus ( 1 ‐Si, 0 ‐No), variable nominal Zona ( 1 ‐ Norte, 2 ‐Sur, 3 ‐Este y 4 ‐Oeste), variable nominal RH ( 1 ‐Positivo, 2 ‐Negativo) y la variable escalar Frecuencia. Señalar que la variable nominal Zona tiene cuatro categorías y debería ser sustituida por 3 variables dummy:
Se selecciona la variable dependiente (Virus) y las covariables (variables independientes: Zona y RH). Ahora tenemos que indicarle al SPSS las variables categóricas, se pulsa el botón [Categóricas].
Se elige el Método Introducir (procedimiento en el que todas las variables de un bloque se introducen en un solo paso). Se podía haber utilizado el Método Adelante RV (método automático por pasos, hacia delante, que utiliza la prueba de la Razón de Verosimilitud para comprobar las covariables a incluir o excluir), en este modelo se habría anulado la variable RH de la ecuación.
Análisis estadístico bivariado
Análisis estadístico multivariado Resumen del modelo