¡Descarga SQL DB desde Principiante a Avanzado y más Guías, Proyectos, Investigaciones en PDF de Programación Web y Tecnologías solo en Docsity!
UNIVERSIDAD AUTONOMA DEL ESTADO DE
MEXICO
CU. TEXCOCO
Elaboración de apuntes de:
BASE DE DATOS y SQL Avanzado
PRESENTA:
Dra. Alma Delia Cuevas Rasgado
Texcoco, Estado de México. Febrero de 2015
Resumen
Se presenta un compendio de los temas que forman la materia Fundamentos de Base de datos para las Licenciaturas: Ing. en Computación e Informática Administrativa, así como una parte de Base de Datos Avanzadas de la Ing. en Computación de la Licenciatura en Informática impartida en la Universidad Autónoma del Estado de México, Centro Universitario Texcoco..
Las unidades de aprendizaje forman parte del conjunto de unidades básicas en la formación profesional en cómputo. Cada uno de los objetos de estudio que se desarrollan en este documento regularmente lleva el orden planteado en los temarios y que ha sido desarrollado específicamente para que los alumnos de la universidad satisfagan eficientemente las demandas de conocimiento de nuestros Estados en vías de desarrollo como lo es el Estado de México.
Se considera importante que al estudiar estos apuntes, el alumno tenga una idea de lo que son las Base de datos, el lenguaje SQL y el uso de, al menos, un manejador de base de datos relacional comercial. Por razones de escasez de tiempo en la elaboración de este documento, se presentan casos prácticos usando solo el manejador de base de datos SQL Server de Microsoft, con la firme intensión de que; en lo posterior, se presente una mejora con casos aplicados a varios manejadores con la finalidad de estudiar el comportamiento de las instrucciones en otras herramientas. Por lo tanto, se deduce que en ese sentido, este trabajo no pretende ser completo pero si apoyar en un importante grado al conocimiento de herramientas avanzadas, para que el alumno pueda aplicarlos a las nuevas tecnologías emergentes de base de datos.
Índice
- Álgebra relacional
- 1.1. Introducción al Álgebra Relacional
- 1.2. Las operaciones básicas del Álgebra relacional
- 1.3. El conjunto de operaciones de la teoría matemática de conjuntos
- 1.3.1. Unión
- 1.3.2. Intersección
- 1.3.3. Diferencia.
- 1.3.4. Producto
- 1.4. Las operaciones creadas específicamente para bases de datos relacionales
- 1.4.1. Selección o Restricción
- 1.4.2. Proyección
- 1.4.3. Reunión
- 1.4.4. División
- 1.5. Secuencia de operaciones y cambio de nombre de los atributos
- 1.6. Conjunto completo de operaciones del álgebra relacional
- 1.7. Operaciones de cerradura recursiva
- 1.8. Funciones agregadas
- 1.9. Otras operaciones adicionales
- 1.9.1. Ampliación
- 1.9.2. Resumen
- 1.9.3. División generalizada
- 1.9.4. Reunión externa
- 1.9.5. Unión externa
- 1.10. Operaciones quizá.........................................................................................
- 1.11. Asignación relacional
- 1.12. Ejemplos de consultas en el álgebra relacional
- El lenguaje Sql
- 2.1. Estructura general de las consultas en SQL
- 2.2. Combinación de tablas
- 2.3. Predicados IN, IS NULL, BETWEEN, AND, OR, NOT, LIKE
- 2.4. Cláusulas ORDER BY, GROUP BY
- 2.5. Funciones agregadas COUNT, SUM, MAX, MIN, AVG
- 2.6. Subconsultas
- …………………………………………………………………………………... 2.7. Operadores IN, EXIST, ANY, ALL aplicados a subconsultas de renglón múltiple
- 2.8. Cláusula HAVING (CON)
- 2.9. Combinaciones externas: OUTER JOIN, UNION JOIN
- 2.10. El valor NULL
- Vistas
- 3.1. Definición
- 3.2. La opción WITH CHECK OPTION
- 3.3. Operaciones DML sobre las vistas
- 3.4. Funcionamiento de las vistas
- 3.5. Utilización de las vistas
- 3.6. Actualización de vistas
- Disparadores
- 4.1. Definición
- 4.2. Estado de los desencadenadores
- 4.3. Tipos de desencadenadores
- 4.3.1. AFTER
- 4.3.2. INSTEAD OF
- 4.3.3. For each row, statement ...............................................................................
- 4.3.4. IF UPDATE.................................................................................................
- 4.4. Grupos de desencadenadores ...........................................................................
- 4.4.1. Desencadenador de inserción .......................................................................
- 4.4.2. Desencadenador de actualización .................................................................
- 4.4.3. Desencadenador de eliminación ...................................................................
- 4.5. Desencadenadores anidados .............................................................................
- 4.6. Desencadenadores recursivos...........................................................................
- 4.7. Implementación de desencadenadores..............................................................
- 4.8. Usos, ventajas y desventajas ............................................................................
- Procedimientos almacenados ...................................................................................
- 5.1. Definición .......................................................................................................
- 5.2. Algoritmo de ejecución ....................................................................................
- 5.3. Usos ................................................................................................................
- 5.4. Ventajas ..........................................................................................................
- 5.5. Desventajas .....................................................................................................
- Anexo A .........................................................................................................................
- Anexo B.........................................................................................................................
- Anexo C.........................................................................................................................
- Anexo D .........................................................................................................................
- Bibliografía .....................................................................................................................
¿Para qué sirve el algebra relacional?
El objetivo principal del álgebra relacional no sólo es la obtención de datos. La intención fundamental del álgebra es ayudar a escribir expresiones. A su vez, la intención de esas expresiones es coadyuvar a diversos propósitos , entre los que está incluida desde luego la obtención de datos , pero de ninguna manera están limitados a esa única función. La siguiente lista indica algunas posibles aplicaciones de tales expresiones (en esencia, por supuesto, tales expresiones representan relaciones y esas relaciones a su vez definen el alcance de las operaciones de recuperación, actualización, etc. presentadas en la lista).
- definir el alcance de una recuperación ; es decir, definir los datos que se van a extraer como resultado de una recuperación.
- definir el alcance de una actualización ; es decir, definir los datos por insertar, modificar o eliminar como resultado de una operación de actualización
- definir datos virtuales ; es decir, definir los datos que se podrán ver en forma de relación virtual o vista
- definir datos de instantánea ; es decir, definir los datos que se han de mantener en forma de una relación tipo “instantánea”
- definir derechos de acceso ; es decir, definir los datos incluidos en algún tipo de autorización concedida.
- definir requerimientos de estabilidad ; es decir, definir los datos que abarcará alguna operación de control de concurrencia.
- definir restricciones de integridad ; es decir, definir alguna regla específica que debe satisfacer la BD, además de las reglas generales (o metarreglas) que son parte del modelo relacional y se aplican a todas las BD.
En general, la realidad es que las expresiones constituyen una representación simbólica de alto nivel de la intención del usuario (con respecto a una consulta determinada, por ejemplo) y precisamente porque son de alto nivel y simbólicas se pueden manipular de acuerdo con varias reglas de transformación simbólicas de alto nivel. Por ejemplo, la expresión:
( ( S JOIN SP ) WHERE P# = ‘P2’ ) [ SNOMBRE ]
(“nombres de los proveedores que suministran la parte 2”) puede transformarse en una expresión equivalente en cuanto a la lógica pero con toda probabilidad más eficiente:
( S JOIN ( SP WHERE P# = ‘P2’ ) ) [ SNOMBRE ]
Por lo tanto, el algebra constituye una base conveniente para la optimización ; es decir, aunque el usuario exprese la consulta empleando la primera de las dos expresiones anteriores, el optimizador deberá convertirla en la segunda antes de ejecutarla (el desempeño de una consulta dada no deberá depender de la forma en la cual la exprese el usuario).
El álgebra se utiliza a menudo como patrón de referencia para medir la capacidad expresiva de un determinado lenguaje relacional (por ejemplo, SQL). En esencia, se dice que un lenguaje es relacionalmente completo si es tan expresivo como el álgebra, cuando menos; es decir, si sus expresiones permiten la definición de cualquier relación que pueda definirse mediante expresiones del álgebra.
1.2. Las operaciones básicas del Álgebra relacional
El Álgebra relacional consta de operaciones que le dan al usuario la libertad de realizar peticiones de recuperación básicos de datos. Como resultado de esta recuperación es una nueva relación que se forma a partir de una o más relaciones, mismas que se pueden volver a manipular para obtener otras relaciones y así sucesivamente.
Las operaciones del Álgebra relacional se clasifican en dos grupos:
- el conjunto de operaciones de la teoría matemática de conjuntos y
- las operaciones creadas específicamente para bases de datos relacionales
1.3. El conjunto de operaciones de la teoría matemática de
conjuntos
Las operaciones que normalmente se aplican a los conjuntos son: Unión , Intersección, Diferencia y Producto. En este apartado se definirán cada uno de ellos.
1.3.1. Unión
Construye una relación formada por todas las tuplas que aparecen en cualquiera de las dos relaciones especificadas.
La unión de dos relaciones A y B compatibles respecto a la unión, A UNION B, es una relación cuya cabecera es idéntica a la de A o B y cuyo cuerpo está formado por todas las tuplas t pertenecientes ya sea a A o a B (o a las dos).
La operación de unión permite combinar datos de varias relaciones. Supongamos que una determinada empresa internacional posee una tabla de empleados para cada uno de los países en los que opera. Para conseguir un listado completo de todos los empleados de la empresa tenemos que realizar una unión de todas las tablas de empleados de todos los países.
No siempre es posible realizar consultas de unión entre varias tablas, para poder realizar esta operación es necesario e imprescindible que las tablas a unir tengan las mismas estructuras, que sus campos sean iguales.
Ejemplo: Sean A y B las relaciones presentadas en la figura 3 (A contiene en términos intuitivos, los proveedores de Londres y B contiene los proveedores que suministran la parte P1). Entonces A UNION B consistirá en los proveedores que o bien están situados en Londres, o que suministran la parte P1 (o las dos cosas). Adviértase que el resultado tiene tres tuplas, no cuatro (se eliminan las tuplas repetidas).
1.3.3. Diferencia.
Construye una relación formada por todas las tuplas de la primera relación que no aparezcan en la segunda de las dos relaciones especificadas.
La operación diferencia permite identificar filas que están en una relación y no en otra. Tomando como referencia el caso anterior, deberíamos aplicar una diferencia entre la tabla empleados y la tabla asistentes al curso para saber aquellos asistentes externos a la organización que han asistido al curso.
La diferencia entre dos relaciones compatibles respecto a la unión A y B, A MINUS B, es una relación cuya cabecera es idéntica a la de A o B y cuyo cuerpo está formado por todas las tuplas t pertenecientes a A pero no a B.
Ejemplo: Sean A y B las relaciones presentadas en la figura 5 (A contiene en términos intuitivos, los proveedores de Londres y B contiene los proveedores que suministran la parte P1). Entonces A MINUS B consistirá en los proveedores que están en A y no en B. Mientras que B MINUS A consistirá en los proveedores que están en B y no en A.
Figura 5 Ejemplo de diferencia
1.3.4. Producto
A partir de dos relaciones especificadas, construye una relación que contiene todas las combinaciones posibles de tuplas, una de cada una de las dos relaciones.
La operación producto consiste en la realización de un producto cartesiano entre dos tablas dando como resultado todas las posibles combinaciones entre los registros de la primera y los registros de la segunda. Esta operación se entiende mejor con el siguiente ejemplo:
Figura 6 Ejemplo del producto
Producto cartesiano ampliado
En matemáticas, el producto cartesiano de dos conjuntos es el conjunto de todos los pares ordenados de elementos tales que el primer elemento de cada par pertenece al primer conjunto y el segundo elemento de cada par pertenece al segundo conjunto. Así, el producto cartesiano de dos relaciones sería un conjunto de pares ordenados de tuplas. Pero (una vez más) deseamos conservar la propiedad de cerradura; en otras palabras deseamos un resultado compuesto de tuplas, no de pares ordenados de tuplas (aquí también empleamos términos un poco informales). Por lo tanto, la versión del producto cartesiano en álgebra relacional es una forma ampliada de la operación, en la cual cada par ordenado de tuplas es reemplazado por la tupla resultante de la combinación de las dos tuplas en cuestión. Aquí “combinación” significa en esencia unión (en el sentido de la teoría de conjuntos, no del álgebra relacional); es decir, dadas las dos tuplas
(A1:a1, A2:a2,…, Am:am) y (B1:b1, B2:b2,…,Bn:bn)
(se muestran los nombres de los atributos para hacerlas más explícitas), la combinación de las dos es la tupla única
(A1:a1, A2:a2,…,Am:am, B1:b1, B2:b2,…, Bn:bn)
Un problema que surge en conexión con el producto cartesiano es la necesidad de una cabecera bien formada para la relación resultante. Ahora bien, es evidente que la cabecera del resultado es en esencia sólo la combinación de las cabeceras de las dos relaciones de entrada. Por tanto, se presentará un problema si esas dos cabeceras tienen algún nombre de atributo en común. Así pues, si necesitamos formar el producto cartesiano de dos relaciones cuyas cabeceras tienen nombres de atributo común, debemos emplear antes el operador RENAME (renombrar) para modificar de manera apropiada los nombres de los atributos. Entonces diremos que dos relaciones son compatibles respecto al producto si y solo si sus cabeceras son disjuntas (es decir, no tienen nombres de atributo en común).
Por lo tanto, definimos el producto cartesiano de dos relaciones (compatibles respecto al producto) A y B, A TIMES B, como una relación cuya cabecera es la combinación de las cabeceras de A y B y cuyo cuerpo está formado por el conjunto de todas las tuplas de t tales que t es la combinación de una tupla de a perteneciente a A y una tupla b perteneciente a B.
Ejemplo: Sean A y B las relaciones presentadas en la figura 7 (A, en términos intuitivos, consiste en todos los números de proveedores vigentes y B en todos los números de parte vigentes). Entonces A TIMES B estará formada por todas las combinaciones de número de proveedor/número de partes vigentes.
Sea theta la representación de cualquier operador de comparación escalar simple (por ejemplo =, <>, >, >=, etc). La restricción theta de la relación A según los atributos X y Y. A WHERE X theta Y es una relación con la misma cabecera que A y con un cuerpo formado por el conjunto de todas las tuplas t de A tales que la evaluación de la comparación X theta Y resulta verdadera en el caso de esa tupla t. (los atributos X y Y deben estar definidos sobre el mismo dominio y la operación theta debe ser aplicable a ese dominio. Además, por supuesto, la relación A no debe ser por fuerza una relación nombrada y puede representarse mediante una expresión arbitraria del álgebra relacional).
Se puede especificar un valor literal en vez del atributo X o del atributo Y (o de ambos, desde luego); de hecho, esto es lo más común en la práctica. Por ejemplo:
A WHERE X theta literal
Adviértase que el operador de restricción theta produce en realidad un subconjunto “horizontal” de una relación dada; es decir, el subconjunto de las tuplas de la relación dada para las cuales se satisface una comparación especificada. Se acostumbra abreviar “restricción theta” a sólo “restricción”.
La operación de restricción tal como se acaba de definir permite sólo una comparación simple en la cláusula WHERE; sin embargo es posible ampliar la definición que esté formada por una combinación booleana arbitraria de tales comparaciones simples, según se indica con las siguientes equivalencias:
- A WHERE C1 AND C2 se define como equivalente a (A WHERE C1) INTERSECT (A WHERE C2)
- A WHERE C1 OR C2 se define como equivalente a (A WHERE C1) UNION (A WHERE C2)
- A WHERE NOT C se define como equivalente a A MINUS(A WHERE C )
La operación selección con restricciones consiste en recuperar un conjunto de registros de una tabla o de una relación indicando las restricciones que deben cumplir los registros recuperados, de tal forma que los registros devueltos por la selección han de satisfacer todas las condiciones que se hayan establecido. Esta operación es la que normalmente se conoce como consulta.
Se puede emplearla para saber que empleados son mayores de 45 años, o cuales viven en Madrid, incluso podemos averiguar los que son mayores de 45 años y residen en Madrid, los que son mayores de 45 años y no viven en Madrid, etc..
En este tipo de consulta se emplean los diferentes operadores de comparación (=,>, <, >=, <=, <>), los operadores lógicos (and, or, xor) o la negación lógica (not).
La expresión condicional en la cláusula WHERE de una restricción está formada por este tipo de combinaciones booleanas arbitrarias de comparaciones simples. Una expresión condicional como ésta se conoce como condición de restricción.
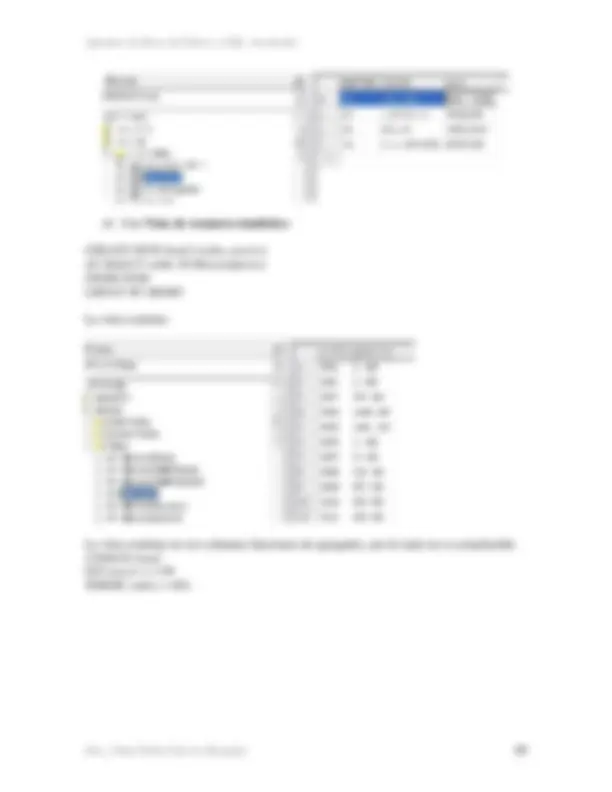
En la figura 8 se presentan algunos ejemplos de restricción.
Figura 8 Ejemplos de restricción
1.4.2. Proyección
Extrae los atributos especificados de una relación dada. Si se piensa en una relación como una tabla, la operación Selección restringe ciertas filas de una tabla y desecha las demás, mientras la Proyección selecciona ciertas columnas de la tabla desechando las restantes.
El Símbolo que denota esta operación es: π su representación general es:
π (^) (RELACIÓN O TABLA).
El resultado de una operación Proyección contiene únicamente los atributos especificados en y en el mismo orden en que aparecen en la lista.
La proyección de la relación A según los atributos X, Y, …,Z
A [X, Y, … ,Z] es una relación con (X, Y, … Z) como cabecera y cuyo cuerpo está formado por el conjunto de todas las tuplas (X:x, Y:y, …, Z:z) tales que una tupla t aparece en A con el valor x en X, el valor y en Y,… y el valor z en Z. Así, el operador de proyección produce un subconjunto “vertical” de una relación dada; o sea, el subconjunto obtenido mediante la selección de los atributos especificados y la eliminación de las tuplas repetidas dentro de los atributos seleccionados, la relación A tampoco necesita ser una relación renombrada y puede representarse mediante una expresión arbitraria.
Una proyección es un caso concreto de la operación selección, esta última devuelve todos los campos de aquellos registros que cumplen la condición establecida. Una proyección es una selección en la que seleccionamos aquellos campos que deseamos recuperar. Tomando como referencia el caso de la operación selección es posible que lo único que nos interese recuperar sea el número de la seguridad social, omitiendo así los campos teléfono, dirección, etc.. Este último caso, en el que seleccionamos los campos que deseamos, es una proyección.
La figura 9 presenta algunos ejemplos de proyección. Obsérvese en el inciso a (la proyección de proveedores según el atributo CIUDAD) que, aunque la relación S tiene cinco tuplas y por tanto cinco ciudades, sólo hay tres ciudades en el resultado; como ya se explicó, las tuplas repetidas se eliminan (como siempre). Desde luego, lo mismo puede decirse también de los otros ejemplos.
Sean las cabeceras (X1, X2, …, Xm, Y1, Y2, …, Yn) y (Y1, Y2, …,Yn, Z1, Z2,…,Zp) respectivamente; es decir, los atributos Y1, Y2,…,Yn son (los únicos) comunes a las dos relaciones, los atributos X1, X2,…,Xm son los demás atributos de A, y los atributos Z1, Z2,…Zp son los demás atributos de B. Vamos a suponer también que los atributos correspondientes (es decir, los atributos con el mismo nombre) están definidos sobre el mismo dominio. Consideremos ahora (X1, X2,…,Xm), (Y1, Y2,…,Yn) y (Z1, Z2,…,Zp) como tres atributos compuestos X, Y y Z, respectivamente. La reunión natural de A y B A JOIN B es una relación con la cabecera (X, Y, Z) y un cuerpo formado por el conjunto de todas las tuplas (x:X, y:Y, z:Z) tales que una tupla a aparezca en A con el valor x en X y el valor y en Y, y una tupla b aparezca en B con el valor y en Y y el valor z en Z. Como siempre, las relaciones A y B pueden estar representadas por expresiones arbitrarias.
La reunión natural, es tanto asociativa como conmutativa.
(A JOIN B) JOIN C y A JOIN (B JOIN C) se pueden simplificar, sin provocar ambigüedad, además las dos expresiones equivalentes A JOIN B y B JOIN A son equivalentes.
Cabe señalar que, si A y B no tienen nombres de atributos en común, A JOIN B es equivalente a A * B (es decir, la reunión natural degenera en el producto cartesiano, en este caso).
En la figura 10 se presenta un ejemplo de reunión natural (la reunión natural S JOIN P, según el atributo común CIUDAD).
Figura 10. Ejemplo de reunión natural
Reunión theta
Es adecuada para aquellas ocasiones (poco frecuentes en comparación, pero de ninguna manera desconocida) en las cuales necesitamos juntar dos relaciones con base en alguna condición diferente a la igualdad. Sean las relaciones A y B compatibles respecto al producto (o sea, no tienen nombres de atributos en común) y sea theta un operador según la definición dada en el análisis de la restricción. La reunión theta de la reunión A según el atributo X con la relación B según el atributo Y se define como el resultado de evaluar la expresión (A TIMES B) WHERE X theta Y
En otras palabras, es una relación con la misma cabecera que el producto cartesiano de A y B, y con el cuerpo formado por el conjunto de todas las tuplas t tales que t pertenece a ese producto cartesiano y la evaluación de la condición “X theta Y” resulta verdadera para esa tupla t. (Los atributos X y Y deberán estar definidos sobre el mismo dominio, y la operación theta debe ser aplicable a ese dominio).
Vamos a suponer, por ejemplo que deseamos calcular la “reunión mayor que de la relación S según CIUDAD con la relación P según CIUDAD”. Una expresión apropiada del álgebra relacional es:
((S RENAME CIUDAD AS SCIUDAD) * (P RENAME CIUDAD AS PCIUDAD)) WHERE SCIUDAD > PCIUDAD La figura 11 presenta el resultado.
Figura 11 Ejemplo de la reunión-theta
Sería suficiente renombrar sólo uno de los dos atributos CIUDAD; la única razón para cambiar el nombre de los dos es la simetría.
La reunión-theta no es una operación primitiva; siempre es equivalente a obtener el producto cartesiano ampliado de las dos relaciones (con modificaciones apropiadas de los
Figura 13 Tabla B
Si dividimos la tabla B entre la tabla A obtendremos como resultado una tercera tabla presentada en la figura 14 que: Los campos que contiene son aquellos de la tabla B que no existen en la tabla A. En este caso el campo Código Comercial es el único de la tabla B que no existe en la tabla A. Un registro se encuentra en la tabla resultado si y sólo si está asociado en tabla B con cada fila de la tabla A
Figura 14 Tabla Resultado
¿Por qué el resultado es 23?. El comercial 23 es el único de la tabla B que tiene asociados todos los posibles códigos de producto de la tabla A.
Asociatividad.
Es fácil comprobar que la unión es asociativa; es decir, si A B y C son “proyecciones” arbitrarias, entonces las expresiones:
(A UNION B) UNION C y A UNION (B UNION C) son equivalentes.
Así, por comodidad, nos permitiremos escribir una secuencia de unión sin insertar paréntesis; por ejemplo, cualquiera de las dos expresiones anteriores puede simplificarse a: A UNION B UNION C sin provocar ambigüedad.
Algo análogo podría decirse de la intersección y el producto (pero no de la diferencia). Señalamos también que la unión, la intersección y el producto (pero no la diferencia) son conmutativas, es decir, las expresiones AUNION B y B UNION A son equivalentes también y lo mismo sucede con INTERSECT y *.
1.5. Secuencia de operaciones y cambio de nombre de los
atributos
Una relación tiene dos partes importantes: una cabecera y un cuerpo ; la cabecera es el conjunto de nombres de atributos y el cuerpo consiste en los datos , hablando en términos informales. Ahora bien, toda relación nombrada (es decir, toda relación – relación base, vista, etcétera- incluida de manera explícita en la definición de la BD) tendrá desde luego
una cabecera con todas las de la ley; pero, ¿Qué hay de las relaciones no nombradas (o sea, resultantes)?
Es importante que una relación resultante tenga un conjunto apropiado de nombres de atributos porque, desde luego, esa relación podría ser el resultado de una expresión anidada dentro de otra más grande y obviamente necesitaremos alguna forma de referirnos a los atributos del resultado de la expresión interior desde esa expresión exterior. Si desea un análisis más a fondo de este punto, recomendamos al lector consultar el artículo de Warden “The naming of columns” (bautizo de columnas) incluido en la referencia [Andrew Warden 1990].
Por lo tanto, nuestra versión del álgebra relacional se definirá de manera tal que garantice cabeceras apropiadas para todas las relaciones; es decir, cabeceras en las cuales cada atributo tenga un nombre propio no calificado y único dentro de la relación que lo contiene.
La operación de renombrar se identifica como RENAME o en otras fuentes como: R() y para asignarle un nombre inicial a una relación como: ←
Citaremos el nuevo operador, RENAME (renombrar), cuyo propósito es en esencia cambiar el nombre de los atributos dentro de una relación. En términos más precisos, el operador RENAME toma una relación especificada y – al menos en lo conceptual- crea una copia nueva de esa relación en la cual se ha dado un nombre diferente a uno de los atributos (la relación especificada podría ser, desde luego, el resultado de una expresión e incluir otras operaciones algebraicas) por ejemplo, podríamos escribir:
S RENAME CIUDAD AS SCIUDAD
El resultado de evaluar esta expresión es una relación – la cual por cierto no tiene nombre propio- con el mismo cuerpo que la relación S pero en la cual el atributo de ciudad se llama SCIUDAD en vez de CIUDAD. Los demás nombres de atributos se heredan sin modificaciones de sus contrapartes en la relación S.
Se pueden escribir las operaciones en una sola expresión del álgebra relacional anidándolas, o bien aplicar una operación cada vez y crear relaciones de resultados intermedios. En el segundo caso, se tendrán que renombrar las relaciones que contienen los resultados intermedios. Por ejemplo si se quiere obtener el nombre, el apellido y el salario de todos los empleados que trabajan en el departamento número 5, se deberá aplicar una operación SELECCIONAR y una operación PROYECTAR. Se puede escribir una sola expresión del álgebra relacional, de la siguiente forma:
ΠNOMBRE, APELLIDO, SALARIO(σND=5(EMPLEADO))
Como otra alternativa, se puede mostrar explícitamente la secuencia de operaciones, dando un nombre a cada una de las relaciones intermedias, como sigue:
EMPS_DEP5←σND=5(EMPLEADO) RESULTADO←πNOMBRE, APELLIDO, SALARIO(EMPS_DEP5)