









Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
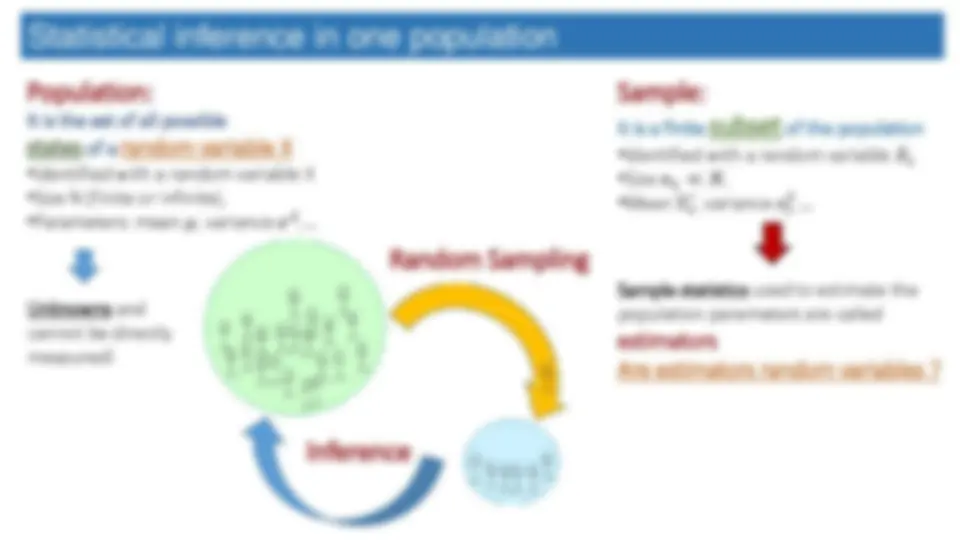
El tema de la inferencia estadística en una población, donde se discute el proceso de pasar de una población a muestras aleatorias y cómo inferir sobre parámetros poblacionales mediante estimadores. Se abordan conceptos como el tamaño de la muestra, el estimador de media muestral y su distribución de muestreo, los estimadores point y sus propiedades, la desviación estándar de un estimador y la unbiasness y eficiencia de los mismos.
Tipo: Apuntes
1 / 13

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Edoardo MENGA [email protected]
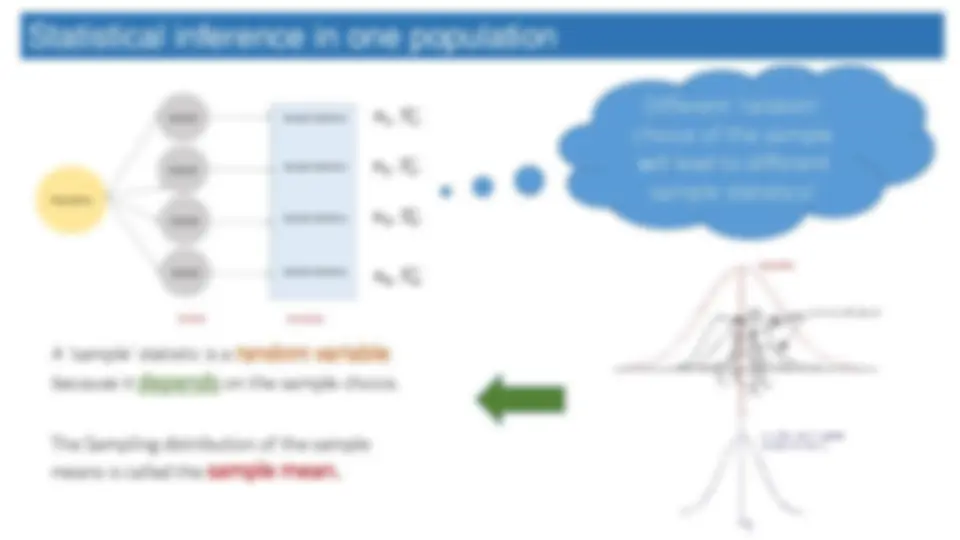
A ‘sample’ statistic is a random variable because it depends on the sample choice. Different ‘random’ choice of the sample will lead to different sample statistics! 𝑛 1 , 𝑥 1 , 𝑛 2 , 𝑥 2 , 𝑛 3 , 𝑥 3 , 𝑛 4 , 𝑥 4 , The Sampling distribution of the sample means is called the sample mean.
The sample mean is a random variable, it can be used as a point estimator of the population mean. A specific value of an estimator is called an estimate (it is a single number!). 𝐸 𝑋 = 𝐸( 1 𝑛 1 𝑛 𝑋𝑖) = 𝐸(𝑋) The expected value of the sample mean is the population mean The variance of the sample mean is the population variance reduced by a factor n 𝑉𝑎𝑟 𝑋 = 𝑉𝑎𝑟( 1 𝑛 1 𝑛 𝑋𝑖) = 1 𝑛
What are Point Estimators? Point estimators are functions that are used to find an approximate value of a population parameter from random samples of the population. They use the sample data of a population to calculate a point estimate or a statistic that serves as the best estimate of an unknown parameter of a population. 𝜽 Unbiasedness (^) 𝑏𝑖𝑎𝑠 𝜽 = 𝐸(𝜽) - 𝜽 A point estimator is said to be an unbiased estimator of a population parameter ϴ if its expected value is equal to that parameter. Efficiency The unbiased estimator with the smallest variance is called the most efficient estimator (minimum variance unbiased estimator) 𝑟𝑒𝑙. 𝑒𝑓𝑓. 𝜽𝟏, 𝜽𝟐 =
𝟐 ] = 𝑉𝑎𝑟( 𝜽)+[𝑏𝑖𝑎𝑠 𝜽 ] 2
Sum n terms of an arithmetic series