¡Descarga Programación orientada a objetos en Python: clases, objetos, herencia y archivos y más Apuntes en PDF de Algoritmos y Programación solo en Docsity!
Lenguaje de programación: Python
Por: José Gerardo Carrillo González
- TUTORIAL
- Números pseudoaleatorios Contenido:
- Flotantes
- Enteros.....................................................................................................................................................
- Generar un objeto de una secuencia
- Generar números de acuerdo con una distribución
- Clases
- Imprimir en pantalla
- Archivos
- Manipular archivos
- Lectura y escritura de datos con formato
- Ejemplos para practicar..............................................................................................................................
- Referencias
Números pseudoaleatorios Podemos generar números pseudoaleatorios importando el módulo random.
Flotantes
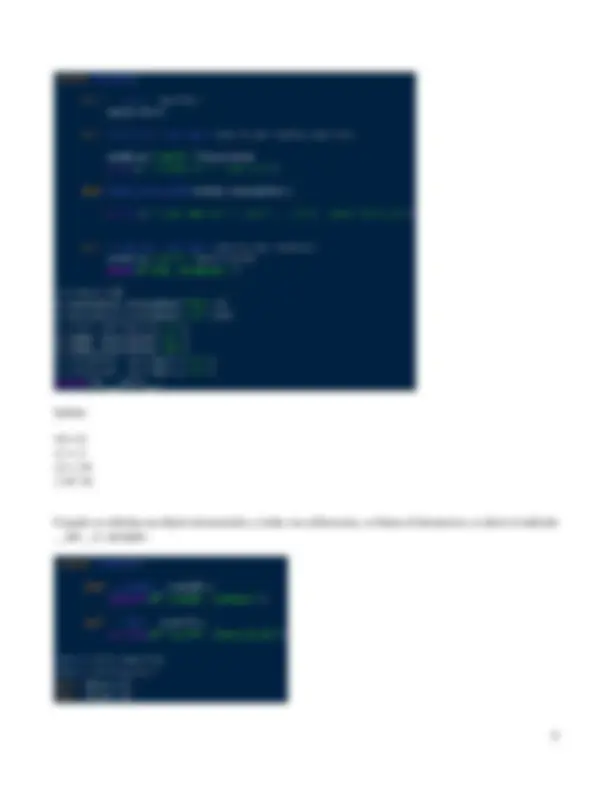
Con la función random.random() se puede generar un número aleatorio de clase 'float' en el rango semiabierto por la derecha [0.0, 1.0). Ejemplo: import random n=random.random() print(n) Salida:
Por lo que 0.0<=n<1.0. Con random.uniform(a,b) se puede generar un número aleatorio de clase 'float' en el rango [a,b]. Ejemplo: n=random.uniform(0,1) Salida:
Enteros
Para generar números enteros tenemos random.randrange( a, b, incremento ), a y b corresponden al rango en el cual puede estar el numero generado, que es [ a, b ), además incremento es para que el número generado sea múltiplo de incremento. Los valores a, b , e incremento deben ser enteros. Por defecto, a = e incremento =1. Ejemplo: n=random.randrange(0,10,2) Salida: 8 En este caso n puede ser un número del conjunto {0,2,4,6,8}. Con random.randint( a,b ), el numero generado puede estar en el rango [ a,b ].
Generar un objeto de una secuencia
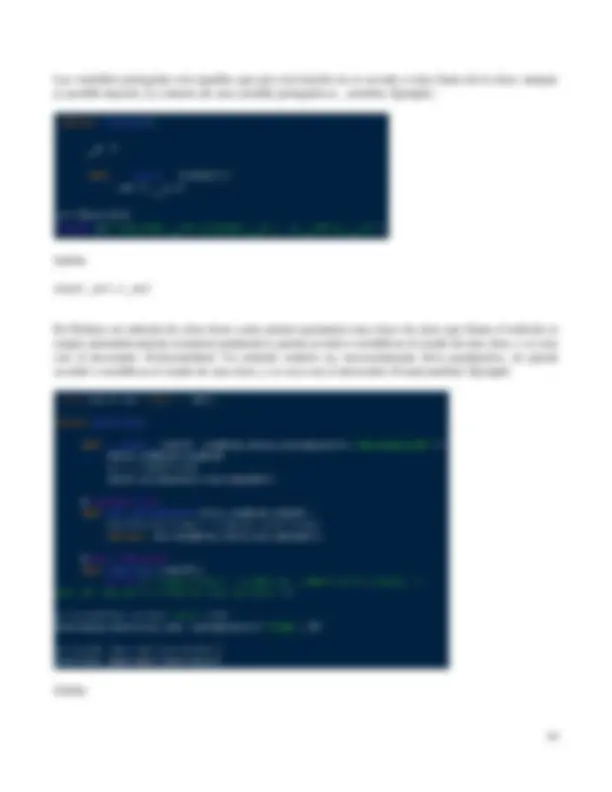
Con random.choice( secuencia ), se obtiene un objeto de secuencia , siendo secuencia una coleccion de objetos. Ejemplo: n=random.choice([1,2,3]) Salida: 3
Con random.expovariate(lambda) se obtiene un flotante aleatorio con distribución exponencial. Condición: lambda != 0. Salida: si lambda>0, el resultado es un valor en el rango de 0 a infinito positivo, si lambda<0, el resultado es un valor en el rango de 0 al infinito negativo. Con random.gammavariate(alpha, beta) se obtiene un flotante aleatorio con distribución gamma. Condición: alpha>0 y beta>0. Con random.lognormvariate(mu, sigma) se obtiene un flotante aleatorio con distribución log normal. La media es mu y la desviación estándar es sigma. Condición: sigma>0. Con random.weibullvariate(alpha, beta) se obtiene un flotante aleatorio con distribución Weibull. Donde alpha es el parámetro de escala y beta es el parámetro de forma. Con random.paretovariate(alpha) se obtiene un flotante aleatorio con distribución Pareto. Donde alpha es el parámetro de forma. Con random.normalvariate(mu, sigma) se obtiene un flotante aleatorio con distribución normal. Donde mu es la media y sigma la desviación estándar. Ejemplo:
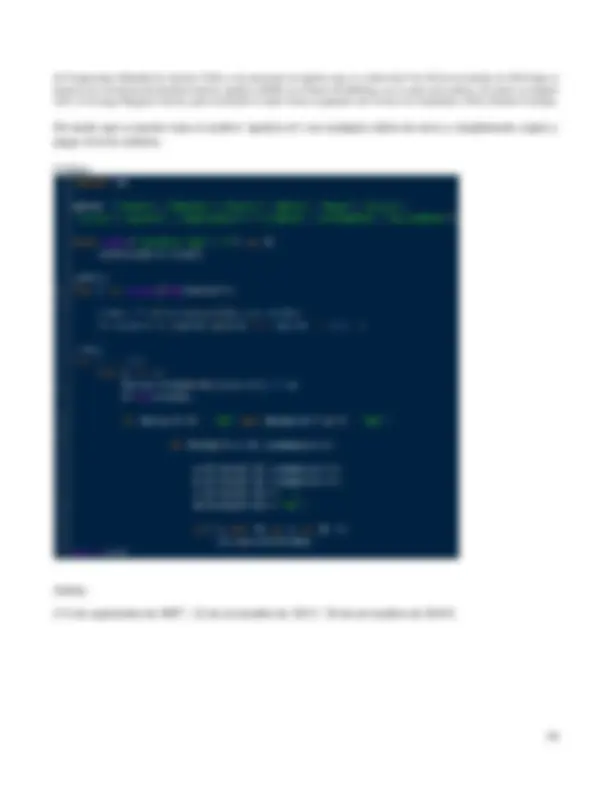
Para instalar matplotlib, desde command prompt escribir: pip install matplotlib Para instalar scipy, desde command prompt escribir: pip install scipy La función dist_norm tiene 4 parámetros: mu=media, sigma=desviación estándar, p1=cantidad de números aleatorios a generar, p2=número de bins (intervalos del eje-x). En la línea 11 tenemos: n=random.normalvariate(mu,sigma), que es la instrucción para generar un número flotante aleatorio con distribución normal [1] de acuerdo con los valores mu y sigma. Ya que el while (línea 10) hará p1 = iteraciones, la lista data tendrá 100 números. Línea 15 es para determinar si los datos (en data ) vienen de una distribución normal (o distribución de Gauss), para lo cual se usó la prueba Shapiro-Wilk [2]. Si el p- value ( p ) es mayor que alpha= 5%, es decir p>0.05 , entonces no se puede rechazar la hipótesis de que los datos vienen de una distribución normal. Líneas 29 y 30 son las instrucciones para graficar el histograma [3]. En la Figura 1 tenemos el eje-x dividido en p2 = 10 intervalos, cada intervalo (igual al ancho del bin) corresponde en el eje-y con la cantidad de números generados que están dentro de dicho intervalo. Se puede determinar el ancho del bin ( ancho ) conociendo el valor mínimo ( mi ) y máximo ( ma ) en data, de modo que ancho=(ma-mi)/p2. Salida: Figura 1. Los datos generados vienen de una distribución normal, ya que: p-value = 0.9284147024154663 > 0. El ancho del bin es: (max-min)/intervalos = (93.9250949471864-56.065771164232075)/10 = 3. Regla 68.27, 95.45, 99.73 resulto en: 67.0, 97.0, 100.
Salida: Nueva instancia creada x.c = 1, x1.c = 1 Nueva instancia creada x.c = 2, x2.c = 2 En init() estan las instrucciones que se ejecutaran cuando un objeto de una clase es instanciado, por lo que es útil para inicializar la instancia. Se pueden definir atributos de la instancia en el constructor, de modo que pueden tener valores por defecto, o también se les puede asignar valor cuando se instancia el objeto. Los atributos de una instancia se pueden crear, eliminar, leer y escribir. Entonces, cuando se crea una instancia se llama el método init, los parámetros de este método corresponden con los argumentos que van a la derecha del nombre de la clase (separados por comas y entre paréntesis) que se indican cuando la instancia es creada. Ejemplo: Salida: nombre: sin nombre, edad: sin edad nombre: He-man, edad: 35 nombre: She-ra, edad: 33
Entonces, los atributos de clase son los definidos directamente en la clase y que comparten las instancias de la clase. Los atributos de instancia son los que se definen en el constructor y en los métodos, y son particulares para cada instancia. Por convención el primer parámetro de un método es llamado self y hace referencia a la instancia que llama el método. Ejemplo: Salida: Yo soy He-man, tengo 35 años. Para eliminar un atributo, instancia o clase, usaremos del. De acuerdo con el ejemplo anterior, para borrar un atributo, una instancia y una clase, escribimos: del p0.nombre del p del persona Es posible escribir, leer y eliminar atributos de instancia mediante métodos. Ejemplo:
Salida: <main.clase1 object at 0x0000023EEDCDDDB0> creado <main.clase1 object at 0x0000023EEDCDDDB0> destruido Una clase, llamada “parent” o “base”, le puede heredar los atributos y métodos que contiene a una clase llamada “child” o “sub”. La clase que hereda puede heredar de una o más clases, si la clase sub hereda solo de una clase se conoce como herencia única, si hereda de dos o más clases se conoce como herencia múltiple. La sintaxis es la siguiente: class base 1 : bloque de código class base 2 : bloque de código class sub(base1,base 2 ): bloque de código Ejemplo: Salida: Perímetro = 31.416, área = 78.
En el siguiente ejemplo se puede observar que el método init () de clase3 tiene parámetros con valores ya definidos, por lo que cuando se crea una instancia de clase3 se puede hacer sin especificar el valor de estos parámetros. Salida: a=1, b=2, c=3, d= La clase sub puede tener un método con el mismo nombre que la clase base, sin embargo, el método de la clase sub tiene más precedencia y anula el método de la clase base. Esto aplica para una clase sub que viene heredando atributos y métodos de una o más clases. Ejemplo:
x.a=1, x.b=2, x.c=3, x.d= Las variables de una clase se pueden hacer privadas, de modo que la clase sub no puede acceder a variables privadas de la clase base. Para hacer una variable o método privado, que se conoce como “data mangling” en inglés, se escriben dos guiones bajos antes del nombre. Ejemplo: Salida: 1 Traceback (most recent call last): File "C:\Users\user\Dropbox\Materias\Codigos\dar_clase.py", line 214, in print(y.__b) AttributeError: 'clase2' object has no attribute '__b' Las variables y métodos privados se pueden usar dentro de la clase donde están definidos. Ejemplo: Salida: a=1, b= Método privado
Las variables protegidas son aquellas que por convención no se accede a estas fuera de la clase, aunque es posible hacerlo. La sintaxis de una variable protegida es: _nombre. Ejemplo: Salida: clase1._a=1, x._a= En Python, un método de clase tiene como primer parámetro una clase (la clase que llama el método se asigna automáticamente al primer parámetro), puede acceder o modificar el estado de una clase, y se crea con el decorador @classmethod. Un método estático no necesariamente lleva parámetros, no puede acceder o modificar el estado de una clase, y se crea con el decorador @staticmethod. Ejemplo: Salida:
Salida en pantalla: El automóvil es marca Toyota, modelo Corolla, del año 2009. Otra manera de combinar texto y valores es con cadenas con formato (formatted string literals). Se pone una f fuera de las comillas, y entre llaves los nombres de los objetos. Ejemplo: Salida en pantalla: Este año trabaje 330 días y descanse 35 días Ya que f-string es una expresión que se evalúa en tiempo de ejecución, esto nos permite hacer operaciones dentro de la llave, o incluso mandar llamar una función. Ejemplo: Salida en pantalla: El resultado es 18 El resultado es 18 Para imprimir en pantalla, se puede poner un 'str' en varias líneas de la siguiente manera: Salida en pantalla: El automóvil es marca Toyota. Modelo Corolla. Del año 2009. De manera opcional se puede escoger un especificador de formato. Con {n1:.3f} redondeamos n1 a tres decimales después del punto. Ejemplo: Salida: pi redondeado a tres decimales es 3. Con { nombre:x }, el espacio en pantalla donde aparecerá nombre tendrá un número mínimo de posiciones igual a x , si la longitud del objeto es mayor que x entonces se extiende a dicha longitud el número de
posiciones. Para alinear a la izquierda, derecha, o al centro, se hace con <, >, o ^, respectivamente. Ejemplo: Salida: Archivos Se usan principalmente dos tipos de archivos en programación. Tenemos archivos de texto, que contienen caracteres ASCII o UNICODE (UTF-8). En un archivo de texto cada línea termina con \n, que es para finalizar la línea y continuar en la siguiente. Y tenemos archivos binarios, que contienen datos para ser leídos por la computadora. En un archivo binario no hay líneas, por lo que no hay final de línea. La aplicación que lea el archivo binario interpreta el contenido de este. Para escribir en un archivo lo primero será abrir el archivo, para lo cual usaremos la función open(), de modo que: f = open("nombre_archivo", "modo_acceso", encoding='cp1252') Tenemos que f es el identificador del archivo, que lo usaremos para escribir (o leer). El primer argumento es el nombre del archivo (se puede incluir la ruta donde se encuentra de no estar en el directorio donde está el módulo). El segundo argumento define el modo en que se abrirá el archivo, y por lo tanto lo que se puede hacer con este. El valor predeterminado es 'r' (solo lectura), por lo que este argumento es opcional. El tercer argumento (opcional) es para definir el tipo de codificación (es recomendable definir este argumento cuando se trabaja en un archivo de texto), que es encoding='cp1252' en Windows, y encoding='utf-8' en Linux. Python guarda un archivo de texto en el disco en forma de bytes, de modo que para leerlo se decodifica en cadenas y para guardarlo se codifica. A continuación, los modos de acceso para definir el argumento "modo_acceso": 'r' – Para leer, es el modo predeterminado. El offset (la posición del cursor) se coloca al inicio. 'w' – Para escribir. Si el archivo no existe, se crea. Si había un archivo con el mismo nombre es reemplazado. 'x' – Igual que 'w' pero el archivo creado no debe existir sino hasta ese momento, caso contrario da error. 'a' – Abre el archivo para escribir respetando el contenido anterior. Si no existe un archivo con el nombre indicado, se crea. El cursor se coloca al final del archivo. Los modos se pueden combinar con las siguientes letras:
Linea numero cuatro. Con read(n) se hace lectura. Si n es negativo o no se pone, se lee todo el archivo. Si es positivo se leerán n posiciones a partir de la posición del cursor. Si ya se ha leído todo el contenido del archivo y se usa read(), este regresa un 'str' sin contenido. Para leer texto1.txt: Cuya salida es el contenido en texto1.txt. Con el modo 'a+' se pone el cursor al final de la última línea y se puede leer y escribir. Con seek(x) cambiamos la posición del cursor, de modo que nos desplazamos x posiciones desde el inicio en la posición 0. De acuerdo con el contenido en texto1.txt, con seek( 19 ) nos posicionamos al principio del segundo renglón. Además, con f.read(1 7 ) se lee el contenido de 17 posiciones. Y la salida es: Linea numero dos. Para leer la tercer palabra del primer renglón lo podemos hacer así: Con f.seek(13) nos colocamos en la posición 13 a partir del principio, y con f.read(3) indicamos leer lo que está en las siguientes tres posiciones, por lo que f.read(3)= 'uno'. Además, con la función tell() podemos saber la posición actual. Ya que con f.seek(13) nos colocamos en la posición 13 e hicimos la lectura de 3 caracteres, ahora el cursor está en la posición 13+3=16, que es lo que nos entrega f.tell()=16. Con la función writelines(['cadena_1', 'cadena_2', 'cadena_3']) podemos escribir el contenido de una lista (que contiene cadenas) en un archivo. Ejemplo:
Y la salida es lo que contiene texto2.txt. Para cerrar un archivo usamos close(), esto lo hacemos para liberar los recursos del sistema que se están usando por tener el archivo abierto. De no cerrar el archivo, el recolector de basura de Python eventualmente cerrará el archivo. Esto sucede de acuerdo con la implementación de Python. Otra manera de abrir y cerrar un archivo es: Con la sentencia with (línea 69) abrimos el archivo texto3.txt en modo ‘w’, siendo f el identificador del archivo. Después viene un bloque de instrucciones indentado (línea 7 0 a 77). Con el identificador f podemos acceder a atributos como f.closed, que regresa True si el archivo está cerrado, y False en caso contrario, f.mode regresa el modo de acceso al archivo, y f.name regresa el nombre del archivo. Entonces la salida es: False w texto3.txt True En la línea 75 tenemos que f.closed = False, ya que dentro del bloque indentado el estado de f es abierto. En la línea 79 tenemos f.closed=True, ya que esta instrucción ya no es parte del bloque indentado el estado de f es cerrado. Una manera para acceder renglón por renglón al contenido de un archivo es: Que resulta: Linea numero uno. Linea numero dos. Linea numero tres. Con readline() accedemos al primer renglón, si volvemos a poner esta instrucción accedemos al siguiente, y así sucesivamente. Si ponemos readline(n), leeremos el contenido de las siguientes n posiciones del renglón donde se encuentre el cursor, sin pasar a leer el contenido del siguiente renglón. Ejemplo: