Scarica Cluster analisys e più Appunti in PDF di Analisi Statistica solo su Docsity!
Capitolo
Cluster gerarchica
Questa procedura consente di identificare gruppi di casi relativamente omogenei in
base alle caratteristiche selezionate, utilizzando un algoritmo che inizia con ciascun
caso (o variabile) in un cluster distinto e che combina i cluster fino a quando ne
rimane solo uno. È possibile analizzare le variabili semplici oppure scegliere una
delle trasformazioni di standardizzazione disponibili. Le misure di similarità e
dissimilarità vengono generate dalla procedura Distanze. A ciascun livello verranno
visualizzate statistiche in base alle quali selezionare la soluzione migliore.
Esempio. Esistono gruppi di trasmissioni televisive identificabili che attraggono tipi di
audience analoghi all’interno di ciascun gruppo? Utilizzando la cluster gerarchica è
possibile raggruppare le trasmissioni televisive (casi) in gruppi omogenei in base alle
caratteristiche degli spettatori. Questo metodo può essere utilizzato per identificare i
segmenti di mercato. In alternativa, è possibile raggruppare le città (casi) in gruppi
omogenei in modo che da poter selezionare città con caratteristiche confrontabili per
verificare diverse strategie di mercato.
Statistiche. Programma di agglomerazione, matrice delle distanze (o similarità) e
cluster di appartenenza per un’unica soluzione o una serie di soluzioni. Grafici:
dendrogrammi e grafici a stalattite
Dati. Le variabili possono essere quantitative, binarie o dati di conteggio. Lo scaling
delle variabili è molto importante in quanto le differenze di scaling possono influire
sulle soluzioni dei cluster. Se lo scaling delle variabili presenta differenze notevoli
(ad esempio, una variabile viene misurata in dollari e l’altra in anni), è consigliabile
standardizzarle. Ciò può essere effettuato in modo automatico mediante la procedura
Cluster gerarchica.
Ordine dei casi. Se le distanze assegnate o le similarità sono presenti nei dati iniziali o
nei cluster aggiornati durante l’unione, la soluzione del cluster risultante può essere
influenzata dall’ordine dei casi del file. Può essere utile ottenere più soluzioni diverse
Capitolo 33
con casi disposti in ordini casuali diversi per verificare la stabilità di una soluzione
specifica.
Assunzioni. Le misure di dissimilarità o di similarità utilizzate devono essere idonee
per i dati analizzati. Per ulteriori informazioni sulla scelta delle misure di dissimilarità
e similarità, vedere la procedura Distanze. È inoltre necessario includere nell’analisi
tutte le variabili significative. L’omissione di variabili importanti può portare a
soluzioni improprie. Poiché la cluster gerarchica rappresenta un metodo esplorativo, i
risultati devono essere considerati provvisori finché non vengano confermati da un
campione indipendente.
Figura 33-
Output della cluster gerarchica
1 1 1 2 ,1 1 2 0 0 2 6 1 1 ,1 3 2 0 1 4 7 9 ,1 8 5 0 0 5 6 8 ,2 2 7 2 0 7 7 1 0 ,2 7 4 3 0 7 1 3 ,4 2 3 0 0 1 0 6 7 ,4 3 8 4 5 1 4 1 3 1 4 ,4 8 4 0 0 1 5 2 5 ,5 4 7 0 0 1 1 1 4 ,6 9 1 6 0 1 1 1 2 1 ,0 2 3 1 0 9 1 3 1 5 1 6 1 ,3 7 0 0 0 1 3 1 1 5 1 ,7 1 6 1 1 1 2 1 4 1 6 2 ,6 4 2 1 3 7 1 5 1 1 3 4 ,7 7 2 1 4 8 0
1 2 3 4 5 6 7 8 9
1 0 1 1 1 2 1 3 1 4 1 5
S ta d io
C lu ste r 1
C lu ste r 2
C lu ste r a cc o rp a ti
C o e fficie n ti
C lu s te r 1
C lu ste r 2
S ta d io d i fo rm a zio n e d e l c lu ste r P ro s sim o sta d io
P ro g ra m m a d i a g g lo m e ra z io n e
Capitolo 33
- * * * * C L U S T E R G E R A R C H I C A * * * * * * * * * * * * * * * * *
D e n d r o g r a m m a c o n l e g a m e m e d i o f r a i g r u p p i C l u s t e r a c c o r p a t i c o n d i s t a n z a r i s c a l a t a C A S O 0 5 1 0 1 5 2 0 2 5 E t i c h e t t a N u m e r o + - - - - - - - - - + - - - - - - - - - + - - - - - - - - - + - - - - - - - - - + - - - - - - - - - + L I F E E X P F 2 B A B Y M O R T 5 L I T E R A C Y 3 B I R T H _ R T 6 F E R T I L T Y 1 0 U R B A N 1 L O G _ G D P 8 P O P _ I N C R 4 B _ T O _ D 9 D E A T H _ R T 7 L O G _ P O P 1 1
Ø8ØØØØØÞ Øß ØØØÞ ØØØØØØØß ØØØØØØØØØØØÞ Ø8ØØØØØØØØØß ØØØØØØØØØØØØØØØÞ ØÙÙ ØØØØØØØØØØØØØØØ8ØØØØØØØß ØØØØØØØØØÞ ØØØØØØØØØØØØØØØÙÙ ØØØØØØØ8ØØØØØØØØØØØØØØØØØØØØØØØØØÞÙÙ ØØØØØØØß ØØØØØÙ ØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØÙ ØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØØ
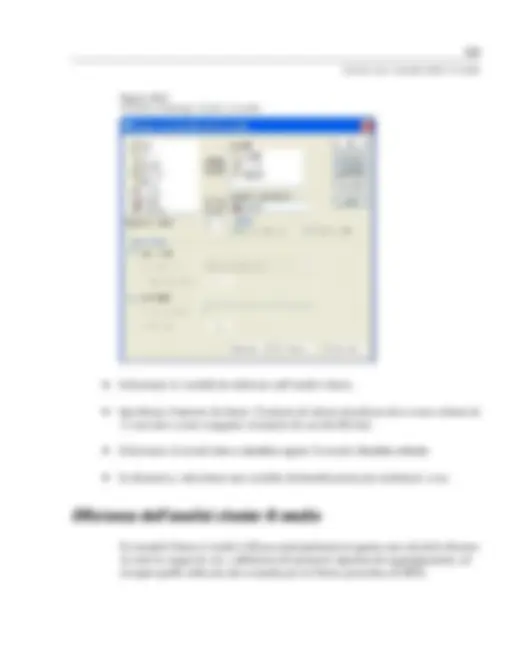
Per ottenere una cluster gerarchica
E Dai menu, scegliere:
Analizza
Classificazione
Cluster gerarchica...
Figura 33-
Finestra di dialogo Cluster gerarchica
E Per raggruppare i casi in cluster è necessario selezionare almeno una variabile
numerica. Per raggruppare le variabili in cluster è necessario selezionare almeno
tre variabili numeriche.
Cluster gerarchica
È inoltre possibile selezionare una variabile di identificazione per etichettare i casi.
Cluster gerarchica: Metodo
Figura 33-
Finestra di dialogo Cluster gerarchica: Metodo
Metodo di raggruppamento. Le alternative disponibili sono: Legame medio fra i
gruppi, Legame medio entro gruppi, Del vicino più vicino, Del vicino più lontano,
Centroide, Mediana e Ward.
Misura. Consente di specificare la misura di similarità o dissimilarità da utilizzare per
il raggruppamento. Selezionare il tipo di dati e la misura di similarità o dissimilarità
desiderata:
Intervallo. Le alternative disponibili sono: Distanza euclidea, Distanza euclidea
quadratica, Coseno, Correlazione di Pearson, Chebychev, City-Block, Minkowski
e Personalizzato.
Conteggi. Le alternative disponibili sono: Misura chi-quadrato e Misura
phi-quadrato.
Binaria. Le alternative disponibili sono: Distanza euclidea, Distanza euclidea
quadratica, Differenza di dimensione, Differenza di modello, Varianza,
Dispersione, Forma, Corrispondenza semplice, Correlazione phi a 4 punti,
Lambda, D di Anderberg, Dice, Hamann, Jaccard, Kulczynski 1, Kulczynski 2,
Lance e Williams, Ochiai, Rogers e Tanimoto, Russel e Rao, Sokal e Sneath 1,
Cluster gerarchica
Cluster gerarchica: Grafici
Figura 33-
Finestra di dialogo Cluster gerarchica: Grafici
Dendrogramma. Visualizza un dendrogramma. Utilizzando i dendrogrammi è
possibile valutare la coesione dei cluster formati ed ottenere informazioni sul numero
di cluster che è opportuno tenere.
A stalattite. Visualizza un grafico a stalattite , che comprende tutti i cluster o
un intervallo specifico di cluster. Nei grafici a stalattite vengono visualizzate
informazioni sulle modalità con cui i casi vengono combinati in cluster ad ogni
iterazione dell’analisi. Specificando l’orientamento desiderato è possibile selezionare
un grafico verticale o orizzontale.
Cluster gerarchica: Salva nuove variabili
Figura 33-
Finestra di dialogo Cluster gerarchica: Salva
Cluster di appartenenza. Consente di salvare i cluster di appartenenza per una
soluzione unica o per un intervallo di soluzioni. Le variabili salvate possono essere
utilizzate in analisi successive per valutare altre differenze tra i gruppi.
Capitolo 33
Funzioni aggiuntive della sintassi del comando CLUSTER
La procedura Cluster gerarchica usa la sintassi del comando CLUSTER. Il linguaggio
a comandi SPSS permette anche di:
Usare più metodi di raggruppamento in una singola analisi.
Leggere ed analizzare una matrice di prossimità.
Scrivere una matrice di prossimità sul disco per analizzarla in seguito.
Specificare i valori per la potenza e la radice nella misura della distanza
personalizzata (potenza).
Specificare i nomi delle variabili salvate.
Per informazioni dettagliate sulla sintassi, vedere SPSS Command Syntax Reference.
Capitolo 34
dipendente dall’ordine dei casi, indipendentemente dai centri di cluster scelti
inizialmente. Se si utilizza uno di questi metodi, può essere utile ottenere più
soluzioni diverse con casi disposti in ordini casuali diversi per verificare la stabilità di
una soluzione specifica. Per evitare problemi con l’ordine dei casi, è consigliabile
specificare i centri di cluster iniziali ed evitare di usare l’opzione Usa medie mobili.
Tuttavia, l’ordinamento dei centri di cluster iniziali può influire sulla soluzione se
esistono distanze assegnate dai casi ai centri di cluster. Per valutare la stabilità di una
soluzione, è possibile confrontare i risultati delle analisi con diverse permutazioni dei
valori dei centri iniziali.
Assunzioni. Le distanze vengono calcolate utilizzando la distanza euclidea semplice.
Se si desidera utilizzare un’altra misura di distanza o di similarità, utilizzare la
procedura Cluster gerarchica. La scalatura delle variabili è un’operazione che deve
essere effettuata con molta attenzione. Se le variabili vengono misurate con scale
diverse (ad esempio se una variabile è espressa in dollari e un’altra è espressa in anni),
i risultati possono essere fuorvianti. In questi casi è consigliabile standardizzare le
variabili prima di procedere con l’analisi cluster k medie (utilizzando la procedura
Descrittive). Questa procedura presume che sia stato selezionato il numero esatto di
cluster e che siano state incluse tutte le variabili rilevanti. Se è stato selezionato un
numero di cluster inesatto o sono state omesse variabili importanti, i risultati possono
essere inattendibili.
Figura 34-
Output della procedura Cluster K-medie
Z U R B A N
Z L IF E E X P
Z L IT E R A C
Z P O P _ IN C
Z B A B Y M O R
Z B IR T H _ R
Z D E A T H _ R
Z L O G _ G D P
Z B _ T O _ D
Z F E R T IL T
Z L O G _ P O P
C lu ste r
C e n tri in iz ia li d e i c lu s te r
Cluster con metodo delle K-medie
1.932 2.724 1.596 3.
.000 .471 .314. .861 .414 .195. .604 .337 .150. .000 .253 .167. .000 .199 .071.
.623 .160 .000. .000 .084 .074. .000 .080 .077. .000 .097 .000.
Iterazione
1 2 3 4 5 6 7 8 9
10
1 2 3 4
Modifiche ai centri dei cluster
Cronologia iterazioni
-1.70745 -.30863 .62767. -2.52826 -.15939 .80611 -. -2.30833 .13880 .73368 -. .59747 .13400 -.95175 1. 2.43210 .22286 -.80817.
1.52607 .12929 -.99285 1. 2.10314 -.44640 .31319 -. -1.77704 -.58745 .94249 -. -.29856 .19154 -.84758 1.
1.51003 -.12150 -.87669 1. .83475 .34577 -.22199 -.
ZURBANA
ZSPVITA
ZALFAB
ZINCRPOP
ZMORTINF
ZTASNAT
ZTASMOR
ZLOGPIL
ZNATSUMO
ZFERTIL
ZLOGPOP
1 2 3 4
Cluster
Centri dei cluster finali
5.627 7.924 5. 5.627 3.249 2.
7.924 3.249 5. 5.640 2.897 5.
Cluster
1
2
3
4
1 2 3 4
Distanze tra i centri dei cluster finali
Cluster con metodo delle K-medie
Figura 34-
Finestra di dialogo Cluster K-medie
E Selezionare le variabili da utilizzare nell’analisi cluster.
E Specificare il numero di cluster. Il numero di cluster specificato deve essere almeno di
2 e non deve essere maggiore al numero di casi del file dati.
E Selezionare il metodo Itera e classifica oppure il metodo Classifica soltanto.
E In alternativa, selezionare una variabile di identificazione per etichettare i casi.
Efficienza dell’analisi cluster K-medie
Il comando Cluster k -medie è efficace principalmente in quanto non calcola le distanze
tra tutte le coppie di casi, a differenza di numerosi algoritmi di raggruppamento, ad
esempio quello utilizzato dal comando per la Cluster gerarchica di SPSS.
Capitolo 34
Per ottenere la massima efficienza, creare un campione di casi e utilizzare il
metodo Itera e classifica per determinare i centri cluster. Selezionare Scrivi valori finali
su file. Quindi, ripristinare tutto il file di dati e selezionare Classifica soltanto come
metodo e selezionare Leggi valori iniziali per classificare tutto il file utilizzando i centri
valutati per il campione. È possibile leggere o scrivere da un file o file di dati. I file di
dati possono anche essere riutilizzati nella stessa sessione, ma non vengono salvati
come file a meno che siano stati salvati come tali alla fine della sessione. I nomi dei
file di dati devono essere conformi alle regole dei nomi delle variabili di SPSS. Per
ulteriori informazioni, vedere “Nomi delle variabili” in Capitolo 5 a pag. 99.
Cluster K-medie: Iterazioni
Figura 34-
Finestra di dialogo Cluster K-medie: Iterazioni
Nota : queste opzioni sono disponibili solo se si seleziona il metodo Itera e classifica
nella finestra di dialogo Cluster con metodo delle K-medie.
Massimo numero di iterazioni. Consente di impostare il numero massimo di iterazioni
per l’algoritmo k -medie. Le iterazioni si interromperanno al numero impostato, anche
se il criterio di convergenza non viene soddisfatto. Il numero deve essere compreso
tra 1 e 999.
Per riprodurre l’algoritmo utilizzato dal comando Quick Cluster delle versioni di
SPSS precedenti alla 5.0, impostare l’opzione Massimo numero di iterazioni su 1.
Criterio di convergenza. Determina il termine dell’iterazione. Rappresenta una
proporzione della distanza minima fra i centri iniziali del cluster in modo che sia
maggiore di 0 e minore di 1. Se, ad esempio, il criterio è 0,02, il processo di iterazione
terminerà quando un’iterazione completa non è in grado di spostare i centri cluster di
una distanza maggiore del 2% della distanza minima fra i centri iniziali del cluster.
Usa medie mobili. Consente di richiedere l’aggiornamento dei centri cluster in seguito
all’assegnazione di ciascun caso Se non viene selezionata questa opzione, i nuovi
centri del cluster verranno calcolati quando tutti i casi saranno stati assegnati.
Capitolo 34
iniziali vengono usati per un primo ciclo di classificazione e poi vengono
aggiornati.
Tabella ANOVA (Cluster k-medie: opzioni). Produce una tabella di analisi della
varianza con test F per ogni variabile. I test F sono descrittivi e il livello di
significatività fornisce informazioni utili. La tabella non viene creata se tutti i
casi vengono assegnati a un solo cluster.
Cluster per ogni caso. Visualizza per ogni caso il cluster di appartenenza e
la distanza euclidea dal centro del cluster utilizzato per classificare il caso.
Visualizza inoltre la distanza euclidea fra i centri finali.
Valori mancanti. Le opzioni disponibili sono Escludi casi listwise o Escludi casi pairwise.
Esclusione listwise. Consente di escludere i casi coni valori mancanti per le
variabili di raggruppamento dall’analisi.
Esclusione pairwise. Consente di assegnare i casi ai cluster in base alle distanze
calcolate da tutte le variabili con valori non mancanti.
Opzioni aggiuntive del comando QUICK CLUSTER
La procedura Cluster K-medie usa la sintassi del comando QUICK CLUSTER. Il
linguaggio a comandi SPSS permette anche di:
Accettare i primi k casi come centri dei cluster iniziali per evitare di dover leggere
i dati normalmente usati per stimarli.
Specificare i centri iniziali dei cluster direttamente come parte della sintassi del
comando.
Specificare i nomi delle variabili salvate.
Per informazioni dettagliate sulla sintassi, vedere SPSS Command Syntax Reference.