



Programming with OpenMP*
Intel Software College





























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
mmm - mmm - mmm - mmm
Typology: Thesis
1 / 85

This page cannot be seen from the preview
Don't miss anything!
Copyright © 2008, Intel Corporation. All rights reserved.
Copyright © 2008, Intel Corporation. All rights reserved.
Copyright © 2008, Intel Corporation. All rights reserved.
Copyright © 2008, Intel Corporation. All rights reserved.
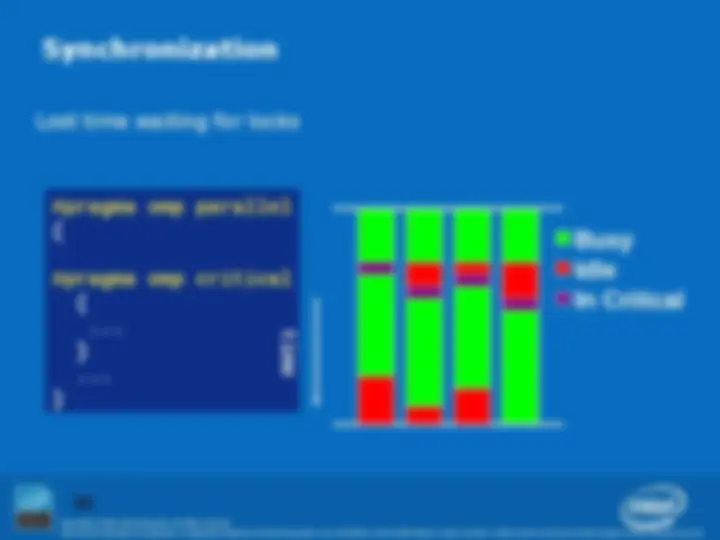
What is OpenMP? Parallel regions Worksharing Data environment Synchronization Curriculum Placement Optional Advanced topics
Copyright © 2008, Intel Corporation. All rights reserved.
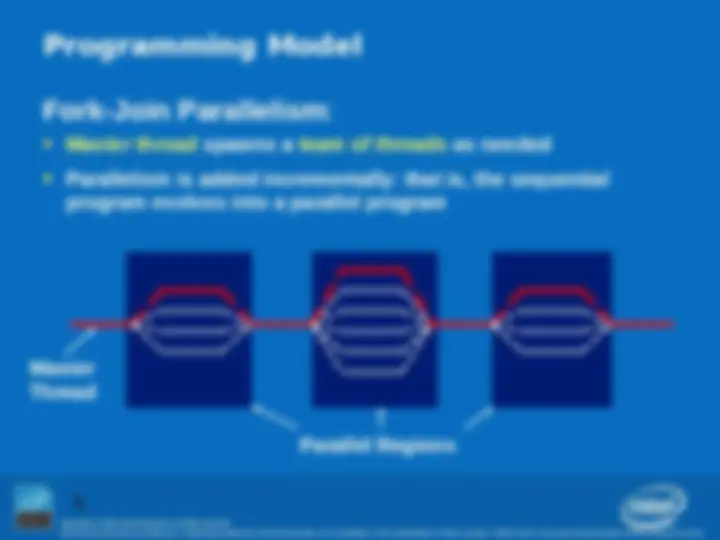
if (go_now()) goto more; #pragma omp parallel { int id = omp_get_thread_num(); more: res[id] = do_big_job(id); if (conv (res[id]) goto done; goto more; } done: if (!really_done()) goto more; #pragma omp parallel { int id = omp_get_thread_num(); more: res[id] = do_big_job (id); if (conv (res[id]) goto more; } printf (“All done\n”);
Copyright © 2008, Intel Corporation. All rights reserved.
What is OpenMP? Parallel regions Worksharing – Parallel For Data environment Synchronization Curriculum Placement Optional Advanced topics
Copyright © 2008, Intel Corporation. All rights reserved.
Copyright © 2008, Intel Corporation. All rights reserved.
#pragma omp parallel { #pragma omp for for (i=0;i< MAX; i++) { res[i] = huge(); } } #pragma omp parallel for for (i=0;i< MAX; i++) { res[i] = huge(); }
Copyright © 2008, Intel Corporation. All rights reserved.
Copyright © 2008, Intel Corporation. All rights reserved.
The schedule clause affects how loop iterations are mapped onto threads schedule(static [,chunk])
Copyright © 2008, Intel Corporation. All rights reserved.
#pragma omp parallel for schedule (static, 8) for( int i = start; i <= end; i += 2 ) { if ( TestForPrime(i) ) gPrimesFound++; }
Copyright © 2008, Intel Corporation. All rights reserved.
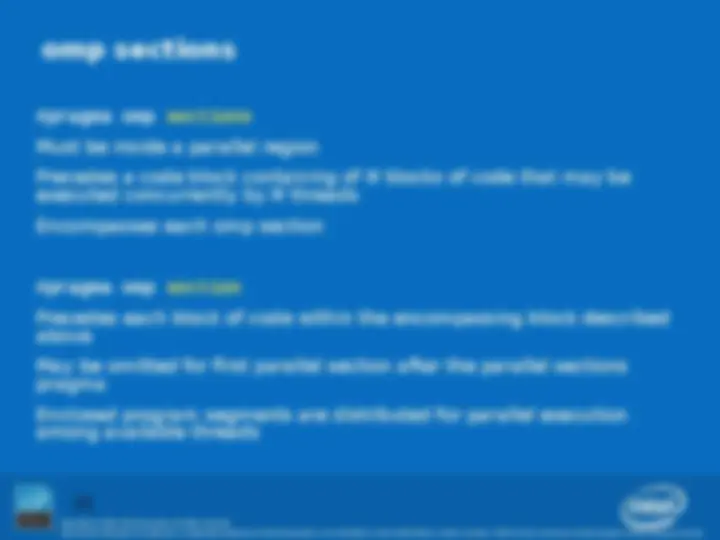
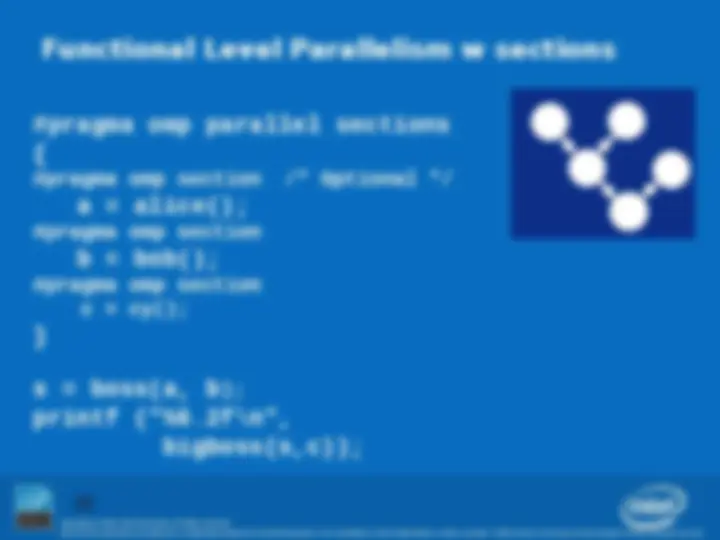
What is OpenMP? Parallel regions Worksharing – Parallel Sections Data environment Synchronization Curriculum Placement Optional Advanced topics
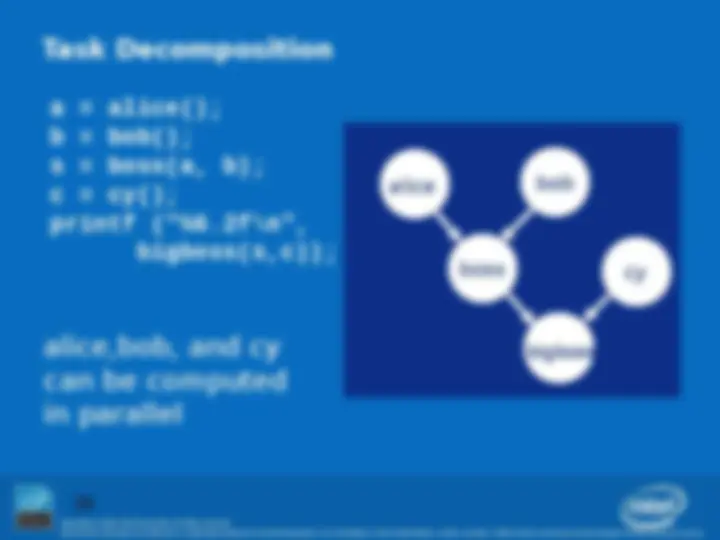
Copyright © 2008, Intel Corporation. All rights reserved. Task Decomposition a = alice(); b = bob(); s = boss(a, b); c = cy(); printf ("%6.2f\n", bigboss(s,c));
bigboss