



Drunken Paine, Dictionary, Jumble,
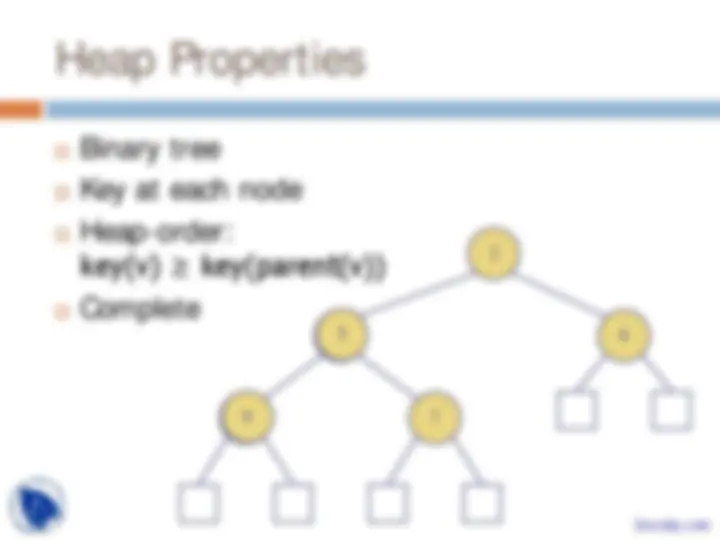
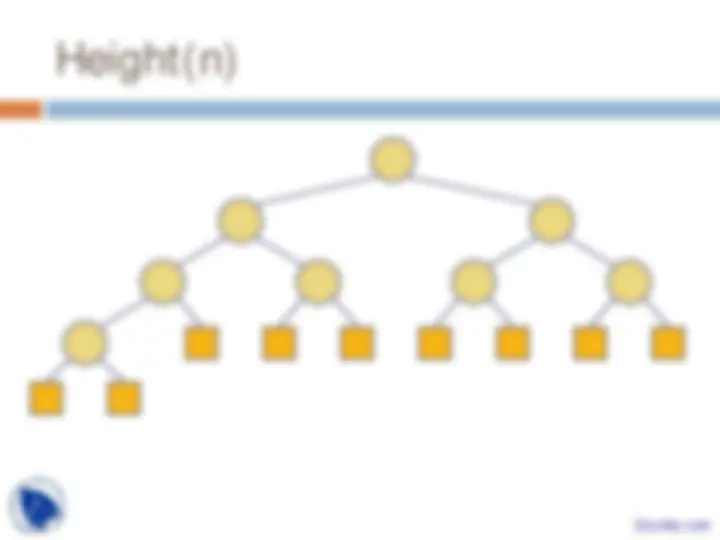
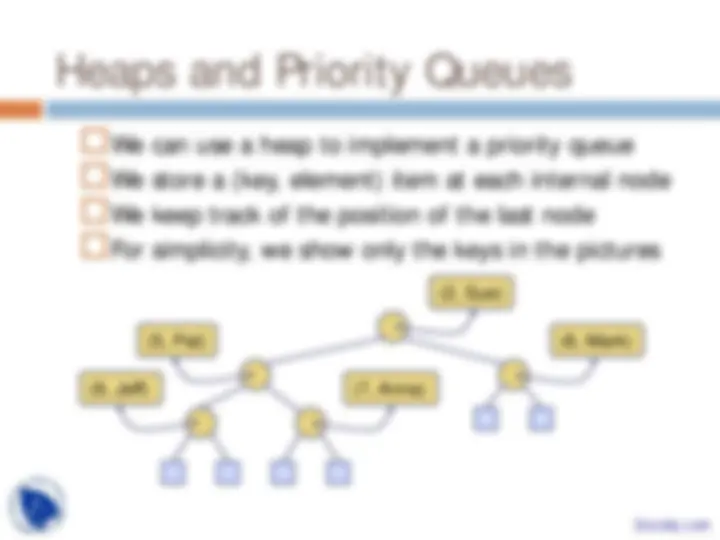
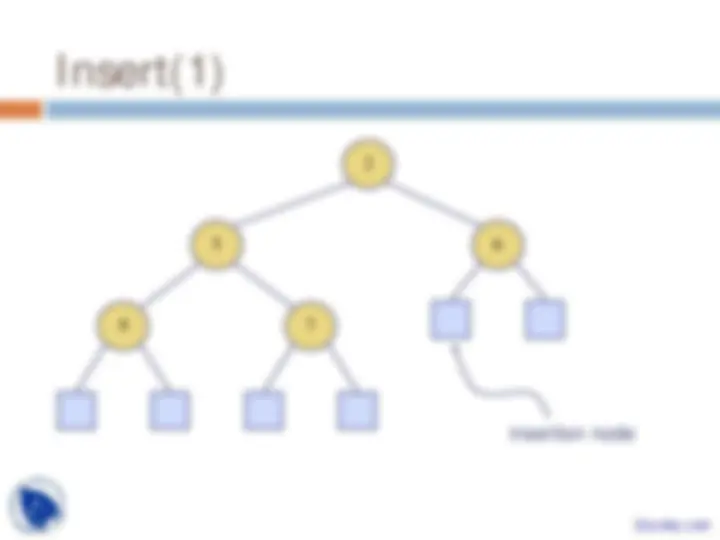
Priority Queues, Heaps
Docsity.com

















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The paine algorithm for finding a 'tom' in a group of people, an inductive proof of its running time and correctness, and the use of heaps and priority queues in data structures. It also explains the implementation of sets and dictionaries, and provides an example application of a jumble algorithm.
Typology: Lecture notes
1 / 48

This page cannot be seen from the preview
Don't miss anything!
True. We designed our algorithm’s base case according to the definition of a Tom in a group of size 1
Done.
We have an input of size k and we remove one non Tom from the group, then make a recursive call to find a Tom in a group of size k- This recursive call returns the correct answer (the Tom of the group of size k-1 or NULL)by our previous assumption
There is no Tom in the group of size k because we eliminated one non Tom and there’s no Tom in the other k-1 people Our algorithm returns NULL in this case, so it’s correct.
candidate is the only possible Tom of the group of size k candidate is not the Tom of the group of size k if the non Tom we eliminated doesn’t know candidate or if candidate knows the non Tom. In this case, there is no Tom in the group of size k, so we return NULL Otherwise, candidateis a Tom in the group of size k In this case, we return candidate
…given that our algorithm is correct for a group of size k-
Insert(key, value)
Let u = (a 1 key 1 + … + a (^) k keyk ) mod n
Insert (key, value) into array[u]
Find(key)
Let u = (a 1 key 1 + … + a (^) k keyk ) mod n
Search for (key, *) in array[u]
If you find (key, val), return val
Else return None
(Modify as appropriate to return list of vals)