



Part II
Extreme Models
Docsity.com


































































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The crcw hierarchy of submodels and its implications for efficient parallel algorithms. It covers various pram computations, including matrix multiplication, and provides examples of algorithms for sorting and selection. The document also touches upon topics like numa, uma, and coma.
Typology: Slides
1 / 115

This page cannot be seen from the preview
Don't miss anything!
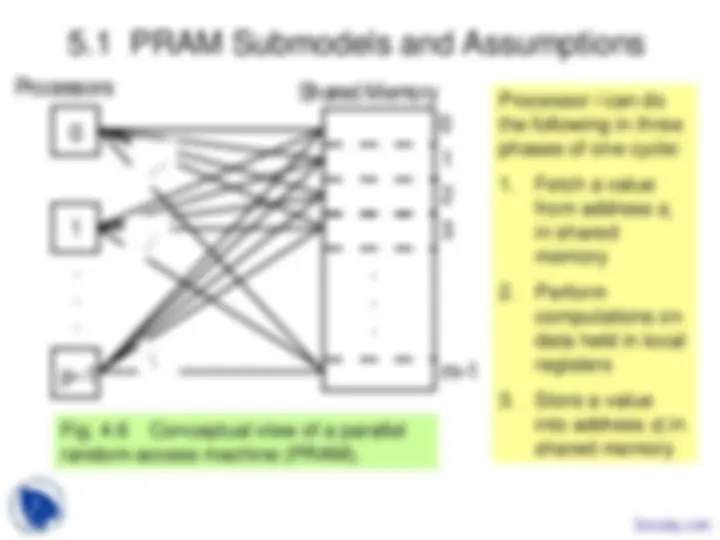
5.1 PRAM Submodels and Assumptions
Fig. 4.6 Conceptual view of a parallel random-access machine (PRAM).
Processor i can do the following in three phases of one cycle:
Fig. 5.1 Submodels of the PRAM model.
EREW Least “powerful”, most “realistic”
CREW Default
ERCW Not useful
CRCW Most “powerful”, further subdivided
Reads from same location
Writes to same location
Theorem 5.1: A p -processor CRCW-P (priority) PRAM can be simulated (emulated) by a p -processor EREW PRAM with slowdown factor Θ(log p ).
Intuitive justification for concurrent read emulation (write is similar): Write the p memory addresses in a list Sort the list of addresses in ascending order Remove all duplicate addresses Access data at desired addresses Replicate data via parallel prefix computation Each of these steps requires constant or O(log p ) time
Model U is more powerful than model V if T U( n ) = o( T V( n )) for some problem
EREW < CREW < CRCW-D < CRCW-C < CRCW-R < CRCW-P
1 6 5 2 3 6 1 1 2 1 1 1 2 2 3 5 6 6 1
2
3 5 6
Our most powerful PRAM CRCW submodel can be emulated by the least powerful submodel with logarithmic slowdown
Efficient parallel algorithms have polylogarithmic running times
Running time still polylogarithmic after slowdown due to emulation
A p -processor CRCW-P (priority) PRAM can be simulated (emulated) by a p -processor EREW PRAM with slowdown factor Θ(log p ).
EREW < CREW < CRCW-D < CRCW-C < CRCW-R < CRCW-P
We need not be too concerned with the CRCW submodel used
Simply use whichever submodel is most natural or convenient
5.2 Data
Broadcasting
Fig. 5.2 Data broadcasting in EREW PRAM via recursive doubling.
0 1 2 3 4 5 6 7 8 9
10 11
B
Fig. 5.3 EREW PRAM data broadcasting without redundant copying.
0 1 2 3 4 5 6 7 8 9
10 11
B
Can modify the algorithm so that redundant copying does not occur and array bound is not exceeded
EREW PRAM algorithm for all-to-all broadcasting Processor j , 0 ≤ j < p , write own data value into B [ j ] for k = 1 to p – 1 Processor j , 0 ≤ j < p , do Read the data value in B [( j + k ) mod p ] endfor
This O( p )-step algorithm is time-optimal
Naive EREW PRAM sorting algorithm (using all-to-all broadcasting) Processor j , 0 ≤ j < p , write 0 into R [ j ] for k = 1 to p – 1 Processor j , 0 ≤ j < p , do l := ( j + k ) mod p if S [ l ] < S [ j ] or S [ l ] = S [ j ] and l < j then R [ j ] := R [ j ] + 1 endif endfor Processor j , 0 ≤ j < p , write S [ j ] into S [ R [ j ]]
j
This O( p )-step sorting algorithm is far from optimal; sorting is possible in O(log p ) time
p – 1
0
5.3 Semigroup or Fan-in Computation
EREW PRAM semigroup computation algorithm Proc j , 0 ≤ j < p , copy X [ j ] into S [ j ] s := 1 while s < p Proc j , 0 ≤ j < p – s , do S [ j + s ] := S [ j ] ⊗ S [ j + s ] s := 2 s endwhile Broadcast S [ p – 1] to all processors
If we use p processors on a list of size n = O( p log p ), then optimal speedup can be achieved
This algorithm is optimal for PRAM, but its speedup of O( p / log p ) is not
Fig. 5.4 Semigroup computation in EREW PRAM.
0 1 2 3 4 5 6 7 8 9
S 0: 1: 2: 3: 4: 5: 6: 7: 8: 9:
0: 0: 1: 2: 3: 4: 5: 6: 7: 8:
0: 0: 0: 0: 1: 2: 3: 4: 5: 6:
0: 0: 0: 0: 0: 0: 0: 0: 1: 2:
0: 0: 0: 0: 0: 0: 0: 0: 0: 0:
Fig. 5.5 Intuitive justification of why parallel slack helps improve the efficiency.
Higher degree of parallelism near the leaves
Lower degree of parallelism near the root
Fig. 5.6 Parallel prefix computation in EREW PRAM via recursive doubling. 0 1 2 3 4 5 6 7 8 9
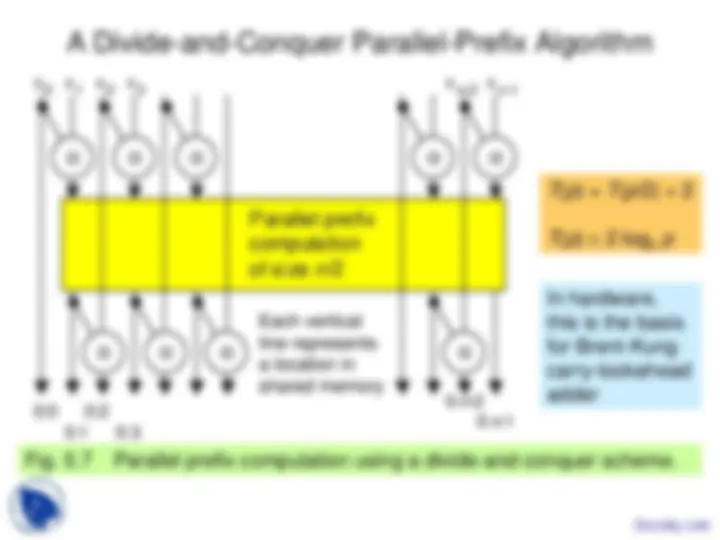
Fig. 5.8 Another divide-and-conquer scheme for parallel prefix computation.
Strictly optimal algorithm, but requires commutativity
x 0 x 1 x 2 x 3 x (^) n -2 x (^) n -
0: n - 0: n -
Parallel prefix comput ation on n / odd-indexed inputs
Parallel prefix comput ation on n / even-index ed inputs
⊗ ⊗ ⊗ ⊗ ⊗ ⊗ ⊗ ⊗ ⊗ ⊗
T ( p ) = T ( p /2) + 1
T ( p ) = log 2 p
Each vertical line represents a location in shared memory
5.5 Ranking the Elements of a Linked List
C F A E B D Rank: 5 4 3 2 1 0
info next head
Terminal element
(or dis tance from terminal) Dis tance from head: 1 2 3 4 5 6 Fig. 5.9 Example linked list and the ranks of its elements.
Fig. 5.10 PRAM data structures representing a linked list and the ranking results.
A B C D E F 4 3 5 3 1 0
info next^ rank 0 1 2 3 4 5
head
List ranking appears to be hopelessly sequential; one cannot get to a list element except through its predecessor!
Question: Which PRAM submodel is implicit in this algorithm?
If we do not want to modify the original list, we simply make a copy of it first, in constant time
A B C D E F 4 3 5 3 1 0
info next^ rank 0 1 2 3 4 5
head
PRAM list ranking algorithm (via pointer jumping) Processor j , 0 ≤ j < p , do {initialize the partial ranks} if next [ j ] = j then rank [ j ] := 0 else rank [ j ] := 1 endif while rank [ next [ head ]] ≠ 0 Processor j , 0 ≤ j < p , do rank [ j ] := rank [ j ] + rank [ next [ j ]] next [ j ] := next [ next [ j ]] endwhile
Answer: CREW
i
j
ij
PRAM solution with m^3 processors: each processor does one multiplication (not very efficient)
m × m matrices