


4/18/2022
1
Chapter6
Deepreinforcementlearning
Qiang Ji





































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of deep learning applications in reinforcement learning. It covers the basics of reinforcement learning, including the Markov property, state-action value function, Bellman equation, and value iteration. The document also discusses the differences between model-based and model-free approaches, as well as the advantages and disadvantages of policy-based RL. Examples of applications in Atari games, robotics, object detection, and AlphaGo are provided.
Typology: Lecture notes
1 / 45

This page cannot be seen from the preview
Don't miss anything!
-^
-^
Courtesy of Qiang Ji
Yann LeCun’s Cake Analogy
Self‐supervisedlearning
Learning to control (action) a system so asto maximize some numerical value (reward)which represents a long‐term objective. •^
There is no supervisor, only a rewardsignal
-^
Directly interacts with the world
-^
Agent’s actions affect the state of theworld
-^
Feedback is sequential, non i.i.d data, notinstantaneous, often with a delay Like human learning, learning is via implicitor weak supervision, and is incremental andcontinuous.
Slides from David Silver, Google DeepMind
Computer agent
-^
At each step
t
the agent:
Receives state
𝑠
௧
Executes action
𝑎
based on௧
Receives scalar reward
𝑟
௧
-^
The environment:
Receives action
𝑎
௧
Emits state
𝑠
௧^
based on p
a ss’
Emits scalar reward
𝑟
௧
-^
Repeats until the goal is achieved
Slides from David Silver, Google DeepMind
Computer agent
Interaction between agent and environment
:
The state –action‐transition‐ reward diagramfor a simple MDP with three states (green circles),two actions (orange circles),
two
rewards (yellow arrows), and transition probabilities.
Picture from wikipedia
గ
𝑠௧
, 𝑎
௧^
ൌ 𝐸
𝛾
𝑟௧ା்
ୀ
|𝜋
𝑄
గ
𝑠௧ାଵ
, 𝑎
௧ାଵ
∗^
௧^
௧^
௧^
∈
∗^
𝑠௧ାଵ
, 𝑎
௧ାଵ
0
1
2
3
Expected Q function at time t+1Select the best action at time t+1 instead of using current
t+
^
|s
, at
).t
t+
∗^
௧
௧^
శభ
∈
∗^
௧ାଵ
௧ାଵ
∗^
௧^
௧^
∗^
௧^
௧^
శభ
∈
∗^
௧ାଵ
௧ାଵ
௧ାଵ
௧^
t+
Deterministic state transition to s
t+
Current state
Legal moves
Rewards forlegal moves
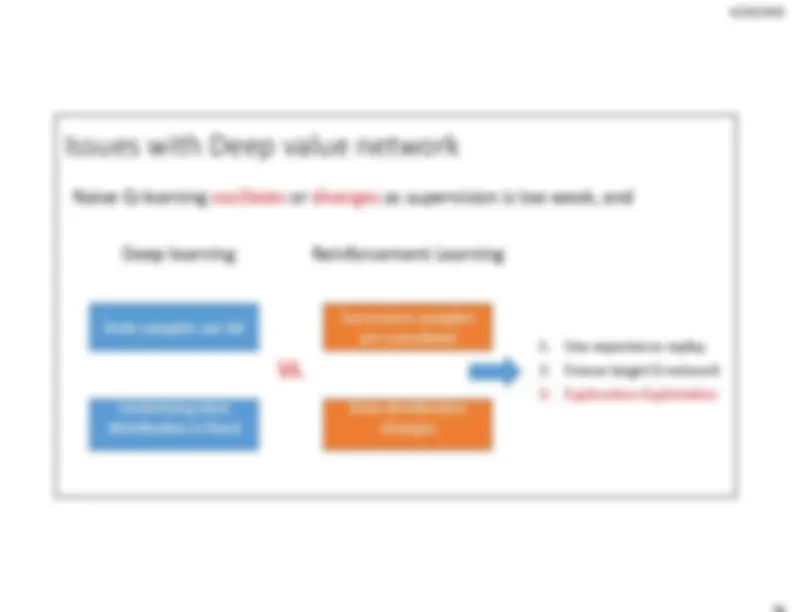
Model‐free approach •
6 States: 0, 1, 2, 3, 4, 5 ^
0‐room 0, 1‐room 1, .., 5‐outside 6 Actions: 0, 1, 2, 3,4, 5 •^
0‐go to room 0, 1‐go to room 1, …,5‐go outside
Reward table
Initial Q table
Updated Q table
3 legal moves at room 5Illegal moves are ignored
100 for outside move, ‐1 for illegalmoves, and 0 for others moves.
-^
-^
Updated Q table
Updated Q table
Normalize: /
Obtain the policy
from final
Q
)
, (
max
arg
)
(
a s
Q
s
a
Updated Q table
a
)
,
(
max
arg
)
(
a s
Q
s
a
Learning converges very fast.