Download Lecture Notes on Pipelining - Computer Organization | C SC 252 and more Study notes Computer Architecture and Organization in PDF only on Docsity!
CSc 252 — Computer Organization 1 8 — Pipelining
Pipelining
Read: Chapter 4, Sections 4.5 to 4.8 (4th edition); Chapter 6, Sections 6.1 to 6.5 (3rd edition)
Laundry example: washing (30 minutes), drying (30 minutes), folding (30 minutes), “stashing” (30 minutes).
If only one person’s wash, it takes 2 hours to complete.
If several folks need to do laundry, can do in 2 hours each — sequential solution:
But, the washer, dryer, “folder”, and “stasher” are independent units.
CSc 252 — Computer Organization 8 — Pipelining
Pipeline basics :
- Pipelined laundry takes 3.5 hours for four loads:
- Pipelining:
- Does not help the^ latency^ of a single tasks — still takes 2 hours to do one person’s laundry.
- Does help the^ throughput^ of the entire work load — 3.5 hours vs. 8 hours. - Multiple^ tasks operating simultaneously, each using different resources. - Potential^ speedup^ = number of pipe stages. - Rate limited by slowest pipeline stage. - Unbalanced lengths of pipe stages reduces speedup. - Time to “fill” pipeline and time to “drain” it reduces speedup.
CSc 252 — Computer Organization 8 — Pipelining
Pipeline basics (continued):
A more realistic picture: Not all cycles take the same amount of time:
Memory access is slower.
ALU computation is slower.
Register access is faster.
Figure 4.26, page 333 (4th edition) (There is a similar Figure 6.2, page 439 in the 3rd edition):
Instruction class
Instruction
fetch
Register
read
ALU
operation
Data
access
Register
write
Total
time
Load word ( lw ) 200 ps 100 ps 200 ps 200 ps 100 ps 800 ps
Store word ( sw ) 200 ps 100 ps 200 ps 200 ps 700 ps
R-format ( add , sub , and , or , slt ) 200 ps 100 ps 200 ps 100 ps 600 ps
Branch ( beq ) 200 ps 100 ps 200 ps 500 ps
CSc 252 — Computer Organization 8 — Pipelining
Pipeline basics (continued):
Can improve performance by increasing the instruction throughput:
3 load word ops, 24 nanoseconds:
Becomes 3 load word ops, 13 nanoseconds:
Clock cycle time dependent on the slowest phases: 200 picoseconds in this case.
Instruction
fetch
Reg. ALU
Data
access
Reg.
lw $s1,100($t0)
800 ps
Instruction
fetch
Reg.
ALU
Data
access
Reg.
Instruction
fetch
Reg. lw $s2,200($t0)
lw $s3,300($t0)
ALU
800 ps
Instruction
fetch
Reg. ALU
Data
access
Reg.
lw $s1,100($t0)
200 ps
Instruction
fetch
Reg.
ALU
Data
access
Reg.
Instruction
fetch
Reg. lw $s2,200($t0)
lw $s3,300($t0)
ALU
Data
access
Reg.
200 ps
200 ps 200 ps 200 ps 200 ps 200 ps
CSc 252 — Computer Organization 8 — Pipelining
Building a Pipelined datapath (continued):
Add pipeline registers in-between each pipeline stage.
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend 16 32
Shift
left 2
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Add
Zero
Result
ALU
Address
Write
data
Read
data
Data
memory
M
u
x
Sum
Add
IF:
Instruction fetch
ID:
Instruction decode/
register file read
EX:
Execute or
address calculation
MEM:
Memory
access
WB:
Write
back
M
u
x
M
u
x
CSc 252 — Computer Organization 8 — Pipelining
Building a Pipelined datapath (continued):
How big is each pipeline register? How many bits are in each? (We’ll need more bits before we are done…)
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend 32
Shift
left 2
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Add
Zero
Result
ALU
Address
Write
data
Read
data
Data
memory
M
u
x
Sum
Add
IF:
Instruction fetch
ID:
Instruction decode/
register file read
EX:
Execute or
address calculation
MEM:
Memory
access
WB:
Write
back
M
u
x
M
u
x
CSc 252 — Computer Organization 8 — Pipelining
Building a Pipelined datapath (continued):
The write register value is stored in the ID/EX register on cycle 2, then in EX/MEM on cycle 3, then in MEM/
WB on cycle 4. The value is finally used on cycle 5.
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend 16 32
Shift
left 2
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Add
Zero
Result
ALU
Address
Write
data
Read
data
Data
memory
M
u
x
Sum
Add
M
u
x
M
u
x
ID/EX, EX/MEM,
and MEM/WB are
now larger by
how many bits?
CSc 252 — Computer Organization 8 — Pipelining
Building a Pipelined datapath (continued):
What makes pipelining easy?
All instructions are the same length.
Only a few instruction formats (R-type, I-type, etc.)
Memory operands appear only in loads and stores.
What makes it hard?
Structural hazards: suppose we have only one memory.
Data hazards: an instruction depends on a previous instruction.
Control hazards: need to worry about branch instructions.
We’ll build a simple pipeline and look at (some of) these issues.
(Time permitting) We’ll talk about modern processors and what really makes it hard:
Exception handling.
Trying to improve performance with out-of-order execution, etc.
CSc 252 — Computer Organization 8 — Pipelining
Representing Pipelines (continued):
Can help with answering questions such as:
How many clock cycles does it take to execute this code?
What is the ALU doing during clock cycle 4? What else is happening during clock cycle 4?
Can use this representation to help understand datapaths through the CPU.
lw $10, 20($1)
sub $11,$2,$
IF ID MEM
EX
WB
sw $12,28($4)
time flows down:
program execution
order
IF ID
EX
WB
IF ID MEM
EX
WB
MEM
CSc 252 — Computer Organization 8 — Pipelining
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend 16 32
Shift
left 2
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Add
Instruction
[31-26]
Instruction
[25-21]
Instruction
[20-16]
Instruction
[15-11]
Instruction
[15-0]
M
u
x
Zero
ALU
result
ALU
M
u
x
Instruction
[5-0]
M
u
x
Address
Write
data
Read
data
Data
memory
M
u
x
Sum
Add
RegDst
Branch
MemRead
MemtoReg
ALUOp
MemWrite
ALUSrc
RegWrite
M
u
x
Shift
left 2 PC+4 [31-28]
Instruction
[25-0]
Jump
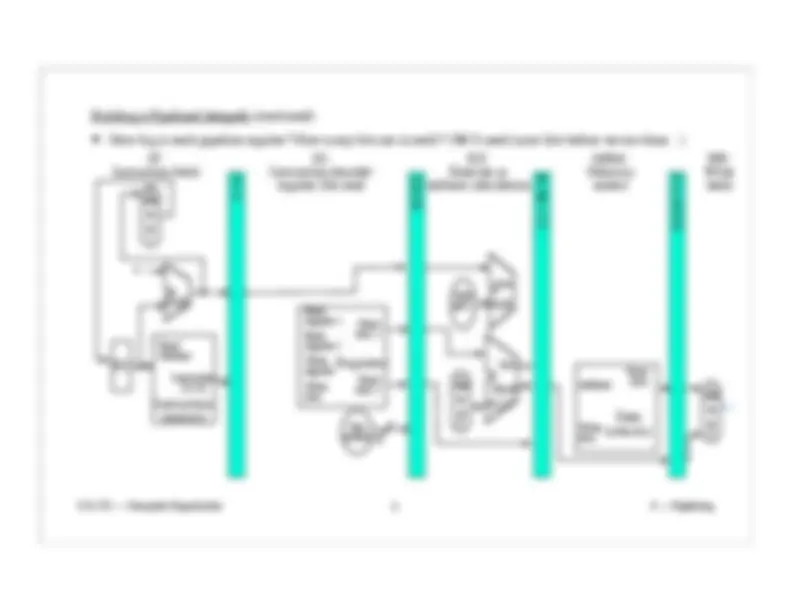
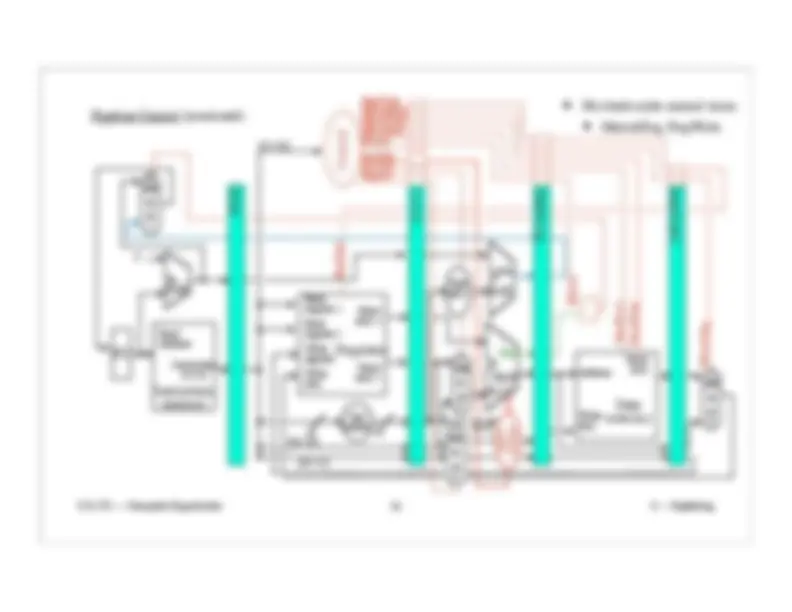
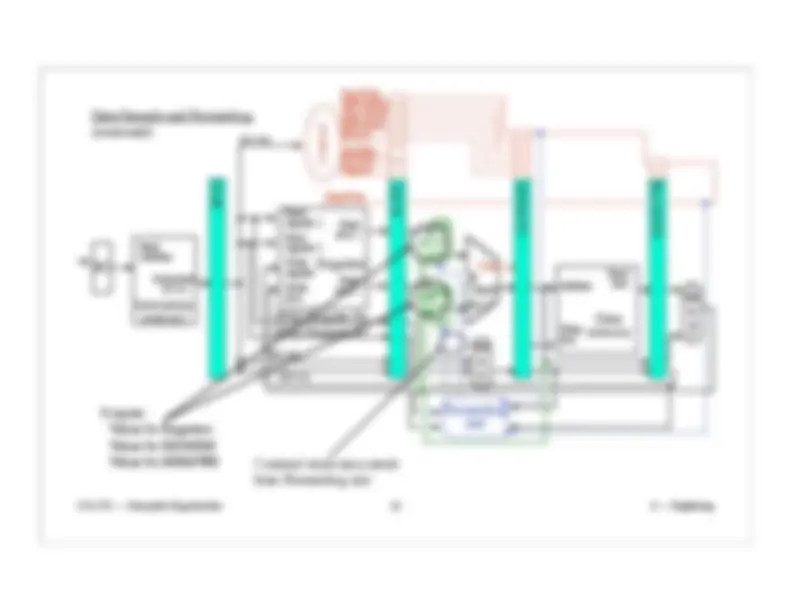
Pipeline Control :
Control wires are (more or less) the same ones we used before (as per the single-clock cycle implementation).
The lw instruction
uses bits 20-16.
The arithmetic ( add , sub , and , or ,
slt ) instructions use bits 15-11.
CSc 252 — Computer Organization 8 — Pipelining
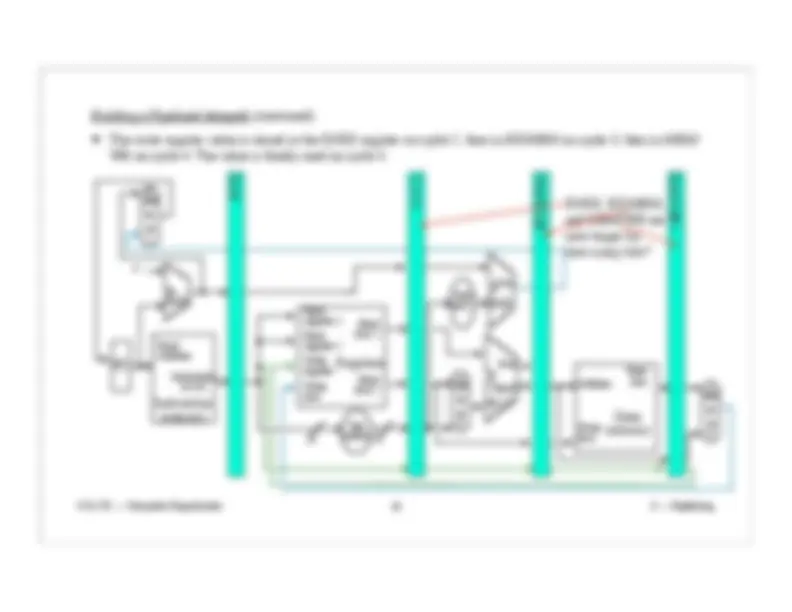
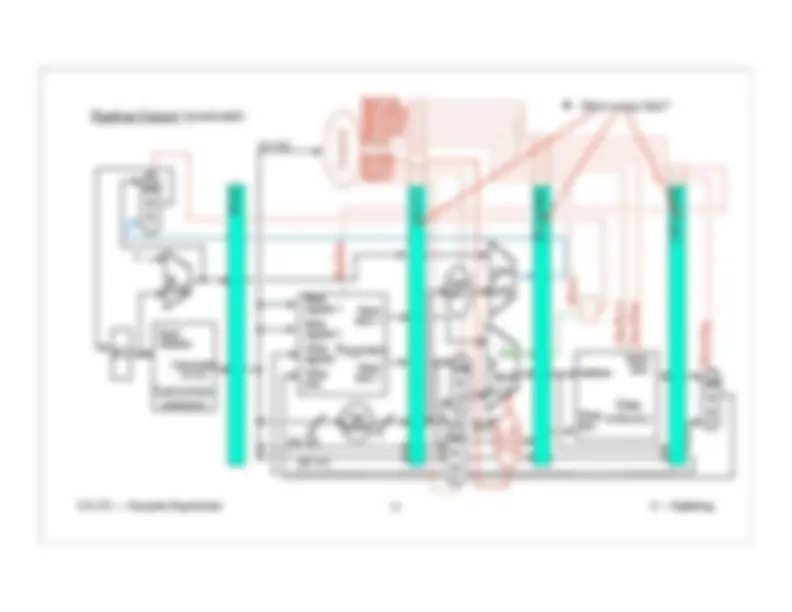
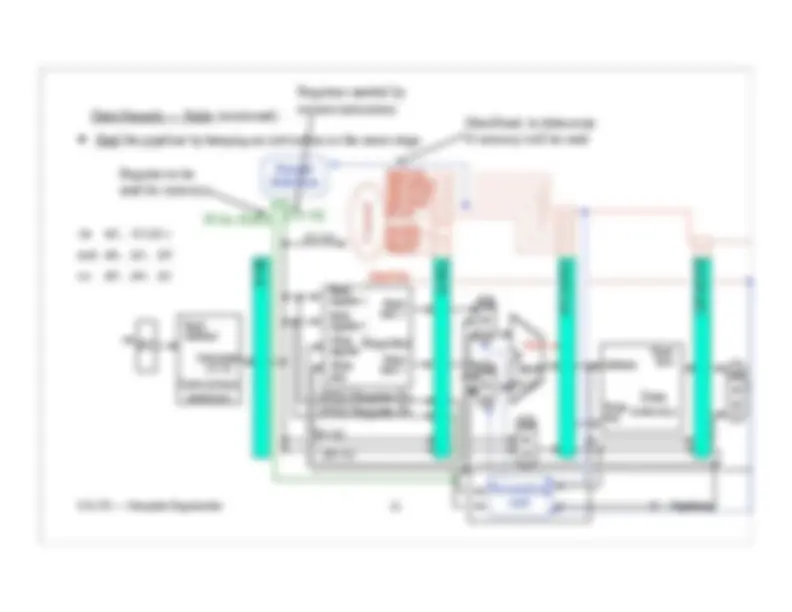
Pipeline Control (continued):
The second clock cycle has the Control unit. It gets the opcode from wires 31-26.
Control turns the RegDst control wire on or off.
Store the RegDst control wire in the ID/EX pipeline register for use during the 3rd clock cycle.
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend 16 32
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Zero
Result
ALU
Address
Write
data
Read
data
Data
memory
M
u
x
M
u
x
[20-16]
[15-11]
M
u
x
[31-26]
RegDst
How many bits are now in
the ID/EX pipeline register?
CSc 252 — Computer Organization 8 — Pipelining
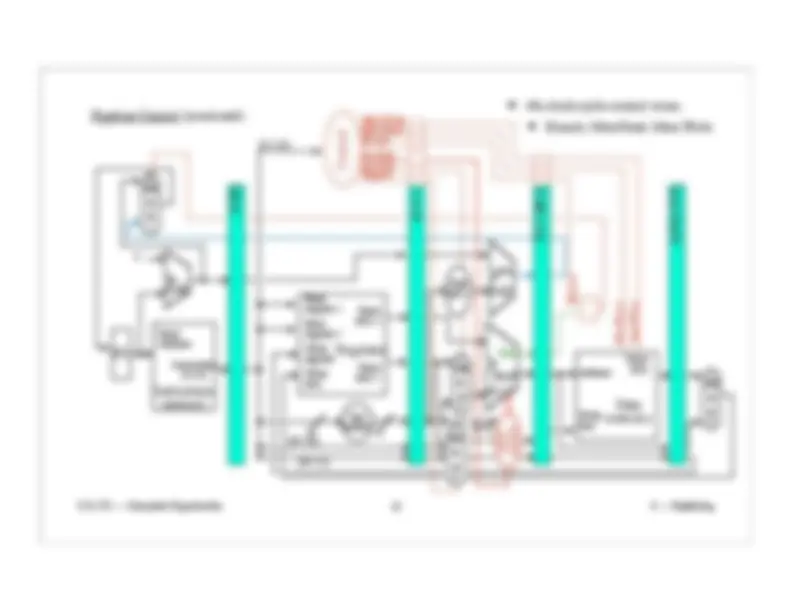
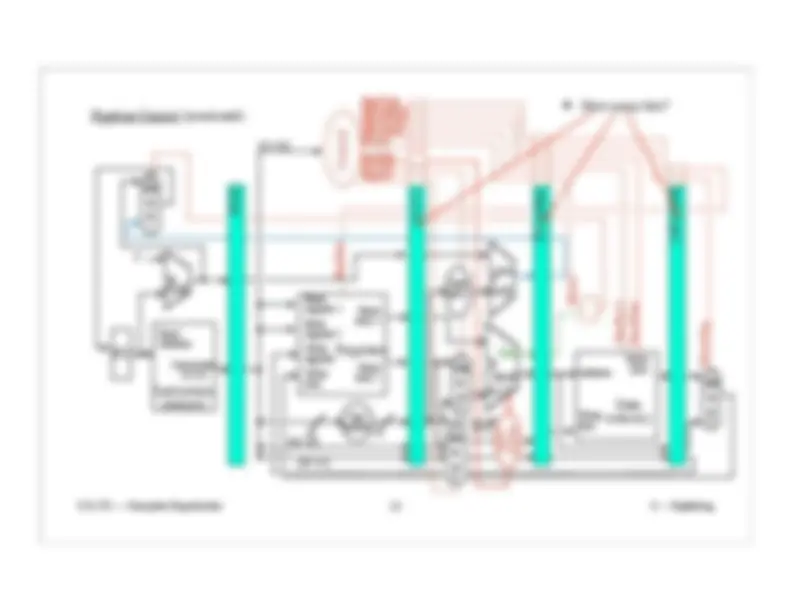
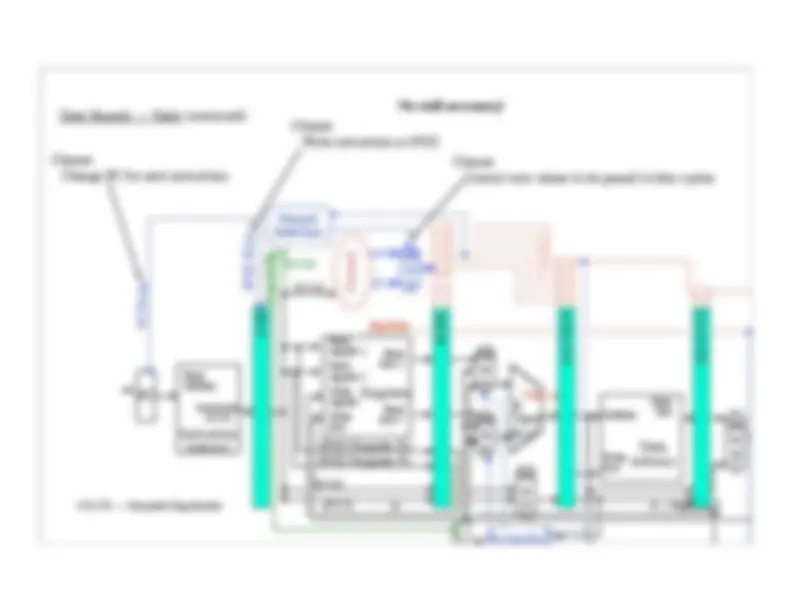
Pipeline Control (continued):
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend
16 32
Shift
left 2
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Add
Zero
Result
ALU
Address
Write
data
Read
data
Data
memory
M
u
x
Sum
Add
M
u
x
M
u
x
[20-16]
[15-11]
M
u
x
[31-26]
RegDst
ALUOp
ALUSrc
[5-0]
How many bits are now in
the ID/EX pipeline register?
Other control wires for 3rd clock cycle:
ALUSrc (1 wire)
ALUOp (2 wires)
Both from single clock cycle
implementation.
CSc 252 — Computer Organization 8 — Pipelining
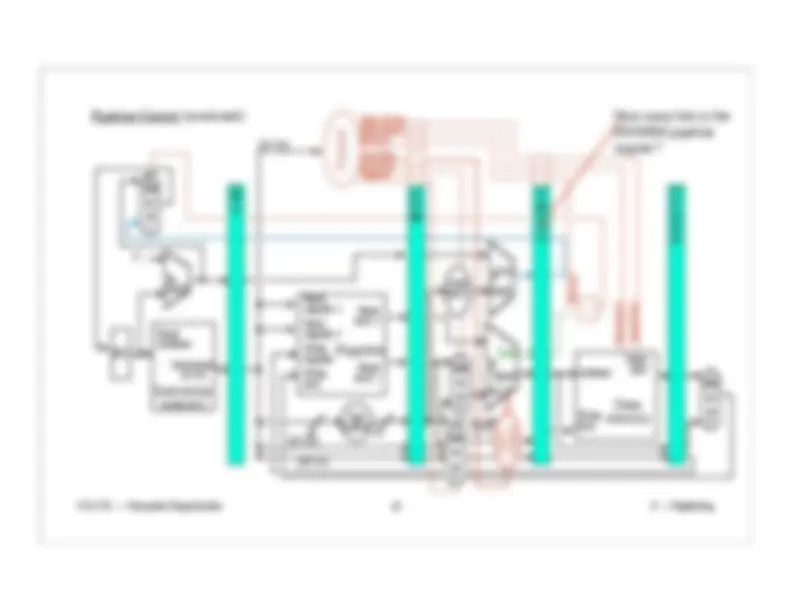
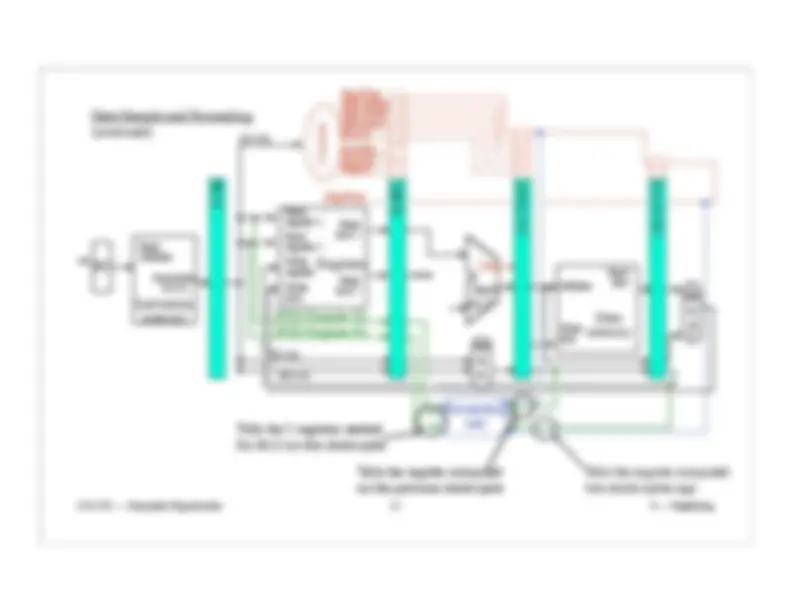
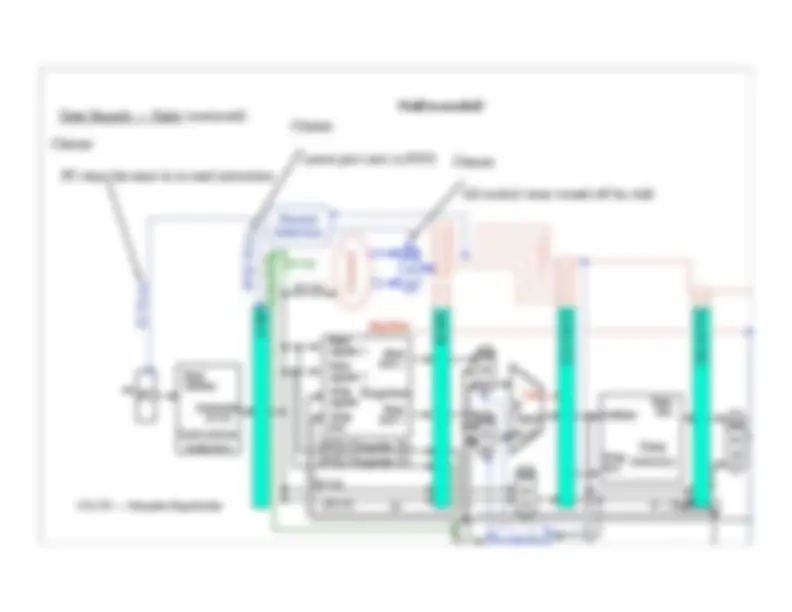
Pipeline Control (continued):
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend
16 32
Shift
left 2
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Add
Zero
Result
ALU
Address
Write
data
Read
data
Data
memory
M
u
x
Sum
Add
M
u
x
M
u
x
[20-16]
[15-11]
M
u
x
[31-26]
RegDst
ALUOp
ALUSrc
[5-0]
Branch
MemRead
MemWrite
How many bits in the
EX/MEM pipeline
register?
CSc 252 — Computer Organization 8 — Pipelining
Write
data
Read
register 1
Registers
Read
register 2
Write
register
Read
data 1
Read
data 2
Sign
extend
16 32
Shift
left 2
Read
Address
Instruction
[31-0]
Instruction
memory
PC
Add
Zero
Result
ALU
Address
Write
data
Read
data
Data
memory
M
u
x
Sum
Add
M
u
x
M
u
x
[20-16]
[15-11]
M
u
x
[31-26]
RegDst
ALUOp
ALUSrc
[5-0]
Branch
MemRead
MemWrite
MemtoReg
RegWrite
Pipeline Control (continued):
5th clock cycle control wires:
MemtoReg, RegWrite.