Download instruction pipelining and more Study Guides, Projects, Research Computer Architecture and Organization in PDF only on Docsity!
MIPS Pipeline
n Five stages, one step per stage
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
Pipeline Performance
n Assume time for stages is n 100ps for register read or write n 200ps for other stages n Compare pipelined datapath with single-cycle datapath Instr Instr fetch Register read ALU op Memory access Register write Total time lw 200ps 100 ps 200ps 200ps 100 ps 800ps sw 200ps 100 ps 200ps 200ps 700ps R-format 200ps 100 ps 200ps 100 ps 600ps beq 200ps 100 ps 200ps 500ps
Pipeline Speedup
n If all stages are balanced
n i.e., all take the same time n Time between instructions pipelined = Time between instructions nonpipelined Number of stages
n If not balanced, speedup is less
n Speedup due to increased throughput
n Latency (time for each instruction) does not decrease
Pipelining and ISA Design
n MIPS ISA designed for pipelining
n All instructions are 32-bits n Easier to fetch and decode in one cycle n c.f. x86: 1- to 17-byte instructions n Few and regular instruction formats n Can decode and read registers in one step n Load/store addressing n Can calculate address in 3 rd stage, access memory in 4 th stage n Alignment of memory operands n Memory access takes only one cycle
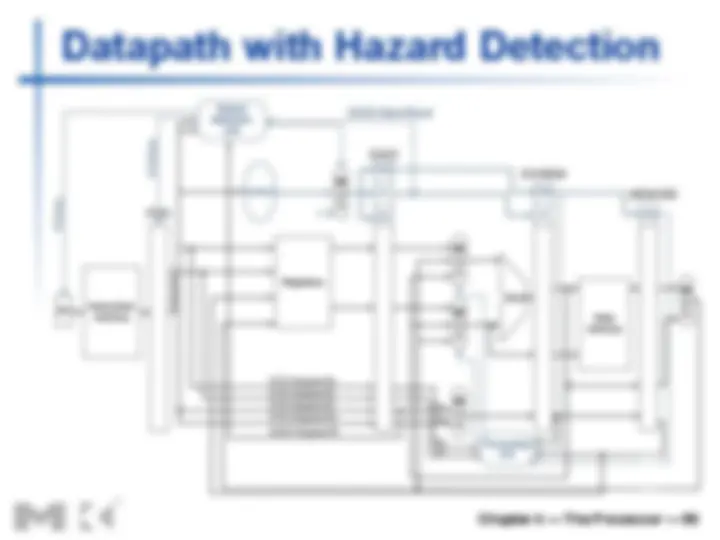
Structure Hazards
n Conflict for use of a resource
n In MIPS pipeline with a single memory
n Load/store requires data access n Instruction fetch would have to stall for that cycle n Would cause a pipeline “bubble”
n Hence, pipelined datapaths require
separate instruction/data memories
n Or separate instruction/data caches
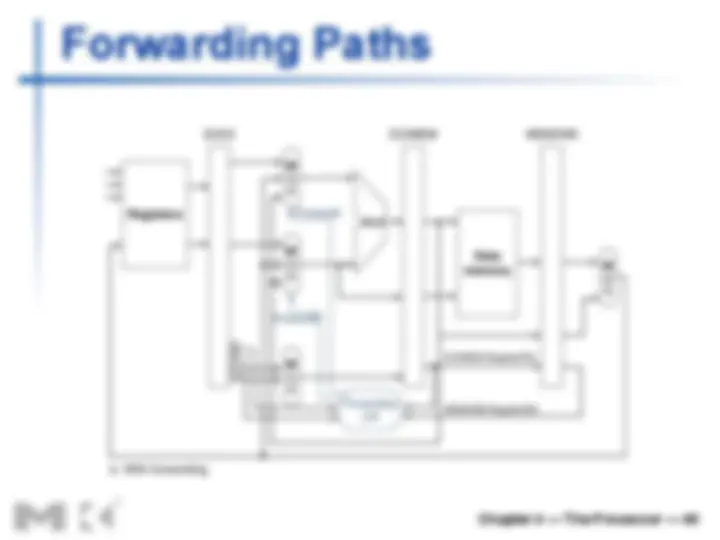
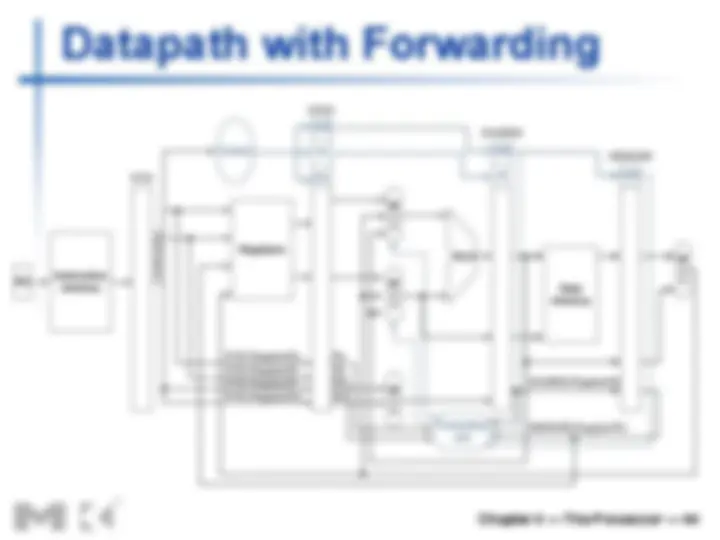
Data Hazards
n An instruction depends on completion of
data access by a previous instruction
n add $s0, $t0, $t sub $t2, $s0, $t
Load-Use Data Hazard
n Can’t always avoid stalls by forwarding
n If value not computed when needed n Can’t forward backward in time!
Code Scheduling to Avoid Stalls
n Reorder code to avoid use of load result in
the next instruction
n C code for A = B + E; C = B + F;
lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1, $t sw $t5, 16($t0) stall stall lw $t1, 0($t0) lw $t2, 4($t0) lw $t4, 8($t0) add $t3, $t1, $t sw $t3, 12($t0) add $t5, $t1, $t sw $t5, 16($t0) 13 cycles 11 cycles
Stall on Branch
n Wait until branch outcome determined
before fetching next instruction
Branch Prediction
n Longer pipelines can’t readily determine
branch outcome early
n Stall penalty becomes unacceptable
n Predict outcome of branch
n Only stall if prediction is wrong
n In MIPS pipeline
n Can predict branches not taken n Fetch instruction after branch, with no delay
More-Realistic Branch Prediction n Static branch prediction n Based on typical branch behavior n Example: loop and if-statement branches n Predict backward branches taken n Predict forward branches not taken n Dynamic branch prediction n Hardware measures actual branch behavior n e.g., record recent history of each branch n Assume future behavior will continue the trend n When wrong, stall while re-fetching, and update history
Pipeline Summary
n Pipelining improves performance by
increasing instruction throughput
n Executes multiple instructions in parallel n Each instruction has the same latency
n Subject to hazards
n Structure, data, control
n Instruction set design affects complexity of
pipeline implementation
The BIG Picture
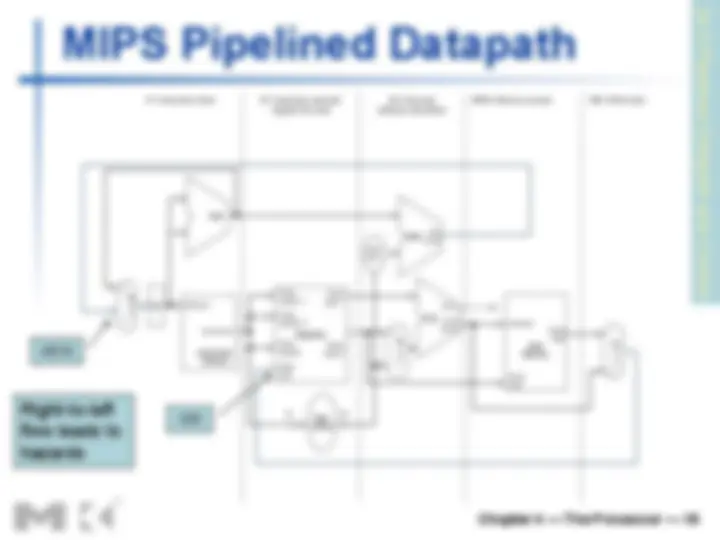
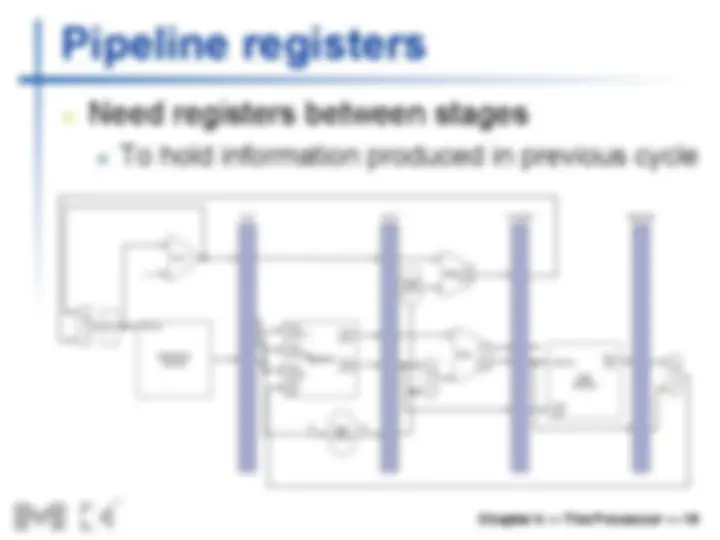
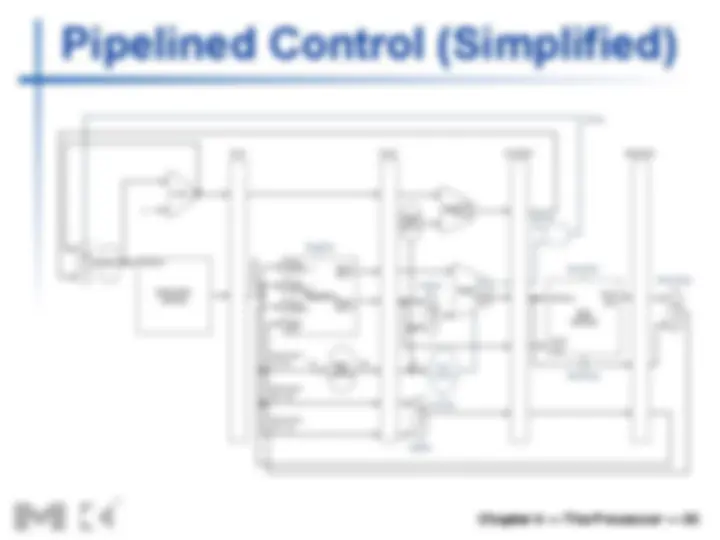
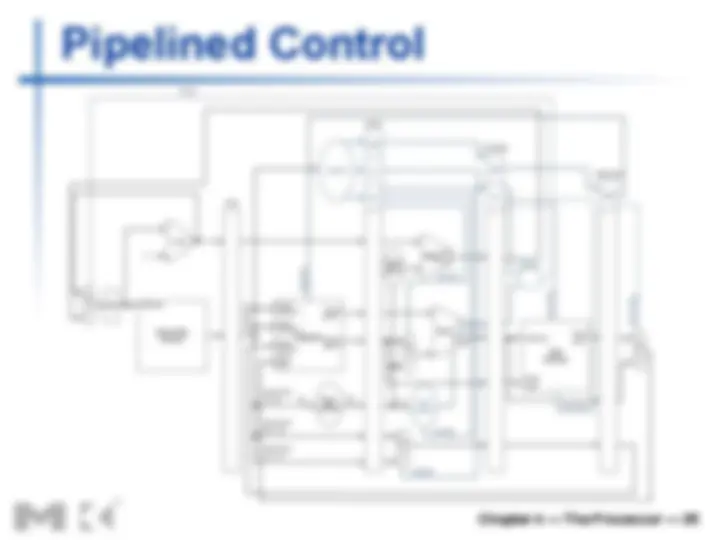
Pipeline registers
n Need registers between stages
n To hold information produced in previous cycle
Pipeline Operation
n Cycle-by-cycle flow of instructions through
the pipelined datapath
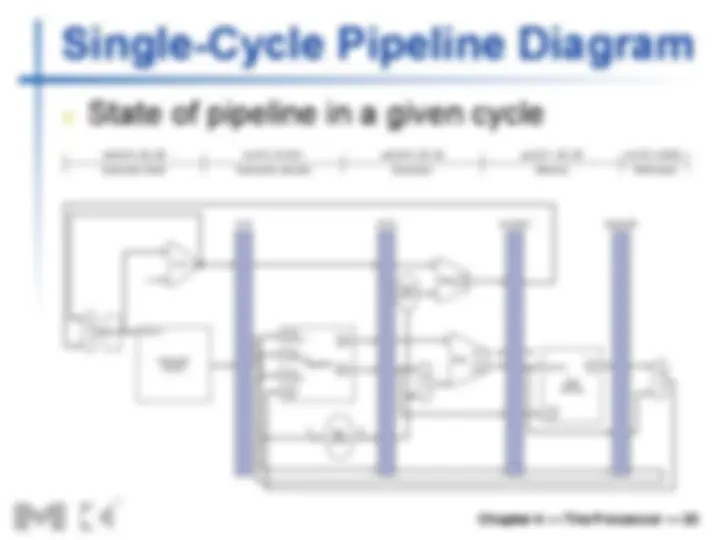
n “Single-clock-cycle” pipeline diagram n Shows pipeline usage in a single cycle n Highlight resources used n c.f. “multi-clock-cycle” diagram n Graph of operation over time
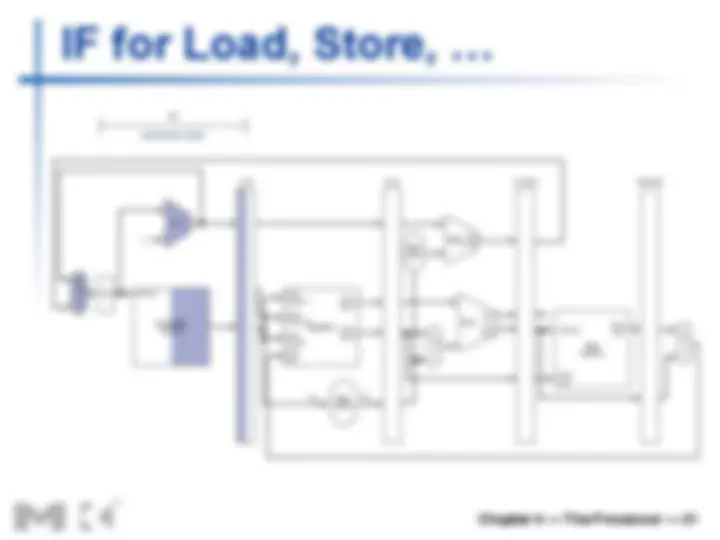
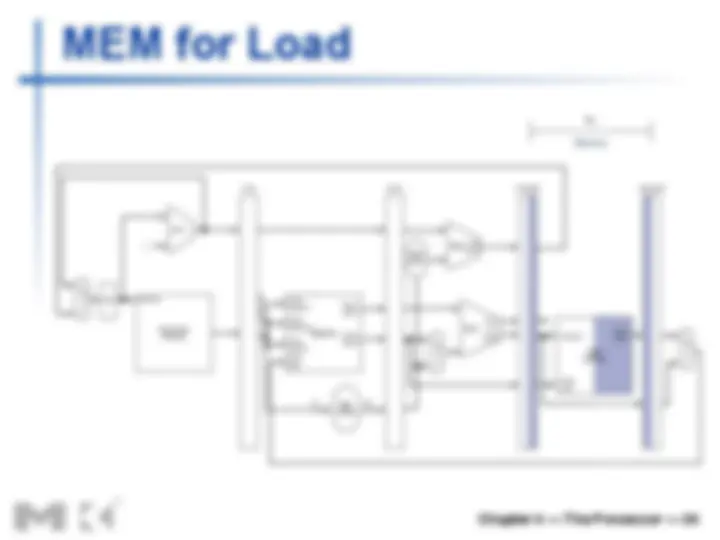
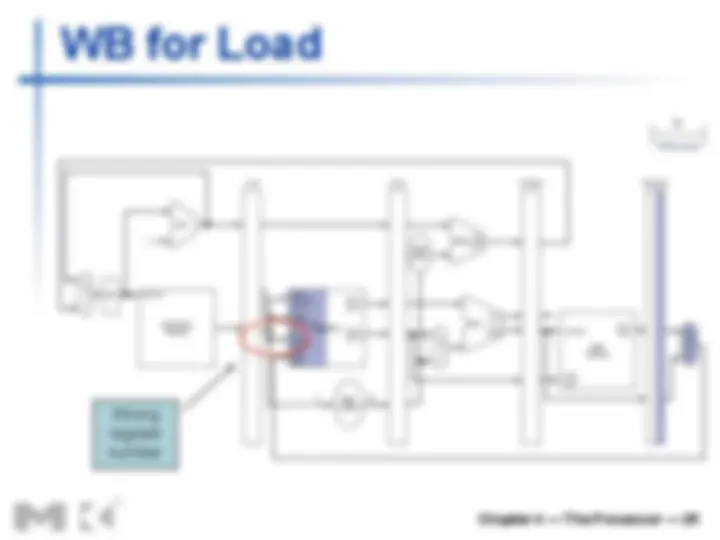
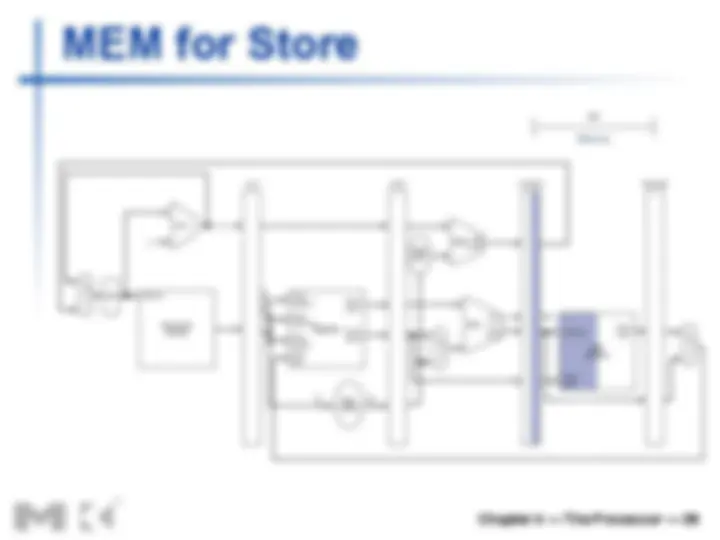
n We’ll look at “single-clock-cycle” diagrams
for load & store