Download PageRank Based Prototype Search Engine-Implementation and Applications In Computer Sciences-Project Presentation and more Slides Applications of Computer Sciences in PDF only on Docsity!
PageRank Based Prototype Search Engine
In this presentation we will look at,
Indexing
Inverted Index
Swish-e
Crawler
Operational model of incremental crawler
Architecture of incremental crawler
HTML parser
MD
Searcher
Keyword queries
Boolean queries
Phrase queries
User Interface
Swish-e
Indexer
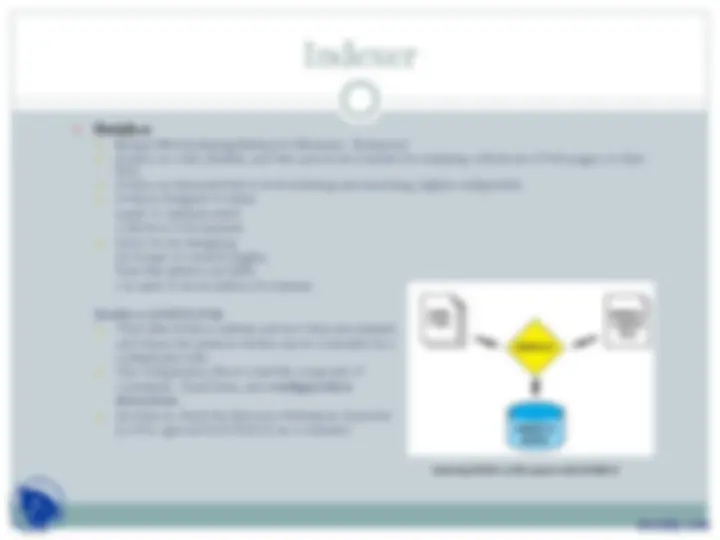
Every Searcher Engine consists of an indexer module.
Allows indexing of set of documents retrieved using crawler module.
Allows efficient retrieval of documents when provided with the query.
Inverted index is an index used by the search engines.
An inverted index is easy to build and very efficient to search.
Swish-e is an open source indexing system which we plan to integrate
into our system
Inverted Index
Example: We have three documents of id 1, id 2, and id 3:
id 1: Web mining is useful.
1 2 3 4
id 2: Usage mining applications.
1 2 3
id 3: Web structure mining studies the Web hyperlink structure.
1 2 3 4 5 6 7 8
vocabulary:
{Web, mining, useful, applications, usage, structure, studies, hyperlink}
Inverted index:
Applications: id 2
Hyperlink: id 3
Mining: id 1, id 2, id 3
Structure: id 3
Studies: id 3
Usage: id 2
Useful: id 1
Web: id 1, id 3
Indexer
Swish-e S imple W eb I ndexing S ystem for H umans - E nhanced Swish-e is a fast, flexible, and free open source system for indexing collections of Web pages or other files. Swish-e is extremely fast in both indexing and searching, highly configurable. Swish is designed to index small- to medium-sized collection of documents. Since we are designing prototype of a search engine, thus this system can fulfill our need of about million documents.
Swish-e CONFIG File What files Swish-e indexes and how they are indexed, and where the index is written can be controlled by a configuration file. The configuration file is a text file composed of comments, blank lines, and configuration directives. Any line in which the first non-whitespace character is a # is ignored by SWISH-E as a comment.
Indexing HTML on file system with SWISH-E
Crawler
In the previous presentation we looked at the design of
crawler.
Now we will look at how crawler conceptually operates
From this conceptual model we will identify two key
decisions that incremental crawler should make.
Then we will look at architecture of an incremental crawler
Operational model of an incremental crawler
Conceptual operation of the crawler can be shown with following pseudo-code. Procedure While (true) //select the next page to crawl url selectToCrawl (AllUrls) //crawls the page page crawl (url) if ( url is in CollUrls ) then update (url, page) else //discard existing page from the collection tmpurl selectToDiscard (CollUrls) discard (tmpurl) //compress crawled page page compress (page) //save that compressed page save (url, page) //update CollUrls CollUrls (CollUrls-{tmpurl}) U {url} End if //extract links from the page newurls extractUrls (page) AllUrls AllUrls U newurls End while
Architecture of an incremental crawler
Incremental crawler continuously crawls the web, revisiting pages
periodically.
During its continuous crawl, it may also purge some pages in the local
collection, in order to make room for newly crawled pages.
During this process, the crawler should have two goals:
Keep the local collection fresh
Improve quality of the local collection
In order to implement these goals and to effectively implement
refinement/update decisions, we will use following architecture
Architecture of an incremental crawler
Architecture of an Incremental Crawler
Crawler
Html parser
Crawl module extract links from a page in order to fill AllUrls data
structure.
Thus we need to parse html to find links within it.
For this purpose we are using Simple HTML DOM Parser which is
designed to work with php 5+. PHP Simple HTML DOM Parser has
following set of features,
A HTML DOM parser written in PHP5+ let you manipulate HTML in a very
easy way.
Require PHP 5+.
Supports invalid HTML.
Find tags on an HTML page.
Extract contents from HTML in a single line.
Crawler
MD
MD5 (Message-Digest Algorithm 5) is a widely used partially insecure
cryptography hash function with 128-bit hash value.
We will use this algorithm in order to check whether a page which we
chose to update has changed since last crawl.
Update module records the checksum of the page from the last crawl
and compares that checksum with the one from the current crawl.
From this comparison, the update module can tell whether the page has
changed or not.
We will create md5 hash of URLs in the AllUrls data structure in order
to avoid adding same URL in AllUrls.
Searcher
Keyword queries
The user expresses his/her information needs with a list of (at
least one) keywords (or terms ) aiming to find documents that
contain some (at least one) or all the query terms.
The terms in the list are assumed to be connected with a “soft”
version of the logical AND.
For example, if one is interested in finding information about Web
mining, one may issue the query „Web mining‟ to search engine.
Searcher
Boolean queries
The user can use Boolean operators, AND, OR, and NOT to construct complex queries. Thus, such queries consist of terms and Boolean operators. For example, „data OR Web‟ is a Boolean query, which requests documents that contain the word „data‟ or „Web. A page is returned for a Boolean query if the query is logically true in the page (i.e., exact match).
Phrase queries
Such a query consists of a sequence of words that makes up a phrase. Each returned document must contain at least one instance of the phrase. In a search engine, a phrase query is normally enclosed with double quotes. For example, one can issue the following phrase query (including the double quotes), “Web mining techniques and applications” to find documents that contain the exact phrase.
Searcher
Swish-e
Swish-e also provides searching functionality that can be embedded
into our prototype search engine.
Searching a Swish-e index involves passing command line
arguments to it that specifies the index file to use, and the query (or
search words) to locate in the index.
Swish-e returns a list of file names (or URLs) that contain the
matched search words.
In Prototype search engine we will take results of swish-e and rank
them locally before forwarding those results to the user.
Boolean Operators You can use the Boolean operators and , or , near or not in searching. Without these Boolean operators Swish-e will assume you're and 'ing the words together Wildcards Two different wildcard characters are available, each evoking different behavior. The * means "match zero or more characters." The? means "match exactly one character." Phrase Searching To search for a phrase in a document use double-quotes to delimit your search terms.
Thanks for your patience