


User-Level IPC for SMPs
• based on paper “User-level Interprocess
Communication for Shared-Memory
Multiprocessors”, Bershad et al.
– mixed discussion about user-level threads and
user-level RPC
















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The paper 'user-level interprocess communication for shared-memory multiprocessors' by bershad et al. The concept of user-level interprocess communication (ipc) for shared-memory multiprocessors (smps), focusing on cross-address space calls and the optimization of user-level thread management. The document also covers the importance of efficient ipc mechanisms and the differences between local and remote ipc, with a particular emphasis on user-level rpc and user-level thread management.
Typology: Study notes
1 / 24

This page cannot be seen from the preview
Don't miss anything!
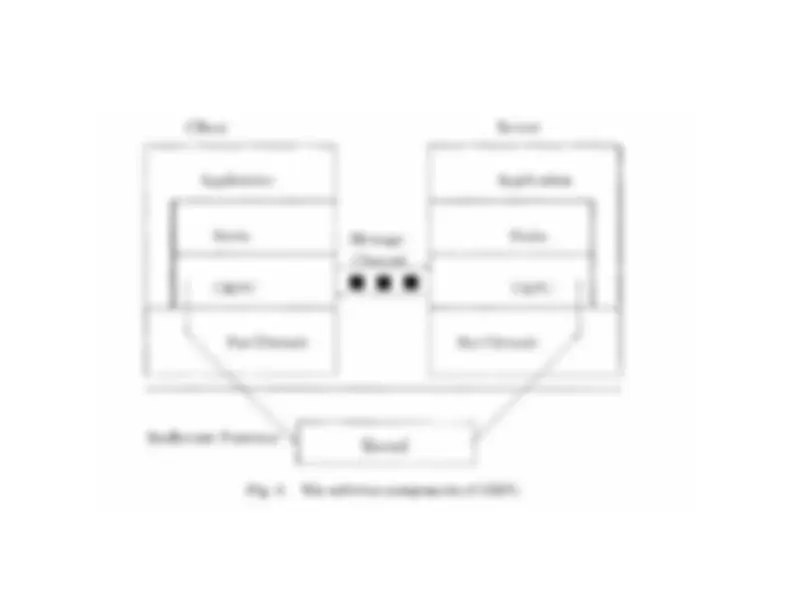
user-level RPC
kernel
MT client
MT server
data transfer
needs to be efficient – performance of systems dependsupon fast IPC mechanism
-^
typical ‘local’ IPC mechanisms– shared synchronization variables– shared memory
-^
typical ‘local’ or ‘remote’ IPC mechanisms– message passing
our discussion will concentrate on ‘local’ communication
In RPC, communication between address spaces isstructured similarly to procedure calls
-^
An RPC runtime hides from higher layers addresscrossing, type checking, procedure parameter andresult transfers, etc…)
-^
From the caller’s perspective, RPC aresynchronous calls – can have different failuresemantics
-^
details in following lecture
standard RPC is kernel-based– this is overkill for multi-threaded applications: argument
similar as for user-level threads: cost of trapping in thekernel, switching memory management context…
URPC is specialization of RPC for a SMM
-^
Characteristics summary:– shared memory is used for passing arguments and results,
without kernel invocation
frequent by lazy address-switch
multithreaded programs
sharedmailbox
server’saddressspace
authentication implied statically– mapping done once by kernel pairwise between client
and server
correctness checked dynamically– on each call-return between client and server by URPC
runtime (runtime responsible for putting data inmemory buffers, inspecting type, range, etc…)
upshot?– cross address space calls can be implemented without
involvement of the kernel – both send and receive canbe done within the user-level library…
solution:– give P1 to some other ready in client (thread
management at user level)
the server thread to handle the call i.e. keep the OS out!
-^
always possible to do this?– if an address space is under-powered then processor
reallocation may be necessary
the same address space, until it really has togive processor to another address space
Client has an editor with two thread T1 and T
-^
T1 invokes a procedure in a window manager,then upon return invokes a procedure in a filecache manager
-^
T2 invokes a procedure in a file cache manager
-^
Initially, the editor and window manager arerunning on two processors, the file cache manageris not scheduled on a processor.
-^
What is the sequence of events?
processor reallocation without any schedulingdecision – amortize cost of kernel involvementover multiple cross-address space calls
-^
data transfer via shared memory– no kernel copying, no dynamic protection checking– message channels protected by polling style t&s locks
-^
user level threads– 100 times cheaper than kernel threads for context
switches