



Tema 4. Cuestiones importantes
en el MLG
Econometría
Universidad Complutense de Madrid















































Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
.......................................................................................
Tipo: Apuntes
1 / 56

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
¿Qué aprenderá en este tema?
Colinealidad
T
Colinealidad
0
T
X X
0
T
X X
T X) < k+1, el determinante
de (X
T X) es igual a cero y no se puede invertir la matriz (X
T X)
la matriz de varianzas y covarianzas del estimador MCO no
está definida.
lineales exactas:
Colinealidad exacta
una variable explicativa es aproximadamente igual a una
combinación lineal de las restantes. Es decir, hay variables
explicativas altamente correlacionadas.
T X) = k+1, el determinante
de (X
T X) es distinto de cero pero muy pequeño y se puede invertir
la matriz (X
T X). El sistema de ecuaciones normales tiene una
única solución
-La solución del sistema de ecuaciones normales es poco precisa.
este tipo de multicolinealidad es reconocer una serie de efectos
perniciosos que presenta sobre los resultados de la estimación
Colinealidad de grado
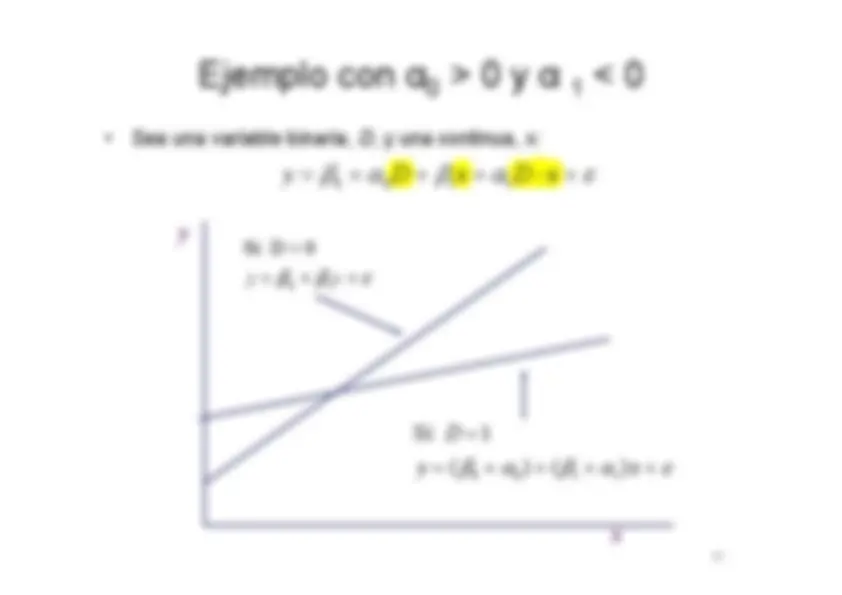
Ejemplo: (^) t 1 2 t 2 3 t 3 t con y x x t t t
x x 2 3
8
2
j
2 de la regresión de x j
sobre las demás x (incluyendo un
término constante).
2 ): Cuanto mayor sea la variación en
los no observables que afectan a y, menos preciso será
: cuanto más dispersas estén
las x j
mayor precisión en la estimación de β j
. Y aumenta al
aumentar la muestra!
2
j
): Proporción de la varianza de x j
explicada por el resto
de variables independientes
Cuanto mayor sea, menos precisa será la estimación de β j
10
Efectos de la colinealidad de grado
Más varianza del estimador
quiere decir menor precisión
2
2 2
1
var( )
j (^) n
j j j
i
x x R
(2) Los estadísticos t de significación individual
estarán sesgados a la baja. Esto hará que
tendamos a NO RECHAZAR la H 0
: β j
= 0 más
frecuentemente.
(3) El contraste de significación global de las
pendientes del modelo no se verá afectado.
La bondad del ajuste seguirá siendo parecida
ante la presencia de variables explicativas
superfluas.
ˆ
ˆ varˆ
j
j
t
( 1 ) 1
2
2
R n k
R k
F
Efectos de la colinealidad de grado
De hecho, un síntoma claro de multicolinealidad de grado es
que los parámetros NO sean INDIVIDUALMENTE significativos,
pero SÍ lo sean de manera CONJUNTA. Esto es una contradicción
estadística, salvo que exista un problema en los datos.
a los de disponer de una muestra pequeña
(micronumerosidad) o de una variable independiente que
varíe poco por sí misma (aún sin estar relacionada
linealmente con otras).
multicolinealidad, muestra pequeña o escasa variabilidad de
las variables independientes):
(nuestra muestra no es lo bastante “rica”) para estimar
adecuadamente todos los parámetros.
afecta a la precisión de la estimación del efecto de una
tercera variable
Efectos de la colinealidad de grado
(a) Métodos basados en la correlación entre variables explicativas
(a.1) Calcular la correlación lineal simple existente entre pares
de variables explicativas. Si hacemos esto para los k
regresores del modelo, obtenemos una matriz R con la
forma:
elevadas (cercanas a uno en valor absoluto) síntoma de
multicolinealidad. Sin embargo, estas correlaciones no captan
dependencias lineales más complejas entre las variables
explicativas.
Detección de la colinealidad
12 1
21 2
1 2
.. 1. . 1
k
k
k k
r r
r r
R
r r
(b) Métodos basados en medir el tamaño de la matriz (X
T X)
T X. El problema es que este determinante depende de
las unidades de medida de las variables explicativas.
una matriz simétrica es igual al producto de sus
autovalores. Es decir,. Si alguno de
estos autovalores es cercano a cero, el determinante
también lo será. El problema es que los autovalores de
una matriz también dependen de las unidades de medida
de las variables explicativas.
Detección de la colinealidad
1 2
...
T
k
X X
(b) Métodos basados en medir el tamaño de la matriz (X
T X)
suele medir el tamaño relativo de los autovalores. En
concreto, se calcula el “número de condición” de la matriz
T X) como la raíz cuadrada del cociente entre el mayor y
el menor autovalor
alta colinealidad
Detección de la colinealidad
max
min
N º de condición
Descripción de los datos: 88 viviendas
Modelo 1: MCO, usando las observaciones 1-
Variable dependiente: price
Coeficiente Desv. Típica Estadístico t Valor p
const -40.4477 21.5942 -1.8731 0.06462 *
assess 0.904078 0.104268 8.6707 <0.00001 ***
bdrms 9.63026 6.91629 1.3924 0.
lotsize 0.000599268 0.000497077 1.2056 0.
sqrft 0.00107136 0.0171966 0.0623 0.
colonial 9.54757 10.6473 0.8967 0.
Media de la vble. dep. 293.5460 D.T. de la vble. dep. 102.
Suma de cuad. residuos 155242.4 D.T. de la regresión 43.
R-cuadrado 0.830864 R-cuadrado corregido 0.
F(5, 82) 80.56328 Valor p (de F) 3.59e-
Log-verosimilitud - 453.7845 Criterio de Akaike 919.
Criterio de Schwarz 934.4330 Crit. de Hannan-Quinn 925.
¿Quiere eso decir que el número de habitaciones, el tamaño de la casa,
el de la parcela o el estilo no afectan al precio?
Puede ser que la información contenida en estas variables esté recogida,
total o parcialmente, en el valor de tasación