¡Descarga EJERCICIOS INTEGRADORES DE PROGRAMACION EN PYTHON y más Exámenes en PDF de Programación Informática solo en Docsity!
EJERCICIOS INTEGRADORES DE PROGRAMACION
EN PYTHON
Universidad de Atacama - Facultad de Ingenieria
12 de Mayo de 2025
Ejercicios 1-
1. Gesti´on de Biblioteca
Temas: Funciones, listas/diccionarios, archivos, b´usqueda lineal.
Enunciado: Desarrolla un sistema para gestionar libros (t´ıtulo, autor, a˜no, disponibilidad).
Implementa:
- Funciones para agregar libros y buscar por autor.
- Guardar los datos en un archivo biblioteca.txt.
- Men´u interactivo con while y if-elif-else.
2. Estad´ısticas de Texto
Temas: Archivos, cadenas, funciones.
Enunciado: Dado un archivo input.txt, calcula:
- N´umero de palabras, l´ıneas y caracteres.
- Palabra m´as larga y m´as corta.
- Guarda los resultados en resultados.txt.
3. Ordenamiento de Productos
Temas: Listas de diccionarios, algoritmos (burbuja), archivos CSV.
Enunciado: Ordena productos (nombre, precio, stock) por precio usando burbuja. Guarda
los datos en productos.csv.
4. Validaci´on de Contrase˜nas
Temas: Funciones, manejo de errores, archivos binarios.
Enunciado: Valida contrase˜nas con:
- 8+ caracteres, may´usculas, min´usculas y n´umeros.
- Guarda contrase˜nas v´alidas en contrase~nas.dat.
5. Juego de Adivinanza
Temas: Bucles while, condicionales, archivos.
Enunciado: Genera un n´umero aleatorio (1-100) y registra intentos en records.txt.
6. Factorial Recursivo
Temas: Recursividad, manejo de errores.
Enunciado: Implementa factorial recursivo con validaci´on para enteros positivos.
7. B´usqueda en Matriz
Temas: Matrices, b´usqueda lineal, logs de errores.
Enunciado: Busca un valor en una matriz 5x5 y registra errores en errores.log.
8. Agenda de Contactos
Temas: Diccionarios, JSON, excepciones.
Enunciado: Guarda contactos (nombre, tel´efono, email) en agenda.json.
9. Cifrado C´esar
Temas: Cadenas, archivos, funciones.
Enunciado: Cifra/descifra texto con desplazamiento y guarda en cifrado.txt.
10. An´alisis de Ventas
Temas: Diccionarios, ordenamiento (selecci´on), archivos.
Enunciado: Ordena ventas por mes y genera reporte en ventas.txt.
Ejercicios 11-
11. Sistema de Notas Estudiantiles
Temas: Listas de diccionarios, CSV, promedio.
Enunciado: Calcula promedio de notas y guarda en notas.csv.
12. Conversor de Unidades
Temas: Funciones, men´u interactivo, archivos.
Enunciado: Convierte km/millas, °C/°F y guarda historial en conversiones.txt.
13. Generador de Tablas de Multiplicar
Temas: Recursividad, archivos.
Enunciado: Genera tablas en archivos tabla del X.txt.
14. Analizador de N´umeros Primos
Temas: Algoritmos (criba de Erat´ostenes), archivos binarios.
Enunciado: Guarda primos en primos.dat.
15. Gestor de Tareas Pendientes
Temas: Ordenamiento (selecci´on), JSON.
Enunciado: Ordena tareas por prioridad en tareas.json.
16. Simulador de Dados
Temas: Bucles for, aleatoriedad, archivos.
Enunciado: Guarda lanzamientos en dados.txt.
17. Pal´ındromos y Archivos
Enunciado: Calcula cuotas de pr´estamos y guarda planes en credito.txt.
27. Encriptador de Archivos
Temas: Cifrado C´esar, manejo de archivos binarios.
Enunciado: Encripta/desencripta archivos con clave num´erica.
28. Organizador de Archivos
Temas: OS module, manejo de excepciones, logs.
Enunciado: Clasifica archivos por extensi´on y genera organizacion.log.
29. Calculadora de ´Areas Geom´etricas
Temas: Funciones, constantes globales, CSV.
Enunciado: Guarda c´alculos de ´areas en areas.csv.
30. Analizador de Sentimientos B´asico
Temas: Cadenas, archivos, porcentajes.
Enunciado: Eval´ua positividad en texto y guarda en analisis.txt.
Ejercicios 31-
31. Sistema de Recomendaci´on de Pel´ıculas
Temas: Diccionarios anidados, b´usqueda lineal, JSON.
Enunciado: Recomienda pel´ıculas por g´enero y guarda historial en recomendaciones.json.
32. Calculadora de Complejidad Algor´ıtmica
Temas: Notaci´on O grande, archivos, funciones.
Enunciado: Estima complejidad de bucles y guarda ejemplos en complejidad.txt.
33. Generador de Laberintos
Temas: Matrices, recursividad, archivos.
Enunciado: Genera laberintos aleatorios y guarda en laberinto.txt.
34. Analizador de Expresiones Matem´aticas
Temas: Pilas, manejo de errores, validaci´on.
Enunciado: Eval´ua expresiones como (3+5)*2 con par´entesis balanceados.
35. Sistema de Votaciones
Temas: Listas, ordenamiento (selecci´on), CSV.
Enunciado: Simula votaciones y guarda resultados en votos.csv.
36. Simulador de Procesos de CPU
Temas: Colas, algoritmos FIFO, archivos.
Enunciado: Simula planificaci´on de procesos y genera procesos.txt.
37. Traductor Morse
Temas: Diccionarios, archivos binarios, funciones.
Enunciado: Traduce texto a Morse y viceversa, guardando en morse.bin.
38. B´usqueda de Rutas en Grafo
Temas: Matrices, Dijkstra, JSON.
Enunciado: Implementa Dijkstra para grafos peque˜nos y guarda en grafo.json.
39. Compresor de Texto RLE
Temas: Cadenas, archivos, algoritmos.
Enunciado: Comprime texto con Run-Length Encoding en comprimido.rle.
40. Juego de Memoria
Temas: Matrices, temporizador, archivos.
Enunciado: Implementa juego de memoria y guarda puntajes en puntajes.txt.
Ejercicios 41-
41. Sistema de Facturaci´on
Temas: Funciones, c´alculos matem´aticos, archivos.
Enunciado: Crea un sistema que genere facturas con:
- C´alculo de totales, descuentos e impuestos.
- Guardado en archivos con formato factura [id].txt.
- Validaci´on de inputs num´ericos.
42. B´usqueda de Patrones en ADN
Temas: Algoritmos de cadenas, archivos, JSON.
Enunciado: Busca secuencias como .ATCG.en^ adn.txt y guarda resultados en resultados adn.json.
43. Organizador de Archivos por Fecha
Temas: OS module, datetime, logs.
Enunciado: Clasifica archivos por fecha de creaci´on en carpetas YYYY-MM-DD y genera log organizacio
44. Simulador de Epidemias
Temas: Matrices, probabilidades, CSV.
Enunciado: Simula contagios en una poblaci´on y exporta datos a simulacion epidemia.csv.
45. Generador de Tablas de Verdad
Temas: L´ogica booleana, recursividad, Markdown.
Enunciado: Genera tablas para expresiones como A AND (B OR C) y guarda en tablas.md.
46. Sistema de Reservas de Hotel
Temas: Diccionarios anidados, validaci´on de fechas, archivos binarios.
Enunciado: Gestiona reservas con validaci´on de disponibilidad y guarda en reservas.dat.
47. Algoritmo de Huffman B´asico
Enunciado: Traduce pseudoc´odigo a Python y guarda en codigo generado.py.
58. Sistema de Recomendaci´on de Libros
Temas: Filtrado colaborativo, JSON, matem´aticas.
Enunciado: Recomienda libros basado en preferencias guardadas en perfiles.json.
59. Juego de Poker B´asico
Temas: Listas, aleatoriedad, archivos.
Enunciado: Implementa manos de poker y guarda historial en poker historial.txt.
60. Analizador de Sentimientos con ML B´asico
Temas: Procesamiento de lenguaje, diccionarios, CSV.
Enunciado: Clasifica texto en positivo/negativo usando diccionario sentimientos.csv y
exporta a analisis.csv.
(SOLUCIONARIO) EJERCICIOS INTEGRADORES DE
PROGRAMACION EN PYTHON
Universidad de Atacama - Facultad de Ingenieria
12 de Mayo de 2025
Soluciones 1-
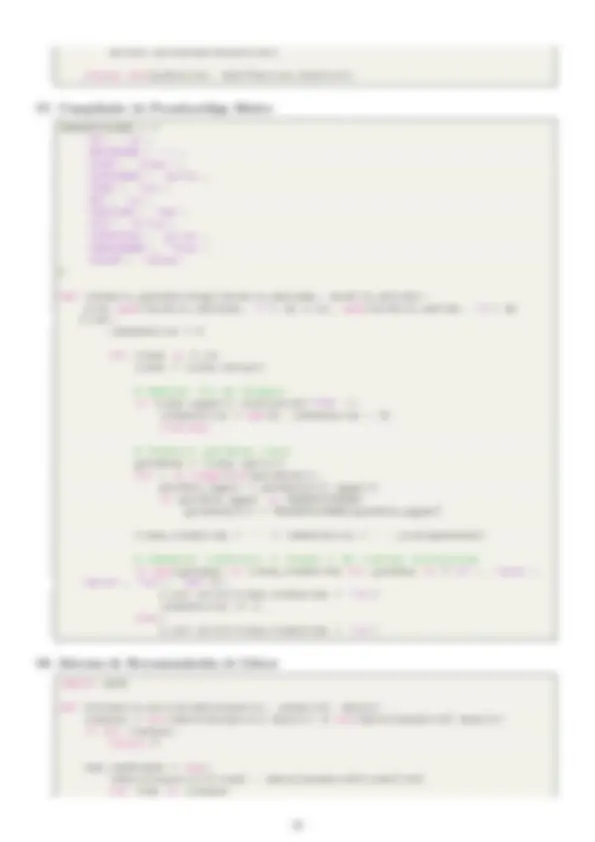
1. Gesti´on de Biblioteca
1 import json 2 3 biblioteca = [] 4 5 def agregar_libro ( titulo , autor , a o ) : 6 libro = { 7 " titulo " : titulo , 8 " autor " : autor , 9 " a o " : a o , 10 " disponible " : True 11 } 12 biblioteca. append ( libro ) 13 guardar_libros () 14 15 def buscar_por_autor ( autor ) : 16 return [ libro for libro in biblioteca if libro [ " autor " ] == autor ] 17 18 def guardar_libros () : 19 with open ( " biblioteca. json " , " w " ) as f : 20 json. dump ( biblioteca , f ) 21 22 def cargar_libros () : 23 try : 24 with open ( " biblioteca. json " , " r " ) as f : 25 return json. load ( f ) 26 except FileNotFoundError : 27 return [] 28 29 biblioteca = cargar_libros ()
2. Estad´ısticas de Texto
1 def analizar_texto ( archivo_entrada , archivo_salida ) : 2 try : 3 with open ( archivo_entrada , ’r ’) as f : 4 contenido = f. read () 5 6 lineas = contenido. split ( ’\ n ’) 7 palabras = contenido. split () 8 9 estadisticas = { 10 " palabras " : len ( palabras ) , 11 " lineas " : len ( lineas ) ,
11 12 if intento < numero : 13 print ( " Mayor " ) 14 elif intento > numero : 15 print ( " Menor " ) 16 else : 17 guardar_record ( intentos ) 18 print ( f " Correcto! Intentos : { intentos } " ) 19 break 20 21 def guardar_record ( intentos ) : 22 try : 23 with open ( " records. json " , " r " ) as f : 24 records = json. load ( f ) 25 except FileNotFoundError : 26 records = [] 27 28 records. append ( intentos ) 29 30 with open ( " records. json " , " w " ) as f : 31 json. dump ( records , f )
6. Factorial Recursivo
1 def factorial ( n ) : 2 if not isinstance (n , int ) or n < 0: 3 raise ValueError ( " Debe ser un entero positivo " ) 4 return 1 if n <= 1 else n * factorial (n -1)
7. B´usqueda en Matriz
1 import random 2 import logging 3 4 logging. basicConfig ( filename = ’ errores. log ’ , level = logging. ERROR ) 5 6 def buscar_en_matriz ( matriz , valor ) : 7 for i in range ( len ( matriz ) ) : 8 for j in range ( len ( matriz [0]) ) : 9 if matriz [ i ][ j ] == valor : 10 return (i , j ) 11 logging. error ( f " Valor { valor } no encontrado " ) 12 return None 13 14 matriz = [[ random. randint (1 , 50) for _ in range (5) ] for _ in range (5) ]
8. Agenda de Contactos
1 import json 2 3 def cargar_agenda () : 4 try : 5 with open ( " agenda. json " , " r " ) as f : 6 return json. load ( f ) 7 except ( FileNotFoundError , json. JSONDecodeError ) : 8 return {} 9 10 def guardar_agenda ( agenda ) : 11 with open ( " agenda. json " , " w " ) as f : 12 json. dump ( agenda , f ) 13 14 agenda = cargar_agenda ()
9. Cifrado C´esar
1 def cifrar_cesar ( texto , desplazamiento ) : 2 resultado = " " 3 for char in texto : 4 if char. isalpha () : 5 mayus = char. isupper () 6 char = char. lower () 7 codigo = ord ( char ) - ord ( ’a ’) 8 nuevo_codigo = ( codigo + desplazamiento ) % 26 9 char = chr ( nuevo_codigo + ord ( ’a ’) ) 10 if mayus : 11 char = char. upper () 12 resultado += char 13 return resultado
10. An´alisis de Ventas
1 from operator import itemgetter 2 3 def ordenar_ventas ( ventas ) : 4 for i in range ( len ( ventas ) ) : 5 min_idx = i 6 for j in range ( i +1 , len ( ventas ) ) : 7 if ventas [ j ][ " ventas " ] < ventas [ min_idx ][ " ventas " ]: 8 min_idx = j 9 ventas [ i ] , ventas [ min_idx ] = ventas [ min_idx ] , ventas [ i ] 10 return ventas 11 12 ventas = [{ " mes " : " Enero " , " ventas " : 1500} , { " mes " : " Febrero " , " ventas " : 2000}]
Soluciones 11-
11. Sistema de Notas Estudiantiles
1 import csv 2 3 def calcular_promedio ( estudiante ) : 4 return sum ( estudiante [ " notas " ]) / len ( estudiante [ " notas " ]) 5 6 def guardar_notas ( estudiantes , archivo ) : 7 with open ( archivo , ’w ’ , newline = ’ ’) as f : 8 writer = csv. writer ( f ) 9 writer. writerow ([ " Nombre " , " Asignatura " , " Notas " ]) 10 for est in estudiantes : 11 writer. writerow ([ est [ " nombre " ] , est [ " asignatura " ] , " ; ". join ( map ( str , est [ " notas " ]) ) ])
12. Conversor de Unidades
1 def km_a_millas ( km ) : 2 return km * 0. 3 4 def guardar_historial ( conversion ) : 5 with open ( " historial. txt " , " a " ) as f : 6 f. write ( f " { conversion }\ n " )
13. Generador de Tablas de Multiplicar
3 4 def guardar_matriz ( matriz , archivo ) : 5 with open ( archivo , ’w ’) as f : 6 for fila in matriz : 7 f. write ( " ,". join ( map ( str , fila ) ) + " \ n " )
19. Clasificador de Edades
1 def clasificar_edades ( personas ) : 2 categorias = { 3 " n i o " : [ p for p in personas if p [ " edad " ] < 13] , 4 " adolescente " : [ p for p in personas if 13 <= p [ " edad " ] < 18] , 5 " adulto " : [ p for p in personas if p [ " edad " ] >= 18] 6 } 7 return categorias
20. B´usqueda de Patrones en Texto
1 def buscar_patron ( archivo , patron ) : 2 with open ( archivo , ’r ’) as f : 3 texto = f. read () 4 return [ i for i in range ( len ( texto ) ) if texto. startswith ( patron , i ) ]
Soluciones 21-
21. Gestor de Inventario
1 import pickle 2 3 def buscar_producto ( id , productos ) : 4 low , high = 0 , len ( productos ) - 1 5 while low <= high : 6 mid = ( low + high ) // 2 7 if productos [ mid ][ ’ id ’] == id : 8 return productos [ mid ] 9 elif productos [ mid ][ ’ id ’] < id : 10 low = mid + 1 11 else : 12 high = mid - 1 13 return None 14 15 def actualizar_stock ( id , cantidad , productos ) : 16 producto = buscar_producto ( id , productos ) 17 if producto and producto [ ’ stock ’] + cantidad >= 0: 18 producto [ ’ stock ’] += cantidad 19 with open ( ’ inventario. dat ’ , ’ wb ’) as f : 20 pickle. dump ( productos , f ) 21 return True 22 return False
22. Generador de Contrase˜nas Seguras
1 import random 2 import string 3 import hashlib 4 5 def g e n e r a r _ c o n t r a s e a () : 6 caracteres = string. ascii_letters + string. digits + string. punctuation 7 while True : 8 c o n t r a s e a = ’ ’. join ( random. choice ( caracteres ) for _ in range (12) )
9 if ( any ( c. isupper () for c in c o n t r a s e a ) and
10 any ( c. islower () for c in c o n t r a s e a ) and
11 any ( c. isdigit () for c in c o n t r a s e a ) : 12 return c o n t r a s e a 13 14 def g u a r d a r _ c o n t r a s e a ( c o n t r a s e a , archivo ) : 15 with open ( archivo , ’ ab ’) as f : 16 f. write ( hashlib. sha256 ( c o n t r a s e a. encode () ). digest () )
23. Estad´ısticas de N´umeros
1 import json 2 import statistics 3 4 def calcular_estadisticas ( archivo_entrada ) : 5 with open ( archivo_entrada , ’r ’) as f : 6 numeros = [ float ( line. strip () ) for line in f ] 7 8 resultados = { 9 ’ media ’: statistics. mean ( numeros ) , 10 ’ mediana ’: statistics. median ( numeros ) , 11 ’ moda ’: statistics. mode ( numeros ) , 12 ’ numeros_ordenados ’: sorted ( numeros ) 13 } 14 15 with open ( ’ estadisticas. json ’ , ’w ’) as f : 16 json. dump ( resultados , f )
24. Juego del Tres en Raya
1 import random 2 3 def inicializar_tablero () : 4 return [[ ’ ’ for _ in range (3) ] for _ in range (3) ] 5 6 def guardar_partida ( tablero , jugador , archivo ) : 7 with open ( archivo , ’a ’) as f : 8 f. write ( f " Jugador : { jugador }\ n " ) 9 for fila in tablero : 10 f. write ( ’| ’. join ( fila ) + ’\ n ’) 11 f. write ( ’\ n ’) 12 13 def hay_ganador ( tablero ) : 14 # Verifica filas , columnas y diagonales 15 lineas = tablero + list ( zip (* tablero ) ) +
16 [[ tablero [ i ][ i ] for i in range (3) ]] +
17 [[ tablero [ i ][2 - i ] for i in range (3) ]] 18 return any ( all ( cell == ’X ’ for cell in linea ) or 19 all ( cell == ’O ’ for cell in linea ) for linea in lineas )
25. Traductor de Frases
1 import csv 2 3 def cargar_diccionario ( archivo ) : 4 with open ( archivo , mode = ’r ’) as f : 5 return { row [ ’ e s p a o l ’ ]: row [ ’ ingles ’] for row in csv. DictReader ( f ) } 6 7 def traducir_frase ( frase , diccionario ) : 8 palabras = frase. lower (). split () 9 return ’ ’. join ( diccionario. get ( palabra , ’ ??? ’) for palabra in palabras )
3 positivas = sum (1 for palabra in palabras if palabra in palabras_positivas ) 4 negativas = sum (1 for palabra in palabras if palabra in palabras_negativas ) 5 total = len ( palabras ) 6 return { 7 ’ positivas ’: positivas , 8 ’ negativas ’: negativas , 9 ’ porcentaje_positivo ’: ( positivas / total ) * 100 if total > 0 else 0 10 }
Soluciones 31-
31. Sistema de Recomendaci´on de Pel´ıculas
1 import json 2 import random 3 4 def recomendar_pelicula ( genero , peliculas ) : 5 return random. choice ( peliculas. get ( genero , []) ) 6 7 def guardar_recomendacion ( usuario , pelicula , archivo ) : 8 try : 9 with open ( archivo , ’r ’) as f : 10 historial = json. load ( f ) 11 except FileNotFoundError : 12 historial = {} 13 14 if usuario not in historial : 15 historial [ usuario ] = [] 16 historial [ usuario ]. append ( pelicula ) 17 18 with open ( archivo , ’w ’) as f : 19 json. dump ( historial , f )
32. Calculadora de Complejidad Algor´ıtmica
1 def estimar_complejidad (n , operaciones ) : 2 resultados = { 3 ’O (1) ’: 1 , 4 ’O ( log n ) ’: math. log ( n ) if n > 0 else 0 , 5 ’O ( n ) ’: n , 6 ’O ( n log n ) ’: n * math. log ( n ) if n > 0 else 0 , 7 ’O ( n ^2) ’: n 2 , 8 ’O (2^ n ) ’: 2 n 9 } 10 with open ( ’ complejidad. txt ’ , ’w ’) as f : 11 for key , value in resultados. items () : 12 f. write ( f " { key }: { value } operaciones \ n " )
33. Generador de Laberintos
1 def generar_laberinto ( filas , columnas ) : 2 laberinto = [[1 for _ in range ( columnas ) ] for _ in range ( filas ) ] 3 # Algoritmo b s i c o para crear caminos 4 for i in range (1 , filas -1) : 5 for j in range (1 , columnas -1) : 6 if random. random () > 0.7: 7 laberinto [ i ][ j ] = 0 8 return laberinto
9 10 def guardar_laberinto ( laberinto , archivo ) : 11 with open ( archivo , ’w ’) as f : 12 for fila in laberinto : 13 f. write ( ’ ’. join ([ ’# ’ if cell == 1 else ’ ’ for cell in fila ]) + ’
n ’)
34. Analizador de Expresiones Matem´aticas
1 def evaluar_expresion ( expresion ) : 2 try : 3 return eval ( expresion ) 4 except : 5 raise ValueError ( " E x p r e s i n no v l i d a " ) 6 7 def parentesis_balanceados ( expresion ) : 8 pila = [] 9 for char in expresion : 10 if char == ’( ’: 11 pila. append ( char ) 12 elif char == ’) ’: 13 if not pila : 14 return False 15 pila. pop () 16 return len ( pila ) == 0
35. Sistema de Votaciones
1 from collections import defaultdict 2 3 def contar_votos ( votos ) : 4 conteo = defaultdict ( int ) 5 for voto in votos : 6 conteo [ voto ] += 1 7 return sorted ( conteo. items () , key = lambda x : x [1] , reverse = True ) 8 9 def guardar_resultados ( resultados , archivo ) : 10 with open ( archivo , ’w ’ , newline = ’ ’) as f : 11 writer = csv. writer ( f ) 12 writer. writerow ([ ’ Candidato ’ , ’ Votos ’ ]) 13 writer. writerows ( resultados )
36. Simulador de Procesos de CPU
1 from collections import deque 2 3 def simular_fifo ( procesos ) : 4 cola = deque ( procesos ) 5 tiempo_total = 0 6 resultados = [] 7 while cola : 8 proceso = cola. popleft () 9 tiempo_total += proceso [ ’ tiempo ’] 10 resultados. append ({** proceso , ’ tiempo_final ’: tiempo_total }) 11 return resultados
37. Traductor Morse
1 MORSE = {
2 ’A ’: ’. - ’ , ’B ’: ’ -... ’ , ’C ’: ’ -. -. ’ , ’D ’: ’ -.. ’ , ’E ’: ’. ’ ,
3 ’F ’: ’ .. -. ’ , ’G ’: ’ - -. ’ , ’H ’: ’ .... ’ , ’I ’: ’ .. ’ , ’J ’: ’. - - - ’ ,
4 # Diccionario completo ...
Soluciones 41-
41. Sistema de Facturaci´on
1 import csv 2 from datetime import datetime 3 4 def generar_factura ( cliente , items , archivo ) : 5 subtotal = sum ( item [ ’ precio ’] * item [ ’ cantidad ’] for item in items ) 6 iva = subtotal * 0. 7 total = subtotal + iva 8 9 nombre_archivo = f " { archivo } _ { datetime. now (). strftime (’ %Y %m %d %H %M %S ’) }. csv " 10 11 with open ( nombre_archivo , ’w ’ , newline = ’ ’) as f : 12 writer = csv. writer ( f ) 13 writer. writerow ([ ’ Factura para : ’ , cliente ]) 14 writer. writerow ([ ’ Producto ’ , ’ Cantidad ’ , ’ Precio Unitario ’ , ’ Total ’ ]) 15 for item in items : 16 writer. writerow ([ 17 item [ ’ producto ’] , 18 item [ ’ cantidad ’] , 19 f " $ { item [ ’ precio ’]:.2 f } " , 20 f " $ { item [ ’ precio ’] * item [ ’ cantidad ’]:.2 f } " 21 ]) 22 writer. writerow ([ ’ Subtotal : ’ , ’ ’ , ’ ’ , f " $ { subtotal :.2 f } " ]) 23 writer. writerow ([ ’ IVA (16 %) : ’ , ’ ’ , ’ ’ , f " $ { iva :.2 f } " ]) 24 writer. writerow ([ ’ Total : ’ , ’ ’ , ’ ’ , f " $ { total :.2 f } " ])
42. B´usqueda de Patrones en ADN
1 def buscar_secuencia_adn ( archivo , secuencia ) : 2 with open ( archivo , ’r ’) as f : 3 adn = f. read (). replace ( ’\ n ’ , ’ ’) 4 5 posiciones = [] 6 n = len ( secuencia ) 7 for i in range ( len ( adn ) - n + 1) : 8 if adn [ i : i + n ] == secuencia : 9 posiciones. append ( i ) 10 11 resultados = { 12 ’ secuencia ’: secuencia , 13 ’ ocurrencias ’: len ( posiciones ) , 14 ’ posiciones ’: posiciones 15 } 16 17 with open ( ’ resultados_adn. json ’ , ’w ’) as f : 18 import json 19 json. dump ( resultados , f ) 20 21 return resultados
43. Organizador de Archivos por Fecha
1 import os 2 import shutil 3 from datetime import datetime 4 5 def organizar_archivos_por_fecha ( directorio ) : 6 for nombre_archivo in os. listdir ( directorio ) : 7 ruta_completa = os. path. join ( directorio , nombre_archivo )
8 9 if os. path. isfile ( ruta_completa ) : 10 fecha_modificacion = datetime. fromtimestamp ( 11 os. path. getmtime ( ruta_completa ) 12 carpeta_destino = fecha_modificacion. strftime ( " %Y- %m- %d " ) 13 14 os. makedirs ( carpeta_destino , exist_ok = True ) 15 16 shutil. move ( 17 ruta_completa , 18 os. path. join ( carpeta_destino , nombre_archivo ) 19 ) 20 21 with open ( ’ organizacion. log ’ , ’w ’) as log : 22 log. write ( f " O r g a n i z a c i n completada el { datetime. now () } " )
44. Simulador de Epidemias
1 import random 2 import csv 3 4 def simular_epidemia ( poblacion , dias , probabilidad_contagio , archivo_salida ) : 5 salud = [ ’ Sano ’] * poblacion 6 salud [0] = ’ Infectado ’ # Paciente cero 7 8 resultados = [] 9 10 for dia in range ( dias ) : 11 nuevos_infectados = 0 12 13 for i in range ( poblacion ) : 14 if salud [ i ] == ’ Infectado ’: 15 for j in range ( poblacion ) : 16 if salud [ j ] == ’ Sano ’ and random. random () < probabilidad_contagio : 17 salud [ j ] = ’ Infectado ’ 18 nuevos_infectados += 1 19 20 infectados = salud. count ( ’ Infectado ’) 21 resultados. append ({ 22 ’ dia ’: dia + 1 , 23 ’ infectados ’: infectados , 24 ’ nuevos ’: nuevos_infectados , 25 ’ sanos ’: poblacion - infectados 26 }) 27 28 with open ( archivo_salida , ’w ’ , newline = ’ ’) as f : 29 writer = csv. DictWriter (f , fieldnames = resultados [0]. keys () ) 30 writer. writeheader () 31 writer. writerows ( resultados )
45. Generador de Tablas de Verdad
1 import itertools 2 3 def generar_tabla_verdad ( variables , expresion ) : 4 combinaciones = list ( itertools. product ([ False , True ] , repeat = len ( variables ) ) ) 5 6 tabla = [] 7 for combinacion in combinaciones : 8 contexto = dict ( zip ( variables , combinacion ) )