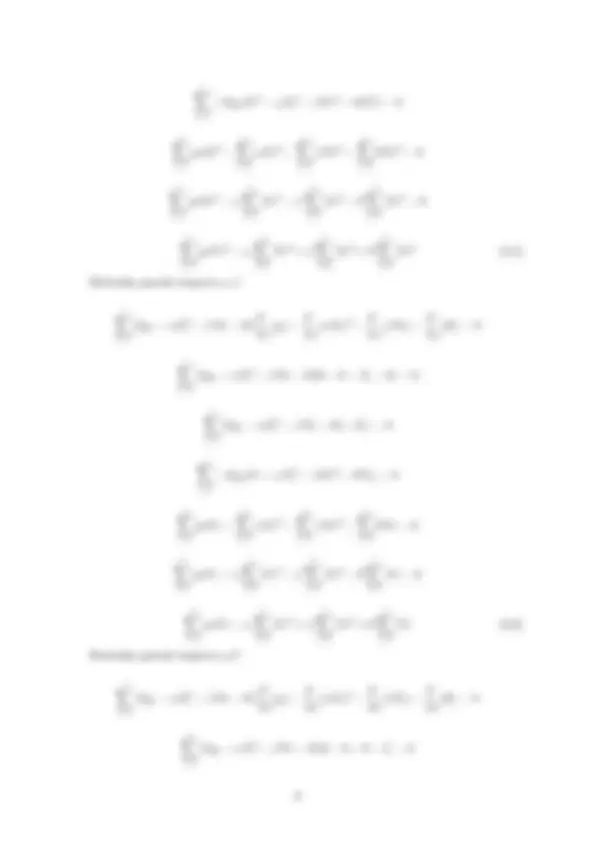¡Descarga Gradiente descendente en machine learning y más Monografías, Ensayos en PDF de Matemáticas Orientadas a las Enseñanzas Aplicadas solo en Docsity!
Gradiente descendente en machine learnig Autores José Luis Andrade Oscco. Roger Cárdenas Villano. David Abel Illanis Huaraca. Wilmer Mario Ortiz Avendaño. Samuel Quispe Aroni. José Luis Silvera Romaní. Facultad de Ingeniería, Escuela Profesional de Ingeniería sistemas, Universidad Nacional José María Arguedas La correspondencia relacionada con esta monografía debe ser dirigida a la encargada del curso de Calculo Multivariable, MG Orlando Olivares Rivera, Facultad de Ingeniería, Escuela Profesional de Ingeniería sistemas, Universidad Nacional José María Arguedas, jirón lázaro Carrillo Nº180, Andahuaylas.
Índice general
Capítulo 2
Marco Teórico
2.1. ¾Qué es el machine learning?
El machine learning es una rama de la inteligencia arti�cial que se basa en hacer aprender a la máquina siguiendo patrones, esto sin la necesidad de ser programadas anteriormente. Esto lo hará para poder realizar predicciones, para saber cómo debe actuar ante una situación o también para saber qué puede hacer en un futuro. En conclusión, el Machine learning es un maestro de las predicciones, que nos hará la vida más fácil resolviendo nuestros problemas, necesidades y liberándonos del trabajo pesado. (López C. P., 2020, pág. 20).
2.2. ¾En dónde es usado el machine learning?
El machine learning es usado y se puede usar según las necesidades de la sociedad, como puede ser en escuelas para el aprendizaje de los estudiantes, en los hospitales para la detección de las enfermedades, En la psicología donde el psicólogo es una inteligencia arti�cial, también en las empresas como el reconocimiento facial, también ya hay coches autónomos que ya no necesitan un conductor, el reconocimiento, también puede ana- lizarse sobre nuestros gustos para darnos anuncios personalizados, y entre otros. Esta tecnología ya lo vienen implementando los países desarrollados como China, EEUU, los países europeos, Japón, Australia y los resultados son impresionantes ya que mejora la calidad de vida, el nivel de educación, la e�ciencia de los trabajadores y empresas, la disminución de la delincuencia, etc. (Echaiz, y otros, 2021, pág. 50).
2.3. Tipos de Aprendizaje Automático en el Machine
Learning
2.3.1. Aprendizaje supervisado.
Se re�ere a que la máquina requiere información, es decir que lo decimos al modelo que aprenda. En este tipo de aprendizaje la Inteligencia arti�cial requiere un constante entrenamiento y recopilación de datos para poder aprender. Por lo que si no recibe datos constantemente no es capaz de aprender por sí solo. (Azuela y Cortés, 2021, pág. 57).
2.3.2. Aprendizaje no supervisado.
Es un método de aprendizaje donde un modelo se ajusta a las observaciones, a di- ferencia del aprendizaje supervisado este no necesita constantemente la recopilación de datos. Así que el aprendizaje no supervisado típicamente trata los objetos de entrada como un conjunto de variables aleatorias, siendo construido un modelo de densidad para el conjunto de datos. (Azuela y Cortés, 2021, pág. 57).
2.3.3. Aprendizaje semi-supervisado.
Es como un intermediario entre el aprendizaje supervisado y el aprendizaje no super- visado, utiliza ambos modelos de aprendizaje. En este tipo de aprendizaje puedes ingresar datos o información para que el aprendizaje de la máquina sea más rápido, pero también no es necesario la supervisión del aprendizaje de la máquina, pero su aprendizaje será lento. (Azuela y Cortés, 2021, pág. 58).
2.3.4. Aprendizaje por refuerzo.
Este tipo de aprendizaje automático está inspirado en la psicología conductista, cuya ocupación es determinar qué acciones debe escoger un agente de software en un entorno dado con el �n de maximizar alguna noción de recompensa.o^ premio acumulado. El proble- ma, por su generalidad, se estudia en muchas otras disciplinas, como la teoría de juegos, teoría de control, investigación de operaciones, teoría de la información, la optimización basada en la simulación, estadística y algoritmos genéticos. (Torres, 2021, pág. 60).
Cuadro 2.1: Distribución de pobreza en Perú
Figura 2.1: Porcentaje de Pobreza en el Perú
2005 2007 2010 2013 2015 2017 2020 Año(X)
20
25
30
35
40
45
Porcentaje(Y)
Y vs. Xuntitled fit 1
Xn i=
−2(yiXi^2 − αX i^4 − βXi^3 − θX i^2 ) = 0
X^ n i=
yiXi^2 −
X^ n i=
αXi^4 −
X^ n i=
βXi^3 −
X^ n i=
θXi^2 = 0
X^ n i=
yiXi^2 − α X^ n i=
Xi^4 − β X^ n i=
Xi^3 − θ X^ n i=
Xi^2 = 0
X^ n i=
yiXi^2 = α X^ n i=
Xi^4 + β X^ n i=
Xi^3 + θ X^ n i=
Xi^2 (2.5)
Derivada parcial respecto a β
X^ n i=
2(yi − αX i^2 − βXi − θ)[∂∂ β (yi) − ∂∂ β (αXi)^2 − ∂∂ β (βXi) − ∂∂ β (θ)] = 0
X^ n i=
2(yi − αX i^2 − βXi − θ)[0 − 0 − Xi − 0] = 0
X^ n i=
2(yi − αX i^2 − βXi − θ)[−Xi] = 0
X^ n i=
−2(yiXi − αX i^3 − βXi^2 − θXi) = 0
X^ n i=
yiXi −
X^ n i=
αXi^3 −
X^ n i=
βXi^2 −
X^ n i=
θXi = 0
X^ n i=
yiXi − α X^ n i=
Xi^3 − β X^ n i=
Xi^2 − θ X^ n i=
Xi = 0
X^ n i=
yiXi = α X^ n i=
Xi^3 + β X^ n i=
Xi^2 + θ X^ n i=
Xi (2.6)
Derivada parcial respecto a θ
X^ n i=
2(yi − αX i^2 − βXi − θ)[∂∂ θ (yi) − ∂∂ θ (αXi)^2 − ∂∂ θ (βXi) − ∂∂ θ (θ)] = 0
X^ n i=
2(yi − αX i^2 − βXi − θ)[0 − 0 − 0 − 1] = 0
Xn i=
2(yi − αX i^2 − βXi − θ)[−1] = 0
X^ n i=
−2(yi − αX i^2 − βXi − θ) = 0
X^ n i=
yi − X^ n i=
αXi^2 − X^ n i=
βXi − X^ n i=
θ = 0
X^ n i=
yi − α X^ n i=
Xi^2 − β X^ n i=
Xi^2 − θ X^ n i=
X^ n i=
yi = α X^ n i=
Xi^2 + β X^ n i=
Xi^2 + θn (2.7) Formamos Sistema de ecuación. de ecuaciones anteriores (2.5),(2.6) y (2.7)
Pn i=1 yiXi^2 =^ α^
Pn i=1 Xi^4 +^ β^
Pn i=1 Xi^3 +^ θ^
Pn P i=1^ Xi^2 ni=1 yiXi = α Pni=1 Xi (^3) + β Pni=1 Xi (^2) + θ Pni=1 Xi Pn i=1 yi^ =^ α^
Pn i=1 Xi^2 +^ β^
Pn i=1 Xi^2 +^ θn
Hallamos α,β y θ por método de Cramer
|D| =
P (^) Xi 4 P (^) Xi 3 P (^) Xi 2 P (^) Xi 3 P (^) Xi 2 P (^) Xi P (^) Xi 2 P (^) Xi n
|D| =
X
Xi^4
n
X
Xi^2 −
hX Xi
i 2 � −
X
Xi^3
n
X
Xi^3 −
X
Xi^2
X
Xi
X
Xi^2
�X
Xi^3
X
Xi −
hX Xi
i 2 � (2.8)
|Dα| =
P (^) yiXi 2 P (^) Xi 3 P (^) Xi 2 P (^) yiXi P (^) Xi 2 P (^) Xi P (^) yi P (^) Xi n
X y yX yX^2 X^2 X^3 X^4 2005 44.60 89423.00 179293115.0 4020025 8060150125 1.61606E+ 2006 43.80 87862.80 176252776.8 4024036 8072216216 1.61929E+ 2007 42.40 85096.80 170789277.6 4028049 8084294343 1.62252E+ 2008 37.30 74898.40 150395987.2 4032064 8096384512 1.62575E+ 2009 33.50 67301.50 135208713.5 4036081 8108486729 1.62899E+ 2010 30.80 61908.00 124435080.0 4040100 8120601000 1.63224E+ 2011 27.80 55905.80 112426563.8 4044121 8132727331 1.63549E+ 2012 25.80 51909.60 104442115.2 4048144 8144865728 1.63875E+ 2013 23.90 48110.70 96846839.1 4052169 8157016197 1.64201E+ 2014 22.70 45717.80 92075649.2 4056196 8169178744 1.64527E+ 2015 21.80 43927.00 88512905.0 4060225 8181353375 1.64854E+ 2016 20.70 41731.20 84130099.2 4064256 8193540096 1.65182E+ 2017 21.70 43768.90 88281871.3 4068289 8205738913 1.6551E+ 2018 20.54 41449.72 83645535.0 4072324 8217949832 1.65838E+ 2019 20.20 40783.80 82342492.2 4076361 8230172859 1.66167E+ 2020 30.10 60802.00 122820040.0 4080400 8242408000 1.66497E+ 32200 467.64 940597.02 1891899060 64802840 1.30417E+11 2.62469E+ Cuadro 2.2: Tabla de calculos de la la sumatoria
α = D Dα = 31073280 6451678 = 0, 20762784 (2.15) β = D Dβ = −^2601628723231073280 = − 837 , 2559071 (2.16) θ = D Dθ =^2 ,^6228231073280 E^ + 13 = 844077, 1259 (2.17) Y i = αXi^2 + βXi + θ Finalmente se obtiene la siguiente función
Y i = f (X) = 0, 20762784 Xi^2 − 837 , 255907 Xi + 844077, 1259 (2.18)
Ahora como ya conocemos nuestra función modelizada podemos calcular para tal periodo
2.8. ejemplo aplicativo
Ejemplo 1:
¾Se desea calcular cual era el pocentaje de pobreza en el año 2002 y además cuál será el porcentaje en el año 2024? y comparar el resultado. si X = 2002 reemplazamos en la funcion obtenida.
f (2002) = 0,20762784(2002)^2 − 837 ,255907(2002) + 844077, 1259 f (2002) = 64, 01 si X = 2024 reemplazamos en la funcion obtenida.
f (2024) = 0,20762784(2002)^2 − 837 ,255907(2002) + 844077, 1259 f (2024) = 34, 39 En el año 2002 se puede apreciar que el porcentaje de pobreza en el perú era de 34. en porcentajes esto se debió a varios factores la inestabilidad económica, falta de inversión y sobre todo por el terrorismo que ha asotado nuestro país. Ahora en el 2024 hay un ligero incremento de pobreza en el perú esto se debería de ver con mucha preocupación por que se no toma acciones para poder bajar la brecha puede traer muchas consecuencias negativas. y por ulttimo resaltamos que tan importante es conocer la aplicación de machine learning nos ayuda tomar decisiones frente a situaciones adversas nos pronostica y así podemos prevenir muchas cosas.
Capítulo 4
Bibliografía
@bookinbook, author = Azuela, J. H., y Cortés, F. R. title = Robótica y Automatización booktitle = nteligencia arti�cial aplicada a Robótica y Automatización, date = 01 de marzo del 2021, OPTeditora = alfaomega Grupo editor S.A. @bookinbook, author = Thomas.B.T.G title = Cálculo. Una variable booktitle = calculo-una-variable-thomas-13-edicionpdf-compress.pdf date = 03 de enero del 2015 @bookinbook, author = Echaiz, Flores, L., Neupane, Bhanu, Lam, R., Macarena, title = El Aporte de la Inteligencia Arti�cial y las TIC Avanzadas a las Sociedades del Conocimiento, booktitle = El Aporte de la Inteligencia Arti�cial , date = 2021, OPTeditora = Madrid: UNESCO Publishing, @bookinbook, author = james stewart, title = Robótica y Automatización, booktitle = CÁLCULO DE UNA VARIABLE TRASCENDENTES TEMPRANAS, date = 2003, @bookinbook, author = López, C. P., title = Sistemas de aprendizaje automático machine learning., date = 2020, OPTeditora = Garceta Grupo Editorial, @bookinbook, author = López, R. F., y Fernández, J. M., title = Las Redes Neuronales Arti�ciales., date = 2008, OPTeditora = Editorial Netbiblo, @bookinbook, author = Torres, J., title = Introducción al aprendizaje por refuerzo profundo., booktitle = Teoría y práctica en Python, date = 2021,
Capítulo 5
Anexos
Figura 5.1: Anexo 1