



Sección Departamental de Estadística e I.O. II. EUEE
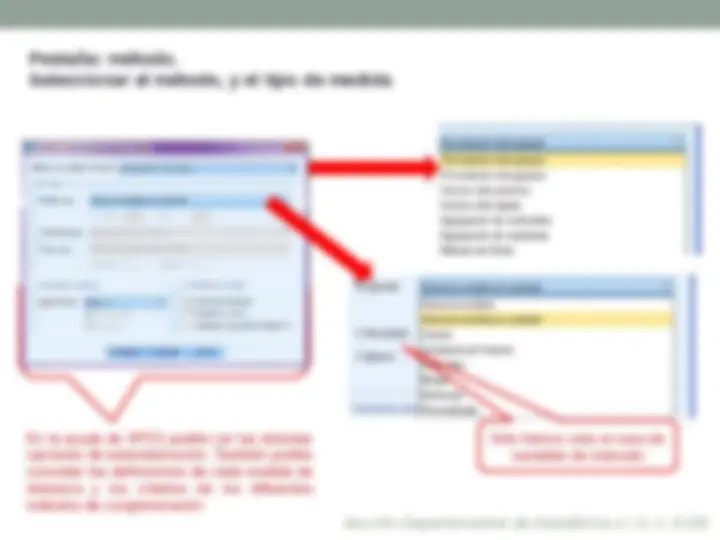
Nota: previo al análisis, tipificar variables
Analizar: estadísticos descriptivos: descriptivos
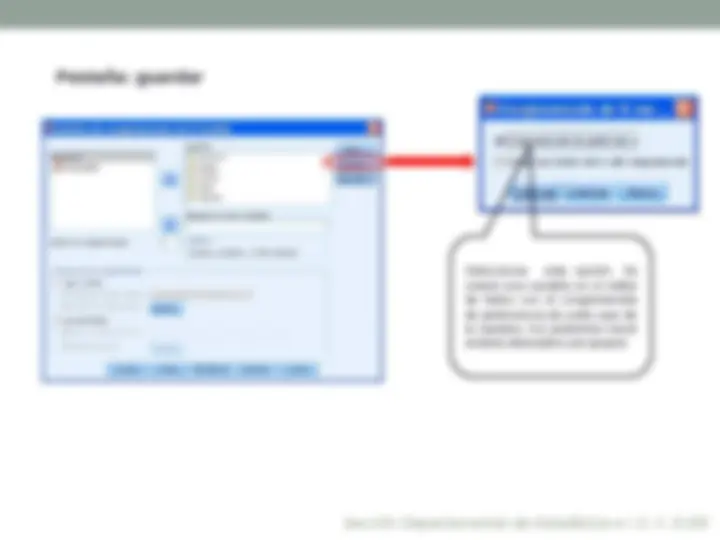
Importante: guardar como variables




Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
Asignatura: ANALISIS DE DATOS E INFERENCIA, Profesor: adolfo hernández, Carrera: Comercio, Universidad: UCM
Tipo: Guías, Proyectos, Investigaciones
1 / 13

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
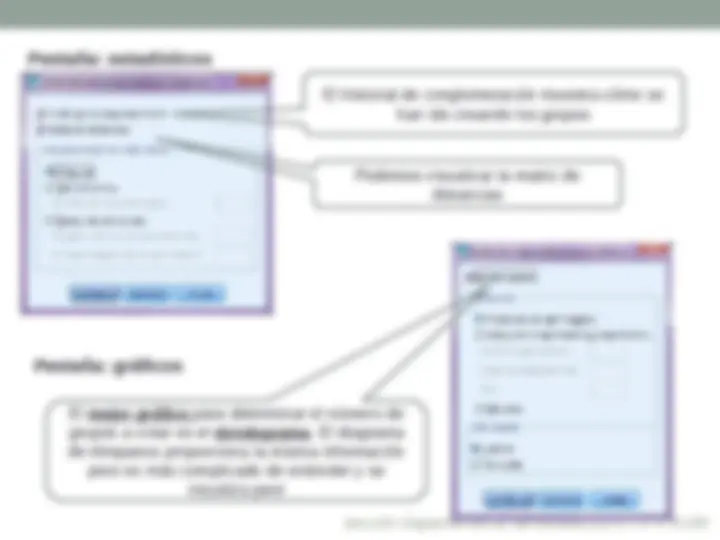
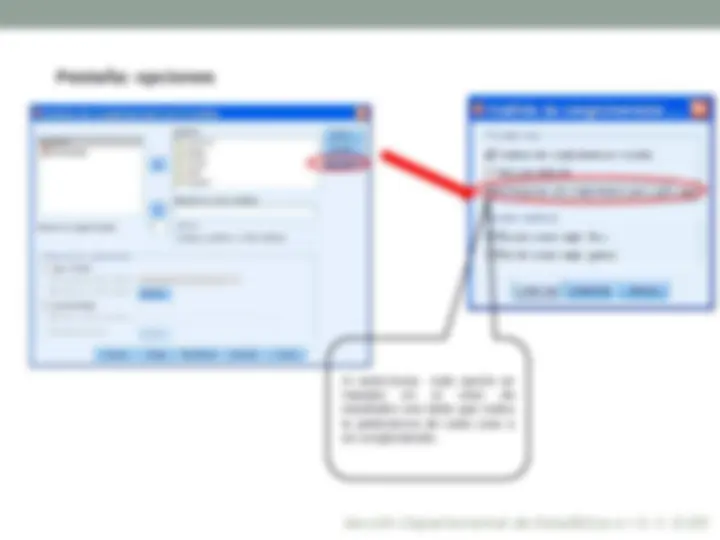
Limita el número de iteraciones en el algoritmo k-medias. La iteración se detiene después de este número de iteraciones, incluso si no se ha satisfecho el criterio de convergencia. Este número debe estar entre el 1 y el 999. Consejo, utilizar un valor alto (999) Permite solicitar la actualización de los centros de los conglomerados tras la asignación de cada caso. Si no selecciona esta opción, los nuevos centros de los conglomerados se calcularán después de la asignación de todos los casos. Marcarla
Seleccionar esta opción. Se creará una variable en el editor de datos con el conglomerado de pertenencia de cada caso de la muestra. Así podremos hacer análisis descriptivo por grupos