¡Descarga manual spss tema 5 y más Apuntes en PDF de Estadística Inferencial solo en Docsity!
Tema 5- Manual SPSS
Tablas de contingencia
El procedimiento Tablas de contingencia crea tablas de clasificación doble y múltiple y, además, proporciona una serie de pruebas y medidas de asociación para las tablas de doble clasificación.
La estructura de la tabla y el hecho de que las categorías estén ordenadas o no determinan las pruebas o medidas que se utilizaban.
Los estadísticos de tablas de contingencia y las medidas de asociación sólo se calculan para las tablas de doble clasificación. Si especifica una fila, una columna y un factor de capa (variable de control), el procedimiento Tablas de contingencia crea un panel de medidas y estadísticos asociados para cada valor del factor de capa (o una combinación de valores para dos o más variables de control). Por ejemplo, si sexo es un factor de capa para una tabla de casado (sí, no) en función de vida (vida emocionante, rutinaria o aburrida), los resultados para una tabla de doble clasificación para las mujeres se calculan de forma independiente de los resultados de los hombres y se imprimen en paneles uno detrás del otro.
Ejemplo. ¿Es más probable que los clientes de las empresas pequeñas sean más rentables en la venta de servicios (por ejemplo, formación y asesoramiento) que los clientes de las empresas grandes? A partir de una tabla de contingencia podría deducir que la prestación de servicios a la mayoría de las empresas pequeñas (con menos de 500 empleados) produce considerables beneficios, mientras que con la mayoría de las empresas de gran tamaño (con más de 2.500 empleados), los beneficios obtenidos son mucho menores.
Estadísticos y medidas de asociación. Chi-cuadrado de Pearson, chi-cuadrado de la razón de verosimilitud, prueba de asociación lineal por lineal, prueba exacta de Fisher, chi-cuadrado corregido de Yates, r de Pearson, rho de Spearman, coeficiente de contingencia, phi, V de Cramér, lambdas simétricas y asimétricas, tau de Kruskal y Goodman, coeficiente de incertidumbre, gamma, d de Somers, tau- b de Kendall, tau- c de Kendall, coeficiente eta, kappa de Cohen, estimación de riesgo relativo, razón de ventajas, prueba de McNemar y estadísticos de Cochran y Mantel-Haenszel.
Datos. Para definir las categorías de cada variable, utilice valores de una variable numérica o de cadena (ocho bytes o menos). Por ejemplo, para sexo , podría codificar los datos como 1 y 2 o como varón y mujer.
Supuestos. En algunos estadísticos y medidas se asume que hay unas categorías ordenadas (datos ordinales) o unos valores cuantitativos (datos de intervalos o de proporciones), como se explica en la sección sobre los estadísticos. Otros estadísticos son válidos cuando las variables de la tabla tienen categorías no ordenadas (datos nominales). Para los estadísticos basados en chi-cuadrado (phi, V de Cramér y coeficiente de contingencia), los datos deben ser una muestra aleatoria de una distribución multinomial.
Nota : Las variables ordinales pueden ser códigos numéricos que representen categorías (por ejemplo, 1 = bajo , 2 = medio , 3 = alto ) o valores de cadena. Sin embargo, se supone que el orden alfabético de los valores de cadena indica el orden correcto de las categorías. Por ejemplo, en una variable de cadena cuyos valores sean bajo , medio , alto , se interpreta el orden de las categorías como alto , bajo , medio (orden que no es el correcto). Por norma general, se puede indicar que es más fiable utilizar códigos numéricos para representar datos ordinales.
Para obtener tablas de contingencia
Seleccione en los menús:
Analizar > Estadísticos descriptivos > Tablas de contingencia...
Figura 5-1 Cuadro de diálogo Tablas de contingencia
Seleccione una o más variables de fila y una o más variables de columna.
Si lo desea, puede:
- Seleccionar una o más variables de control.
La vista seleccionada de la tabla de contingencia muestra los estadísticos de participantes que tienen un título universitario.
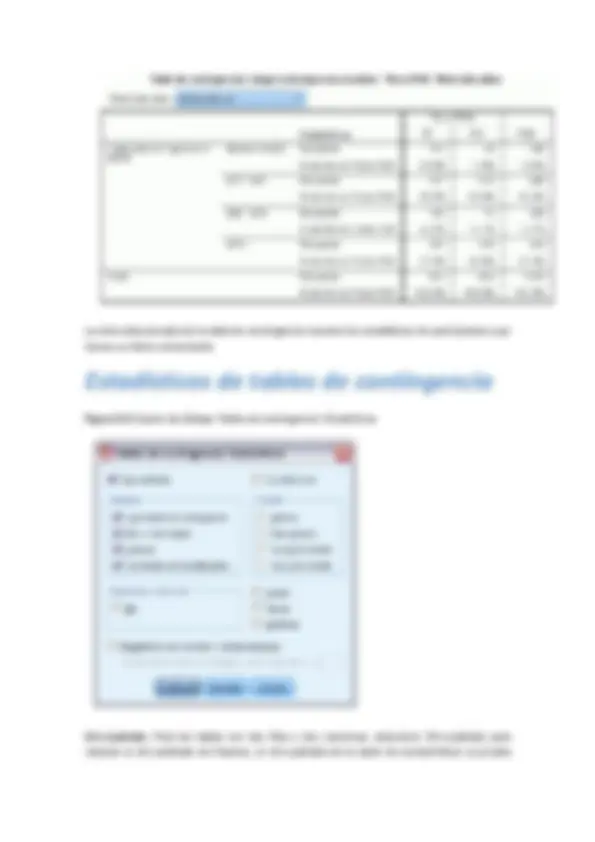
Estadísticos de tablas de contingencia
Figura 5-3 Cuadro de diálogo Tablas de contingencia: Estadísticos
Chi-cuadrado. Para las tablas con dos filas y dos columnas, seleccione Chi-cuadrado para calcular el chi-cuadrado de Pearson, el chi-cuadrado de la razón de verosimilitud, la prueba
exacta de Fisher y el chi-cuadrado corregido de Yates (corrección por continuidad). Para las tablas 2 × 2, se calcula la prueba exacta de Fisher cuando una tabla (que no resulte de perder columnas o filas en una tabla mayor) presente una casilla con una frecuencia esperada menor que 5. Para las restantes tablas 2 × 2 se calcula el chi-cuadrado corregido de Yates. Para las tablas con cualquier número de filas y columnas, seleccione Chi-cuadrado para calcular el chi- cuadrado de Pearson y el chi-cuadrado de la razón de verosimilitud. Cuando ambas variables de tabla son cuantitativas, Chi-cuadrado da como resultado la prueba de asociación lineal por lineal.
Correlaciones. Para las tablas en las que tanto las columnas como las filas contienen valores ordenados, Correlaciones da como resultado rho, el coeficiente de correlación de Spearman (sólo datos numéricos). La rho de Spearman es una medida de asociación entre órdenes de rangos. Cuando ambas variables de tabla (factores) son cuantitativas, Correlaciones da como resultado r , el coeficiente de correlación de Pearson, una medida de asociación lineal entre las variables.
Nominal. Para los datos nominales (sin orden intrínseco, como católico, protestante o judío), puede seleccionar el Coeficiente de contingencia, Phi (coeficiente) y V de Cramér, Lambda (lambdas simétricas y asimétricas y tau de Kruskal y Goodman) y el Coeficiente de incertidumbre.
Coeficiente de contingencia. Medida de asociación basada en chi-cuadrado. El valor varía entre 0 y 1. El valor 0 indica que no hay asociación entre las variables de fila y de columna. Los valores cercanos a 1 indican que hay gran relación entre las variables. El valor máximo posible depende del número de filas y columnas de la tabla. Phi y V de Cramer. Phi es una medida de asociación basada en chi-cuadrado que conlleva dividir el estadístico de chi-cuadrado por el tamaño de la muestra y extraer la raíz cuadrada del resultado. V de Cramer es una medida de asociación basada en chi- cuadradro. L ambda. Medida de asociación que refleja la reducción proporcional en el error cuando se utilizan los valores de la variable independiente para pronosticar los valores de la variable dependiente. Un valor igual a 1 significa que la variable independiente pronostica perfectamente la variable dependiente. Un valor igual a 0 significa que la variable independiente no ayuda a pronosticar la variable dependiente. Coeficiente de incertidumbre. Medida de asociación que refleja la reducción proporcional en el error cuando se utilizan los valores de una variable para pronosticar los valores de la otra variable. Por ejemplo, un valor de 0,83 indica que el conocimiento de una variable reduce en un 83% el error al pronosticar los valores de la otra variable. El programa calcula tanto la versión simétrica como la asimétrica del coeficiente de incertidumbre.
Ordinal. Para las tablas en las que tanto las filas como las columnas contienen valores ordenados, seleccione Gamma (orden cero para tablas de doble clasificación y condicional para tablas cuyo factor de clasificación va de 3 a 10), Tau-b de Kendall y Tau-c de Kendall. Para pronosticar las categorías de columna de las categorías de fila, seleccione d de Somers.
factor es poco común, se puede utilizar la razón de las ventajas como estimación o riesgo relativo.
McNemar. Prueba no paramétrica para dos variables dicotómicas relacionadas. Contrasta los cambios de respuesta utilizando una distribución chi-cuadrado. Es útil para detectar cambios en las respuestas causadas por la intervención experimental en los diseños del tipo "antes- después". Para las tablas cuadradas de mayor orden se informa de la prueba de simetría de McNemar-Bowker.
Estadísticos de Cochran y de Mantel-Haenszel. Los estadísticos de Cochran y de Mantel- Haenszel se pueden utilizar para comprobar la independencia entre una variable de factor dicotómica y una variable de respuesta dicotómica, condicionada por los patrones en las covariables, que vienen definidos por la variable o variables de las capas (variables de control). Tenga en cuenta que mientras que otros estadísticos se calculan capa por capa, los estadísticos de Cochran y Mantel-Haenszel se calculan una sola vez para todas las capas.
Visualización en casillas de tablas de contingencia
Figura 5-4 Cuadro de diálogo Tablas de contingencia: Mostrar en las casillas
Para ayudarle a descubrir las tramas en los datos que contribuyen a una prueba de chi- cuadrado significativa, el procedimiento Tablas de contingencia muestra las frecuencias esperadas y tres tipos de residuos (desviaciones) que miden la diferencia entre las frecuencias observadas y las esperadas. Cada casilla de la tabla puede contener cualquier combinación de recuentos, porcentajes y residuos seleccionados.
Recuentos. El número de casos realmente observados y el número de casos esperados si las variables de fila y columna son independientes entre sí.
Comparar las proporciones de columna. Esta opción calcula comparaciones por pares de proporciones de columnas e indica los pares de columnas (de una fila concreta) que son significativamente diferentes. Las diferencias significativas se indican en la tabla de contingencia con formato de estilo APA utilizando subíndices de letras y se calculan con un nivel de significación de 0,05.
Corregir valores p (método de Bonferroni). Las comparaciones por parejas de las proporciones de columnas utilizan la corrección de Bonferroni, que ajusta el nivel de significación observado por el hecho de que se realizan múltiples comparaciones.
Porcentajes. Los porcentajes se pueden sumar a través de las filas o a lo largo de las columnas. También se encuentran disponibles los porcentajes del número total de casos representados en la tabla (una capa).
Residuos. Los residuos brutos no tipificados presentan la diferencia entre los valores observados y los esperados. También se encuentran disponibles los residuos tipificados y tipificados corregidos.
No tipificados. Diferencia entre el valor observado y el valor esperado. El valor pronosticado es el número de casos que se esperaría encontrar en la casilla si no hubiera relación entre las dos variables. Un residuo positivo indica que hay más casos en la casilla de los que habría en ella si las variables de fila y columna fueran independientes. Tipificados. El residuo dividido por una estimación de su error típico. Los residuos tipificados, que son conocidos también como los residuos de Pearson o residuos estandarizados, tienen una media de 0 y una desviación típica de 1. Tipificados corregidos. El residuo de una casilla (el valor observado menos el valor pronosticado) dividido por una estimación de su error típico. El residuo tipificado resultante viene expresado en unidades de desviación típica, por encima o por debajo de la media.
Ponderaciones no enteras. Los recuentos de las casillas suelen ser valores enteros, ya que representan el número de casos de cada casilla. Sin embargo, si el archivo de datos está ponderado en un momento determinado por una variable de ponderación con valores fraccionarios (por ejemplo, 1,25), los recuentos de las casillas pueden que también sean valores fraccionarios. Puede truncar o redondear estos valores antes o después de calcular los recuentos de las casillas o bien utilizar recuentos de casillas fraccionarios en la presentación de las tablas y los cálculos de los estadísticos.