


1
MEDIDAS DE
VARIABILIDAD
PROFESOR: ROLAND
ALCANTARA R.
Rango
Rango intercuartil
Variancia
Desviación estándar
Coeficiente de variabilidad























Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
Estos son definiciones de las medidas de variabilidad incluyendo ejercicios de ejemplo
Tipo: Diapositivas
Subido el 19/09/2023
1 documento
1 / 31

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Introduccion
Importancia de una medida
de dispersión
3
1
Desviación estándar
s Varianza
i i
i i
d X
2 2 2
2 2
6 puntos ; 6 puntos
Y Y
Las notas de dos estudiantes X e y en cierto curso son:
X: 12, 13 y 14; Y: 10, 13 y 16
Ejemplo:
2 2 2
2 2
puntos ; puntos
X X
Ejemplo
Sueldo de los
empleados de la
compañía ABC
Sueldo de los
gerentes de la
compañía ABC
Media
Desv Est
Coef Var
¿Cuando se considera que
una observación es un
outliers?
i
1
3
Simetría y Asimetría
MEDIDA DE ASIMETRÍA
Distribución simétrica: Cuando su curva de frecuencia es
simétrica con respecto al centro de los datos, en este caso
=Me=Mo.
16
3( )
s
Me Mo
A
O
S
Observación:
s
= 0 distribución simétrica
s
< 0 distribución asimétrica
negativa
s
0 distribución asimétrica
Curtosis
El Coeficiente de Curtosis analiza el grado de
concentración que presentan los valores alrededor
de la zona central de la distribución.
Leptocúrtica Platicúrtica
Mesocúrtica
K
u
> 0,263 K
u
= 0,
K
u
< 0,
2 ( ) 2 ( )
90 10
75 25
9 1
3 1
P P
P P
D D
Q Q
K
U
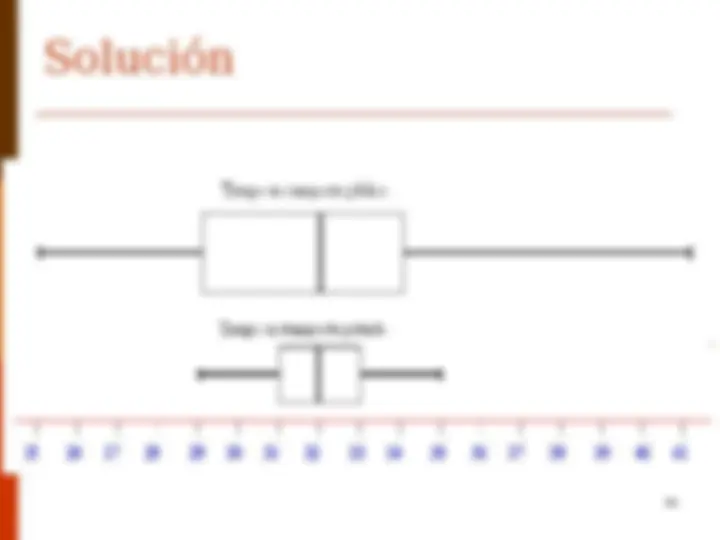
Diagrama de caja
Un diagrama de caja es una gráfica que describe la
distribución de un conjunto de datos tomando como
referencia los valores de los cuartiles como medida
de posición y el valor del rango intercuartil como
medida de referencia de dispersión.
20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
Resistencia
Diagrama de caja de la Resistencia
Diagramas de cajas
Permite:
Comparar las
medianas de dos o mas
conjuntos de datos.
Observar el tipo de
distribución de los datos
(simétrica o
asimétrica).
Determinar la
dispersión en el 50%
central de los datos.
Identificar la presencia
de valores extremos
(datos atípicos)