


a.s. 2023/2024
Mod. 1

























































































Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
Appunti completi del corso di Bioinformatica completi di teoria ed esercitazioni pratiche.
Tipologia: Appunti
1 / 132

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
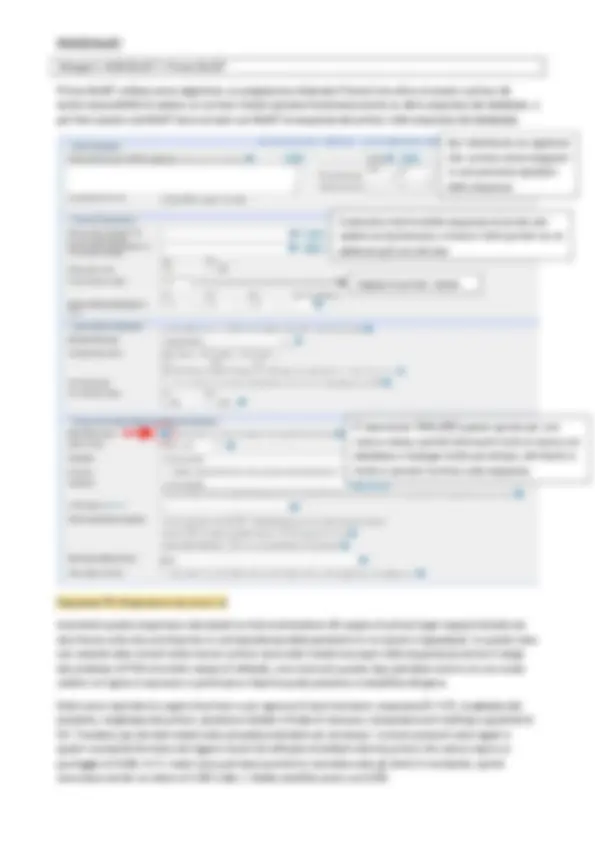
BIOINFORMATICA, Lezione 1 (26/09/2023)
INTRODUZIONE ALLA BIOINFORMATICA
Nel 2013 si sono celebrati i 60 anni dalla scoperta della struttura del DNA, i 30 anni dalla scoperta della PCR e 10 dalla chiusa del Progetto Genoma Umano. Siamo nel 2023, gli anni sono aumentati ma possiamo comunque celebrare questi importanti traguardi della biologia.
Prima del 1953 ancora non si conosceva la struttura del DNA, né si sapeva cosa facesse questa gran quantità di DNA che veniva ritrovata nelle cellule. Avevano scoperto per caso che la quantità di A e T e di C e G presente era la stessa ma non c’erano altre informazioni a riguardo.
Watson era un dottorando americano di soli 22 anni e fa una scoperta che cambia la storia della biologia, insieme a Crick. Una volta scoperta la struttura della molecola di DNA tutti gli altri scienziati che lavoravano a riguardo immediatamente capiscono la funzione di questa molecola (trascrizione, traduzione, sintesi delle proteine…): la struttura spiegava la funzione.
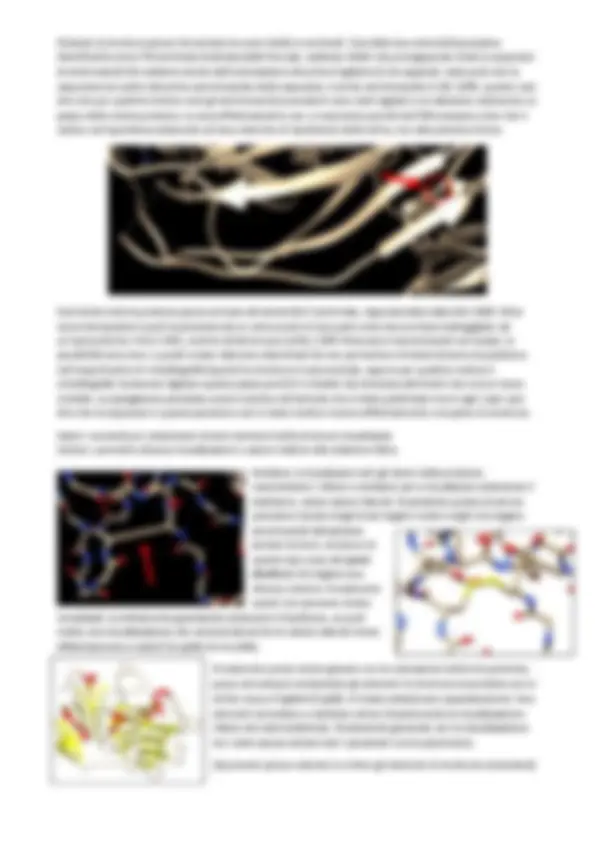
Gli esperimenti di rifrazioni sulle fibre di DNA erano condotti da Rosalind Franklin che ottenne l’immagine dalla rifrazione a raggi X ma muore poco prima di ottenere il Nobel per questa scoperta.
Nel 1970 iniziano tutta una serie di attività estese relative al sequenziamento: si sapeva che c’era una stretta relazione tra funzione e struttura e si voleva quindi capire bene la relazione tra DNA, proteine ecc. Uno dei primi sequenziamenti fu quello dell’RNA 5.8 S del Saccharomyces cerevisiae , ottenuto con metodi chimici in seguito a circa 2 anni di lavoro, il processo era infatti molto molto lento.
Questa immagine mostra un E. Coli che è stato fatto esplodere (con stress osmotico) portando al rilascio del DNA: si può così ben osservare la lunghezza di questa molecola di ben 4.7x10^6 paia di basi. Calcolando la distanza tra le diverse basi si ottiene una molecola lunga 1.5mm. Con i tempi di allora il sequenziamento dell’intero genoma sarebbe stato infattibile, per fortuna però la biologia fece passi in avanti molto rapidamente.
Kary B. Mullis inventa infatti la PCR, tecnica che permette l’amplificazione del materiale genetico, ed ottiene il premio Nobel per la chimica nel 1983. Da qui c’è uno sviluppo enorme delle tecnologie che portano a macchine per il sequenziamento enormemente più veloci che permettono di ottenere in pochi secondi quello che era stato prima sequenziato in 2 interi anni.
Nel 2000 circa alcuni personaggi intuiscono l’importanza dello studio del genoma umano, instituendo un gruppo composto da una serie di personaggi importanti (tra cui lo stesso Watson) con lo scopo del sequenziamento dell’intero genoma umano. Progetto che si è chiuso nel 2003 con la lettura dell’intero genoma resa possibile da un’enorme riduzione dei costi e dei macchinari per il sequenziamento. La conoscenza del genoma è ovviamente importantissima per la mole di informazioni che consente di ottenere. L’intero genoma umano è di circa 6x10^9 paia di basi (circa 1000 volte di più di quello di E. Coli); dimensioni maggiori implicano una maggior quantità di dati con cui avere a che fare.
Attualmente conosciamo l’intero contenuto del genoma umano, ma cosa ci facciamo? Ci lavora chi è in grado di poter lavorare grandi quantità di dati con approcci di tipo statistico, matematico e informatico. Una volta letto il genoma umano sono iniziati progetti volti a scoprire il genoma di qualsiasi tipo di
tecniche, tuttavia se gli esperimenti non sono così performanti e veloci si possono tentare delle strade informatiche che permettono di arrivare ad una probabile struttura delle proteine sulla base del calcolo (da strutture omologhe o con tecniche ab initio ).
Valutando una serie di proteine note si osserva che ci sono diversi fold ricorrenti e esistono attualmente dei sistemi (alpha fold) che lavorando su una serie di strutture note hanno sviluppato un’intelligenza tale da arrivare a determinare le strutture di nuove proteine. Attualmente i numeri di strutture proposte sono altissimi e è statto dichiarato che questi devono attualmente essere considerati come dati artificiali e quindi da validare e verificare.
BIOINFORMATICA, Lezione 2 (3/10/2023)
BANCHE DATI
Nel 1965 viene assemblato il primo database di sequenze proteiche, trasformato poi in versione elettronica. Nel 1982 si ha il primo database di sequenze del DNA (GenBank), successivamente anche in Europa (EMBL) e in Giappone (DDBJ) furono instituite altre banche dati, tutte in comunicazione tra loro. Nella seconda metà degli anni ’80 si realizzano le prime banche dati specializzate come il Protein Data Bank (PDB).
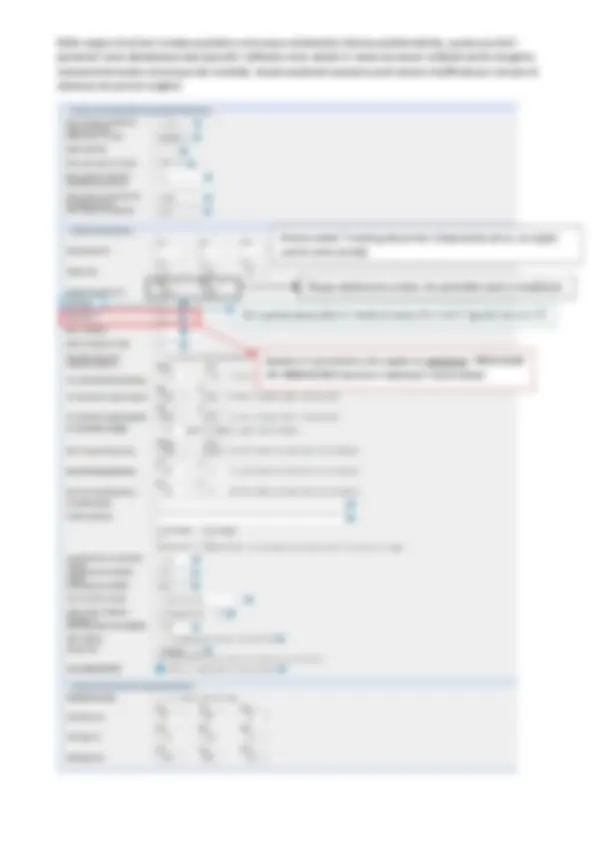
In contemporanea alla nascita delle banche dati sono state sviluppate anche delle metodologie computazionali. Nel 1970 viene pubblicato il primo algoritmo per l’allineamento globale (ovvero riguardo l’intera lunghezza) di sequenze del DNA. Algoritmi di questo tipo vengono definiti di programmazione dinamica. Nel 1971 viene invece descritto un metodo per allineare due sequenze chiamato dot matrix (di cui parleremo più avanti). Nel 1981 ilprecedente algoritmo globale venne modificato in modo da considerare anche i massimi locali: questo è estremamente importante perché molte volte permette di identificare dei domini funzionali che un allineamento globale non mette in luce perché disturbato da regioni confinanti prive di importanza e quindi poco conservate. Vennero poi sviluppati nel 1986 anche aallineamenti multipli di sequenza.
Allineare le sequenze è di fondamentale importanza perché il confronto ci permette di ottenere informazioni sulla struttura e sulla funzione di una proteina. Si può poi risalire all’evoluzione delle sequenze (studi filogenetici).
In questo multiallineamento (con gli stessi organismi nei due blocchi) è molto facile visualizzare l’allineamente nel blocco inferiore dove molte regioni sono conservate, cosa che invece non ritroviamo nella porzione mostrata nella parte superiore.
ancestrale. Abbiamo solo la somma tra gli step X e gli step Y che hanno portato alla diversificazione di quella ipotetica sequenza ancestrale, ovvero il numero di mismatches nell’allineamento delle due sequenze. In un’analisi filogenetica si può stimare la distanza dall’antenato comunque ma se e solamente se le sequenze sono omologhe.
Cosa determina la similarità tra geni?
Nell’immagine si vede che viene effettuato uno scorrimento progressivo delle due sequenze una sull’altra determinando un punteggio score dopo ogni step. Lo score più elevato si ottiene a livello della casella con il numero più elevato di corrispondenze. Tuttavia uno scorrimento di questo tipo non considera i gap ed è quindi semplificato.
Nell’allineare proteine o acidi nucleici bisogna tenere in considerazione il fatto che l’allineamento migliore potrebbe essere ottenuto inserendo dei gap che corrispondono a fenomeni evolutivi di inserzione o delezione.
È una tipologia di allineamento tra due sequenze (rappresentate sui due assi) in cui viene rappresentato un quadratino nero ogni volta che si ha una corrispondenza. Permette di caratterizzare una sequenza in maniera tale da visualizzare ipotetiche presenze di tratti duplicati, delezioni o in generale ogni volta che si vuole avere una caratterizzazione di una sequenza a grandi linee.
È una matrice costituita da n righe e m colonne che corrispondono alla lunghezza delle due sequenze da analizzare. Si ottiene una visualizzazione grafica di tutti i possibili allineamenti visualizzati da una diagonale che parte in alto a sinistra e arriva in basso a destra.
Ad esempio in questo specifico caso si vede che la prima A potrebbe allinearsi con tre diverse A presenti nell’altra sequenza (cerchiate in rosso). In generale osservando ciascuna diagonale osservo tutti i possibili allineamenti e posso determinare il migliore (quello che dà il maggior numero di pallini colorati nella stessa diagonale).
Tratti in diagonale che vanno nella direzione opposta indicano delle inversioni, inoltre tratti paralleli alla diagonale principale indicano delle regioni duplicate.
Se non si definiscono i giusti criteri è impossibile valutare la bontà di un allineamento. Ad esempio le visualizzazioni viste non tengono conto dei gap. Man mano che vengono inseriti dei gap la visualizzazione a livello dei dot matrix cambia. Per stabilire il corretto allineamento va assegnato un punteggio alle diverse caselle in modo da poter confrontare percorsi (e allineamenti) diversi.
Per definizione un programma andrebbe ad inserire un numero molto elevato di gap per ottenere l’allineamento migliore, per questo motivo l’inserimento del gap viene controllato assegnando dei punteggi di penalità.
similarità
inversione
duplicazione
BIOINFORMATICA, Lezione 3
ALGORITMI DI PROGRAMMAZIONE DINAMICA
La programmazione dinamica è una metodica computazionale usata per allineare due sequenze; si basa sul ricombinare gli appaiamenti (matches), i non appaiamenti (mismatches) e i gaps in modo da trovare il massimo numero possibile degli appaiamenti dei residui tra loro correlati.
N.B. Gli allineamenti ottenuti dipendono dalla scelta del sistema di punteggio per i matches e le penalità per le inserzioni.
MISURE DI IDENTITA’ E DI SIMILARITA’
Il modo più semplice per definire relazioni di similarità tra nucleotidi è basato su identità e diversità : la più semplice matrice di similarità (unitary scoring matrix) assegna punteggio 1 ai match e 0 ai mismatches. Per questo motivo viene definita MATRICE DI IDENTITÀ.
In generale quando c’è corrispondenza viene attribuito un punteggio e quando non c’è ne viene attribuito un altro. Qui per convenzione i punteggi sono 0 e 1 ma in realtà si può attribuire qualsiasi altro valore. Si possono poi utilizzare anche dei criteri differenti e ad esempio si potrebbero dare dei punteggi di sostituzione tra purine e pirimidine considerando anche transizioni e trasversione. Utilizzare dei criteri differenti (es. raggruppamenti di purine e pirimidine ecc.) non cambia la natura della matrice.
Per gli amminoacidi la situazione è un po’ differente: quello di cui dobbiamo tenere conto è il discorso della similarità perché non possiamo basarci solo sull’identità assoluta ma dobbiamo tenere conto anche di quelle che sono le caratteristiche chimico fisiche degli amminoacidi.
Quando un amminoacido cambia in un altro che ha le stesse caratteristiche la proteina non ne risente molto a livello di funzionalità e a livello evolutivo questi cambiamenti sono i più frequenti. Inoltre ci sono amminoacidi più conservati di altri quindi il loro allineamento dovrebbe avere uno score più elevato (es. allineamento C/C dovrebbe essere più premiante rispetto ad un A/A, essendo l’alanina più rara).
In alcuni allineamenti è facile vedere dove è avvenuto il cambiamento mentre in altri casi ci sono allineamenti più complessi con un maggior numero di gap. In questo caso è importante determinare un sistema di punteggio per valutare la qualità dell’allineamento.
Qui vengono riportate due sequenze allineate dove sono sottolineati i residui per cui abbiamo una corrispondenza e marcati in neretto quelli con le stesse proprietà chimico fisiche. La lunghezza dell’allineamento è di 35.
Identità di sequenza (numero di residui identici appaiati): 21/35 = 60% Similarità di sequenza (numero di residui con stesse caratteristiche): 4/35 = 11.5%
Ovviamente i criteri per la similarità tra residui vanno attentamente valutati.
Allineare le proteine significa trovare il modo di convertire le sequenze inserendo il minor numero possibile di cambiamenti. Si assegnano dei criteri per valutare l’importanza di match (similarità positiva), mismatch (similarità negativa) e gap (similarità negativa che permette di migliorare l’allineamento globale).
Questa è una matrice di identità con un punteggio pari a 10 per una corrispondenza, non attribuisce dei punteggi ai cambiamenti.
Quello che dobbiamo fare è sostituire gli 0 andando ad attribuire dei punteggi ai cambiamenti, otteniamo una matrice di sostituzione 20x20 mentre quella per i nucleotidi era 4x4.
Un meccanismo di punteggi che voglia tenere in considerazione solo le identità potrà utilizzare una matrice con valori alti nella diagonale e 0 nelle altre posizioni (come quella in figura).
SIMILARITA’
Per determinare il grado di similarità tra sequenze amminoacidiche possono essere utilizzati 4 approcci differenti:
Sono delle matrici 20x20 che attribuiscono ad ogni coppia amminoacidica un valore che indichi il loro grado di similarità. Andremo quindi a dare un valore a tutti quegli 0 presenti nella matrice vista prima, questi valori sono stati ottenuti allineando molte coppie di proteine simili.
Viene calcolata per ogni coppia di amminoacidi i e j la frequenza con cui si trovano in posizioni corrispondenti negli allineamenti (fij) anche la frequenza con cui gli amminoacidi appaiano nelle sequenze (fi e fj). Il rapporto tra queste frequenze ( fij/fixfj ) è una misura di quanto spesso questi amminoacidi appaiono in posizioni corrispondenti rispetto ad un allineamento casuale.
Se io trovo nell’allineamento insieme tante volte degli amminoacidi che in realtà sono rari quegli amminoacidi hanno un significato maggiore rispetto al trovare insieme molte volte degli amminoacidi che sono molto frequenti.
MATRICI BLOSUM (blocks amino acid substitution matrices)
Vengono determinate sulla base di sostituzioni amminoacidiche osservate in circa 2000 blocchi conservati di sequenze estratti da una banca date di 500 famiglie di proteine. Quello che viene effettivamente considerato sono gli scambi amminoacidici effettivi visualizzati in ciascuna colonna dell’allineamento.
Questa è la formula:
B(a,b) = probabilità ricavata dall’osservazione dei vari BLOCKS
C(a,b) = probabilità di appaiamento casuale, cioè considerando la frequenza media di ogni amminoacido come evento indipendente
K = 3/log 2 o 2/log 2
Quello da ricordare è che le matrici BLOSUM si basano sull’osservazione delle differenze che intercorrono tra le sequenze allineate
Qui abbiamo la solita matrice ma non si verifica mai che certe mutazioni abbiano un punteggio più alto di alcune conservazioni
Matrice BLOSUM 62 indica che le matrici sono state costruite confrontando sequenze avente il 62% di identità. Possono esserci anche varianti di matrici (sia PAM che BLOSUM) con all’interno numeri tutti positivi.
Quindi mentre le PAM fanno derivare le distanze evolutive dall’assunzione che le mutazioni siano successive, indipendenti e che quindi si possano sommare, le BLOSUM non fanno assunzioni ma si basano sull’osservazione dell’allineamento.
Un indice PAM crescente indica score più distanti tra loro mentre uno BLOSUM crescente indica proteine più simili tra loro, esprimendo il valore minimo di conservazione del BLOCK.
Le PAM tendono a premiare sostituzioni derivanti da mutazioni di singola basa più che motivi strutturali, come fanno le BLOSUM.
Quale matrice scegliere?
Il confronto tra le due matrici non porta a risultati uguali ma molto simili tra loro. È stato ad esempio notato che le PAM hanno una leggera tendenza a premiare sostituzioni amminoacidiche che derivano da una mutazione a singola base penalizzando invece sostituzioni più complesse. Quindi le matrici BLOSUM sono
più adatte per ricerche di similarità di sequenza, mentre le PAM per studi di filogenesi perché considerano il numero di passi evolutivi. Tuttavia sono simili e portano spesso agli stessi risultati. Ovviamente una PAM sarà corrispondente a una BLOSUM80 (e le BLOSUM non possono andare oltre la BLOSUM100 perché questa corrisponde alla matrice di identità).
L’utilizzo della matrice appropriata è fondamentale per avere buoni risultati, infatti relazioni importanti da un punto di vista biologico possono essere indicate da una significatività statistica anche molto debole.
Nell’allineamento di proteine o acidi nucleici bisogna tener conto che l’allineamento migliore può essere ottenuto con l’inserzione di uno o più gap che corrispondano a fenomeni di inserzioni o delezioni. Per i gap devono essere presi in considerazione due valori di penalizzazione per limitare la tendenza del programma ad aggiungere gap:
Nel momento in cui viene aggiunto un gap sorge anche il problema dell’estensione, fra i due valori quello che ha più significato è l’apertura del gap: questo significa decidere che quella parte della sequenza non è significativa e quindi la penalizzazione deve essere maggiore. Dato che una zona poco conservata può variare molto in estensione la penalizzazione per l’estensione darà minore.
Qui abbiamo due tipologie di allineamenti: uno locale e uno globale. Quello globale ha un punteggio più elevato. Il computer direbbe che questo è il migliore ma biologicamente non è detto perché è possibile che in allineamenti globali non vengano messi in evidenza dei domini strutturali che si vedono nell’allineamento locale (come in questo caso). Le banche dati sono accumunate da un numero finito di domini strutturali per cui in una banca dati (es. blast) ha più senso cercare similarità locali e non globali. Nonostante lo score più baso questi allineamenti possono evidenziare dei domini proteici. Invece proteine molto simili saranno accomunate da regioni locali così estese che l’allineamento globale darà risultati migliori, minimizzando i gaps e rendendo le similarità più leggibili.
Sequenze poco divergenti Sequenze molto divergenti
BLOSUM80, PAM1 BLOSUM62, PAM120 BLOSUM45, PAM
Se il percorso procede in verticale o in orizzontale solo una casella deve essere conteggiata perché un amminoacido non può appaiarsi due volte e ogni casella ha uno score che dipende dal percorso a monte ed è indipendente dal percorso a valle. Quindi il miglior percorso a monte di un residuo è sempre determinabile.
Fase 3. Si trova il valore più alto e si procede a ritroso lungo la diagonale cercando lo score maggiore: quello che viene effettuato è l’allineamento vero e proprio (globale in questo caso). Si parte da in basso a destra procedendo a ritroso. In questo esempio la Q viene riportata come fuori dall’allineamento, si va poi indietro ricostruendo l’allineamento prendendo ogni volta il valore più alto. Ovviamente in questo caso non ci sono gap.
Allineamento risultante:
Alla base degli algoritmi dinamici ci sono quindi tre fasi:
Date 2 proteine di lunghezza n e m, una matrice di sostituzione e una penalità dei gap
1- Produciamo una matrice n x m con tutti i residui delle proteine. In ogni casella si posiziona il punteggio ottenuto da una matrice di sostituzione per la coppia di residui corrispondente 2- Per ogni casella si trova il massimo punteggio ottenuto dai percorsi (diagonale, orizzontale, verticale) 3- Cercare lo score più alto di tutti tra tutte le caselle e procedere verso gli score più alti ma andando a ritroso.
contrariamente al globale questo può avere dei punteggi massimi “locali” anche all’interno della matrice. Quindi non ne cercherà solamente uno ma andrà alla ricerca di tutti gli allineamenti sopra una determinata soglia che viene prefissata.
Allineamento ricostruito che presenta un gap: in corrispondenza della C allineata con la C vediamo un gap. Il punteggio 0 (in verde) viene attribuito quando tutti i percorsi danno punteggi molto negativi.
Le differenze dell’allineamento locale rispetto al globale sono che in primo luogo bisogna considerare un valore soglia al di sotto del quale l’appaiamento di due amminoacidi viene considerato negativo. Inoltre una volta definito il punto di inizio e di fine di un allineamento, il punteggio non deve essere influenzato dalle regioni esterne. Non importa quanto estese o negative siano le regioni fuori dall’appaiamento perché l’allineamento locale resta comunque quello che è. In termini tecnici al momento di considerare i tre possibili percorsi di origine sarà considerata sempre anche una quarta opzione: il punteggio zero. Ogni volta che i tre percorsi saranno tutti negativi lo zero diventerà la scelta più vantaggiosa e determinerà l’inizio di un nuovo possibile allineamento locale. Inoltre, per recuperare il massimo punteggio l’algoritmo non limiterà la ricerca all’ultima riga o colonna ma lo cercherà in tutte le righe e colonne, andando a trovare dei massimi “locali”.
Generalmente non ci si limita a cercare un unico allineamento (come per il globale) ma tutti gli allineamenti che ottengono un punteggio sopra una determinata soglia.
I programmi che utilizzano algoritmi dinamici di allineamento come abbiamo visto finora sono ideali per allineare due sequenze in modo esatto ma sono troppo lenti per effettuare ricerche di similarità in banche dati.
FASTA e BLAST sono in grado di effettuare velocemente ricerche in banche dati perché utilizzano soluzioni euristiche. Ovvero non considerano tutte le soluzioni ma solamente quelle più probabili: questo permette di velocizzare le ricerche a discapito dell’accuratezza.
FASTA
È stato il primo programma in grado di ricercare velocemente similarità in banche dati, sviluppato da Lipman & Person nel 1985. Entrambi (anche il BLAST) usano il sistema delle parole: viene preso in considerazione un certo numero di residui e l’algoritmo è basato su una strategia di indicizzazione delle parole. Il parametro che si riferisce all’indicizzazione delle parole viene definito come ktup (valore esponenziale). Normalmente vengono attributi valori di 2 per gli amminoacidi e di 6 per gli acidi nucleici. Questo significa che avremo 20^2 = 400 parole diverse di 2 amminoacidi per le proteine e 4^6 =4096 parole di 6 nucleotidi per gli acidi nucleici. Quindi l’indicizzazione consiste nel creare un elenco delle posizioni di tutte le parole trovate all’interno della sequenza Query (la sequenza che noi stiamo analizzando).
Quando noi diamo la nostra sequenza al programma questo va a scomporla in tante parole. La sequenza che diamo in input viene definita query mentre le diverse sequenze più simili che ci vengono restituite sono chiamate Subject. Una volta che il programma ha l’elenco delle parole le va a cercare nelle subject (i tratti neri presenti nell’immagine sono delle porzioni di somiglianza fra le due sequenze che il programma sta analizzando, parole singole o consecutive).
PASSAGGIO 1: il programma consulta l’indice per verificare se e dove ogni parola della query è stata trovata nella sequenza subject e ogni volta che viene trovata su entrambe le sequenze questo memorizza la corrispondente diagonale. Alla fine unisce eventuali parole contigue per formare segmenti di identità più consistenti.
PASSAGGIO 2: i punteggi delle regioni corrispondenti ai segmenti più lunghi sono ricalcolati utilizzando una matrice di sostituzione (es. PAM240). Quindi prenderà sopra i risultati al di sopra di un certo valore. Per sapere il punteggio dei trattini vengono applicate le matrici, il programma troverà tutti i tratti con punteggio più elevato e tiene solo quelli scartando tutti gli altri. Si ottengono
Variare questi parametri è comunque complesso, noi possiamo agire variando le dimensioni della parola, quindi il numero di residui contigui che il programma utilizza per l’indicizzazione.
Affrontiamo a questo punto il discorso dei software che si utilizzano per fare allineamenti multipli di sequenze. Abbiamo visto finora algoritmi di programmazione dinamica in cui abbiamo trattato la nostra analisi utilizzando una matrice con una sequenza posta sull’asse x e l’altra sull’asse y. Ma se voglio allineare più di due sequenze posso immaginare di porre la mia sequenza su un ulteriore asse ma da un punto di vista matematico quando vado ad aggiungere ulteriori assi aumenta a dismisura il tempo di analisi, questo è il principale problema dell’estensione della programmazione dinamica da 2 sequenze a n sequenze.
Con k sequenze di lunghezza N il tempo di analisi è di Nk^ (quello che incide molto non è tanto la lunghezza quanto il numero di sequenze considerate). Da un punto di vista teorico quindi si possono utilizzare degli algoritmi di programmazione dinamica per i multiallineamenti ma lo si potrebbe fare solo per un numero molto piccolo di sequenze. Si è dovuto bypassare questo ostacolo delle tempistiche delle analisi.
Dato l’enorme potenziale di informazione che un allineamento multiplo può dare, gli studi computazionali hanno ricevuto un alto grado di attenzione. Problema principale degli allineamenti multipli di sequenza è che bisogna tenere conto di match, mismatch e gap per un numero elevato di sequenze, impossibile per un metodo di allineamento esatto come gli algoritmi dinamici di appaiamento.
Per risolvere questo problema sono stati sviluppati dei metodi “approssimati”:
Gli allineamenti multipli di sequenza sono importanti perché possono rivelare se esiste o no una relazione evolutiva tra tre o più sequenze e ci possono dare un’idea di quali regioni mostrano una più elevata similarità, e che sono quindi strutturalmente conservate. Se ad esempio voglio studiare una data proteina, la sua sequenza può essere confrontata con quelle di altri organismi analizzando quelli che sono i tratti variabili e altri tratti più conservati che potrebbero corrispondere ai domini conservati: posso fare così una
predizione di struttura. Sono importanti anche per fare una previsione dei siti di regolazione del DNA e quindi anche per la costruzione di sonde specifiche: una volta che un pattern consenso (presente in tutte le sequenze) è stato individuato può essere usato per cercare sequenze simili in un database. Se si studiano organismi non modello non si hanno mai sequenze di riferimento su cui progettare primer ecc. Se occorre progettarli si fanno allineamenti multipli di sequenza considerando organismi vicini e evidenziando tratti più conservati per progettare dei primer, eventualmente inserendo delle degenerazioni.
Gli msa hanno un ruolo centrale in biologia e medicina: possono servire per studi filogenetici, predizione di struttura e identificazione di domini strutturali e interazioni, genomica comparativa, identificazione di SNPs e quindi anche design e sviluppo di farmaci in ambito terapeutico
Ideato da Higgins e Sharp nel 1988, è uno dei programmi più usati per effettuare msa e fa parte della famiglia dei programmi ad allineamento globale progressivo. Prima vengono ottenuti tutti gli allineamenti di coppia e si registra il punteggio per ciascuno di questi, con questi punteggi si va a costruire un albero filogenetico in modo da visualizzare le relazioni evolutive (neighbor joining). Ad ogni passo si allineerà la coppia con distanza minima.
Prima vengono allineate le sequenze 2 e 3, poi 4 e 5, poi si allineerà la 1 con le 2-3 ed infine 1-2-3 saranno allineate con 4-5. Questa è una semplificazione di quello che è il metodo usato da ClustalW.
Ma come si può allineare una sequenza ad un allineamento già esistente?
Qui abbiamo come esempio la sequenza AGRSGS (asse y della tabella) che deve essere allineata all’allineamento appena fatto, presente sull’asse x. Viene prima costruita una matrice di questo tipo:
In questo caso ad esempio viene applicata una matrice di tipo PAM, quindi prendo il punteggio della matrice dell’adenina (A) che si conserva con A e lo sommo al punteggio di A che cambia con la valina (V) e lo vado a dividere per due. Quindi considera tutte e due le possibilità (una A appaiata con una A o una A appaiata con una V), questo ci permette di ottenere l’allineamento di una sequenza con un allineamento già esistente sommando i punteggi per tutte le combinazioni possibili di quell’allineamento.
I metodi di allineamento progressivo non sono utilizzabili e adatti alla comparazione di sequenze di lunghezza diversa, l’inserzione di lunghi gap solitamente non è tollerata e questo spesso limita l’accuratezza del metodo. Inoltre l’allineamento finale è influenzato dall’ordine in cui vengono inserite le sequenze nella creazione dell’albero filogenetico: man mano che le sequenze vengono inserite queste non vanno a modificare l’allineamento delle prime che è già stato fatto (la limitazione principale del metodo è proprio questa). Altra grossa limitazione è data dalla natura “greedy”, nel senso che esso dipende essenzialmente dall’allineamento iniziale della prima coppia di sequenze. Una volta che i gap vengono inseriti nelle primissime fasi dell’allineamento questi vengono fissati e quindi eventuali errori non potranno essere successivamente corretti. Questo ovviamente determina la possibilità di propagare gli errori all’interno