



DIPARTIMENTO DI SCIENZE DELLA VITA E DELL’AMBIENTE
Corso di Laurea Magistrale in Biologia
Molecolare ed Applicata
Relazione di Bioinformatica
Tipologia C
Codice: 2GU2
Studentessa: IAMANDI Georgiana Emilia
Matricola: S1118386


















Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
Relazione di Bioinformatica, traccia 3 codice 2GU2. Essenziale per l'esame.
Tipologia: Appunti
1 / 29

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
1. Riportare il nome della proteina e una breve descrizione della funzione. Il mio codice 2GU2 fa riferimento ad un’ aspartoacilasi del Rattus norvegicus (ratto grigio). Questa proteina catalizza la deacetilazione dell'acido N-acetilaspartico (NAA) per produrre acetato e L- aspartato. L'NAA è presente in alte concentrazioni nel cervello e la sua idrolisi svolge un ruolo significativo nel mantenimento della materia bianca intatta. In altri tessuti agisce come uno scavenger dell'NAA dai fluidi corporei. 2. Recuperare le sequenze amminoacidica e nucleotidica corrispondenti. L’aspartoacilasi presenta due catene, A e B, formate da un totale di 312 amminoacidi (aa). Di seguito verranno riportate le due sequenze: Sequenza amminoacidica
sp|Q9R1T5|ACY2_RAT Aspartoacylase OS=Rattus norvegicus OX=10116 GN=Aspa MTSCVAEEPIKKIAIFGGTHGNELTGVFLVTHWLKNGAEVHRAGLEVKPFITNPRAVEKCTRYIDCDLNRVFDLEN LSKEMSEDLPYEVRRAQEINHLFGPKNSDDAYDVVFDLHNTTSNMGCTLILEDSRNDFLIQMFHYIKTCMAPLP CSVYLIEHPSLKYATTRSIAKYPVGIEVGPQPHGVLRADILDQMRRMLKHALDFIQRFNEGKEFPPCAIDVYKIME KVDYPRNESGDVAAVIHPNLQDQDWKPLHPGDPVFVSLDGKVIPLGGDCTVYPVFVNEAAYYEKKEAFAKTTKL TLNAKSIRSTLH
Sequenza nucleotidica
NM_024399.2 Rattus norvegicus aspartoacylase (Aspa), mRNA TGGACATTGTGACAGAAACAGTTGTGAAGTCAGTTCCCAAGAGAGCTCTGTATTTTTCACTTCTCACTTAGATCT AAACTTGGAAACTTTTCTCAGAAGTTAAGTGTCCTTTGACCTCCTCTCTTCTGAATTGCAGAAACCAGACCAGA TTTTGGTATTTGGTAAAATGACTTCTTGTGTTGCTGAAGAACCTATTAAAAAGATTGCCATCTTCGGAGGGACTCA TGGAAATGAACTGACTGGAGTGTTTCTAGTTACTCACTGGCTAAAGAATGGCGCTGAAGTTCACAGAGCAGGG CTGGAAGTGAAGCCATTCATTACCAACCCAAGAGCGGTGGAGAAGTGCACCAGATACATTGACTGTGACCTG AACCGTGTTTTTGACCTTGAAAATCTTAGCAAAGAGATGTCTGAAGATTTGCCGTATGAAGTGAGAAGGGCTCA AGAAATAAATCACTTATTTGGTCCAAAAAATAGTGATGATGCCTACGATGTCGTTTTTGACCTTCATAACACTACT TCTAACATGGGTTGCACTCTTATTCTTGAGGATTCCAGGAATGACTTTTTAATCCAGATGTTTCACTATATTAAGAC CTGCATGGCTCCATTACCCTGCTCTGTTTACCTCATCGAGCATCCTTCCCTCAAATATGCAACCACTCGTTCC ATTGCCAAGTATCCTGTTGGTATAGAAGTTGGTCCTCAGCCTCACGGTGTTCTGAGAGCTGATATTTTAGACCA AATGAGAAGAATGCTCAAGCACGCTCTTGATTTTATACAGCGTTTCAATGAAGGTAAAGAATTTCCCCCCTGTG CTATTGATGTCTATAAAATAATGGAGAAAGTTGATTATCCAAGGAACGAAAGTGGAGACGTGGCTGCTGTTATCC ATCCTAATCTGCAGGATCAAGACTGGAAACCATTGCACCCTGGAGATCCTGTGTTTGTGTCTCTTGATGGAAAA GTTATTCCACTGGGTGGAGACTGTACCGTGTACCCAGTGTTTGTGAATGAAGCTGCATATTATGAAAAAAAAGA AGCATTTGCAAAGACAACAAAACTAACACTCAACGCAAAAAGCATCCGCTCCACTTTGCACTAAACATCTCTG CAAGCTCACAGTTATGGGATCTTACAGACCTCTAGAAGTCTGTAAACGCTCCAAGACCAGAGTGCCTCATTCT AGTTCTTTTCCTCAGCACCTGGCCCCATGCCTCAAGCAGTAAGCATCCAGGCCAGGTTCTGAAAGGAAAGA ATAAATTCATGAATGTCTTTCATATATGTTTGGATGAGCTATGTACAGTAGACAGGCAAGTGTGCTTCTGGTTTCTG TATTATTCTTTATACATTACATTCTGGTAGTTTAACATTGTTAACTTTCACATTTAGAACATAACATTGAAATACATGC TACATGCAATTTAGCATACAGTGAGACAGACTGAATATGTGTTTTCAAGGAATGCATAAGTACTATTCAAAACTAA TAGTACAGACTTGCTGTTTTTAAGTGCTGATATGTGAGTTAATAACAGTGTATTATTAAATGTCCATTCCTTAAA
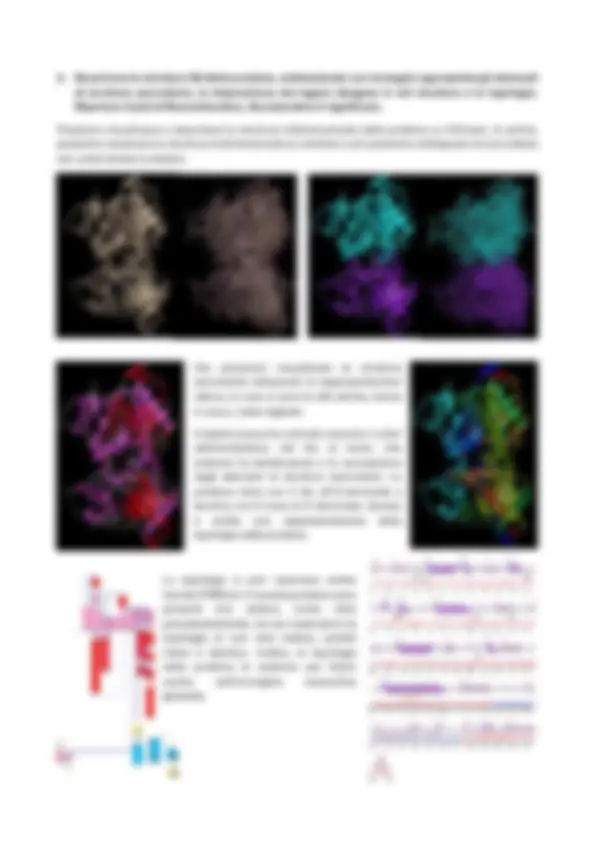
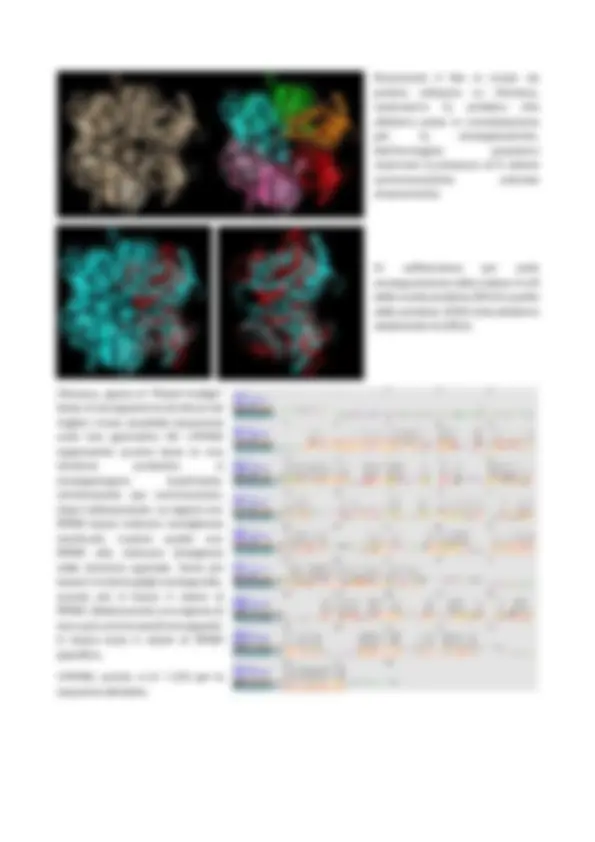
4. Descrivere la struttura 3D della proteina, evidenziando con immagini appropriate gli elementi di struttura secondaria, la disposizione dei legami idrogeno in tali strutture e la topologia. Riportare il plot di Ramachandran, discutendone il significato. Possiamo visualizzare e descrivere la struttura tridimensionale della proteina su Chimera. In primis, possiamo osservare la struttura tridimensionale (a sinistra) e poi possiamo distinguere le due catene con colori diversi (a destra). Ora possiamo visualizzare le strutture secondarie utilizzando la rappresentazione ribbon, in rosa ci sono le alfa-eliche, mente in rosso, i beta-foglietti. A destra invece ho colorato secondo i colori dell’arcobaleno, dal blu al rosso, che indicano la distribuzione e la successione degli elementi di struttura secondaria. La proteina inizia con il blu all’N-terminale e termina con il rosso al C-terminale. Questa è anche una rappresentazione della topologia della proteina. La topologia si può osservare anche tramite PDBSum: in questa proteina sono presenti due catene, come visto precedentemente, ma qui osserviamo la topologia di una sola catena, poiché l’altra è identica. Inoltre, la topologia della proteina la vediamo per intero anche nell’immagine riassuntiva generale.
Ritornando alla rappresentazione su Chimera, possiamo visualizzare i legami ad idrogeno, colorati di giallo: Inoltre, sempre da questa schermata, possiamo visualizzare il Plot di Ramachandran, che ci permette di valutare le conformazioni più stabili assunte dai vari amminoacidi all’interno della molecola in relazione agli angoli φ e ψ. Passando con il mouse su ogni puntino escono le coordinate psi e phi, angoli di rotazione, dell’amminoacido di interesse. Possiamo notare come la maggior parte degli amminoacidi della mia proteina sono localizzati all’interno delle regioni verdi che rappresentano le conformazioni maggiormente favorite, anche dal punto di vista energetico, mentre sono pochi quelli nelle linee celesti. Gli amminoacidi localizzati fuori dalla linea celeste si trovano in regioni che hanno un contenuto energetico ancora più alto quindi meno stabili. La regione in alto a sinistra corrisponde di solito alle alfa- eliche, mentre quella in basso a sinistra corrisponde ai foglietti beta. Lo stesso grafico si può osservare anche tramite PDBSum, i colori sono diversi ma il significato è lo stesso.
Al di sotto di questa rappresentazione abbiamo la porzione “RNA seq exon coverage”, dove è presente una rappresentazione grafica riguardo l’abbondanza di trascritti per quelle regioni esoniche, quindi la copertura dei tratti esonici in termini di abbondanza di trascritti. Al di sotto, in “RNA-seq intron spanning read” è presente un grafico che indica quanto sono rappresentate le porzioni introniche in termini di abbondanza di trascritti.
6. effettuare ricerca di similarità in banca dati primaria (GenBank) utilizzando il programma BLAST sia per la sequenza nucleotidica sia per quella amminoacidica; per quest’ultima provare anche a cambiare i parametri di BLAST relativi alla matrice ed evidenziare e commentare eventuali differenze nei risultati; Effettuando una ricerca di similarità utilizzando il programma BLAST nucleotidico, quindi per la sequenza nucleotidica, otteniamo questo risultato:
Tutte le sequenze fanno riferimento al gene Aspartoacilasi (Aspa), gene responsabile della codifica dell'enzima aspartoacilasi. Le specie menzionate includono roditori come Rattus norvegicus (ratto), Mus musculus (topo) e altre specie simili. Ogni voce descrive una sequenza genetica associata al gene Aspa. Alcune sequenze sono specificate come "completa cds" (coding sequence), altre come varianti trascrizionali. Il punteggio massimo (Max Score) e il punteggio totale (Total Score) indicano la qualità dell'allineamento tra la sequenza di input e le sequenze del database. Un punteggio più alto suggerisce una maggiore somiglianza. La Query Cover è del 100% nel primo risultato, quello riferito alla sequenza che stiamo analizzando. Ora, andando ad effettuare una ricerca BLAST per la sequenza amminoacidica otteniamo: Dal risultato ottenuto, osserviamo che il primo corrisponde alla nostra proteina, l’aspartoacilasi del Rattus norvegicus, già il secondo risultato corrisponde ad un organismo diverso, il Rattus rattus, ed è un’isoforma. Tutti i risultati mostrano una query cover del 100%, il che significa che l'intera sequenza della query è stata allineata ai risultati. La percentuale di identità indica il grado di corrispondenza tra le sequenze e quella della query: il più alto, al 100%, è il risultato con Rattus norvegicus, mentre gli altri risultati hanno valori molto alti, vicini al 99-97%, in quanto si trova similarità in diversi tipi di topo. L’E- value è 0 per tutti i risultati, indicando che le corrispondenze non sono dovute al caso e sono significative dal punto di vista biologico. La lunghezza dell'allineamento (Acc. Len) è di circa 312 per la maggior parte delle sequenze, tranne alcune varianti leggermente più lunghe. Questo è ciò che viene rappresentato nel Graphic Summary. Tutti gli allineamenti sembrano coprire quasi interamente la query, segno che i diversi risultati sono sequenze molto simili alla query e si allineano per una grande porzione della sua lunghezza. Poiché ogni riga rappresenta un risultato visto nella Description, si può dedurre che la query si allinea bene con molte sequenze soggetto nel database, suggerendo che la sequenza query è conservata in molte specie o ha sequenze simili in vari geni.
allineamenti altamente conservati le differenze tra le due matrici diventano meno significative, portando a punteggi finali molto simili. Matrice BLOSUM 80 : BLOSUM80 è progettata per sequenze strettamente correlate. È stata costruita usando sequenze con almeno l'80% di identità, il che significa che assegna punteggi più alti alle corrispondenze esatte e penalizza maggiormente le sostituzioni non comuni. BLOSUM80 troverà allineamenti molto accurati, privilegiando corrispondenze di amminoacidi altamente conservati. Anche in questo caso i risultati sono pressoché uguali. Le sequenze allineate sono molto simili e la maggior parte dei punteggi deriva dalle identità perfette, che sono trattate in modo simile da tutte le matrici. Le differenze amminoacidiche tra le sequenze sono poche o riguardano aminoacidi tollerati in modo simile dalle diverse matrici. Inoltre, l'impatto delle penalizzazioni per le mutazioni è ridotto perché le sequenze hanno poche differenze, e quindi anche una matrice più stringente come BLOSUM80 non penalizza significativamente più di BLOSUM62 o BLOSUM45. Matrice PAM250 : La matrice PAM250 è progettata per sequenze evolutivamente molto distanti e permette una grande tolleranza alle mutazioni, consentendo l'allineamento di sequenze più diversificate. L’indice ci spiega che la matrice è stata costruita ipotizzando 250 sostituzioni ogni 100 amminoacidi, corrispondenti a 25 0 passi evolutivi. In questo caso, i Max Score e Total Score risultano essere inferiori rispetto a quelli ottenuti con le matrici BLOSUM. Non premia abbastanza le corrispondenze esatte nelle sequenze molto simili. Inoltre, penalizza meno le mutazioni, il che significa che non distingue abbastanza tra allineamenti fortemente conservati e allineamenti moderatamente conservati quando le sequenze sono simili. Le matrici BLOSUM, al contrario, sono più adatte a sequenze simili e quindi premiano fortemente le corrispondenze e penalizzano le mutazioni, portando a punteggi più alti rispetto alla PAM250.
7. selezionare tra le sequenze nucleotidiche ottenute, oltre a quella di partenza, almeno 6 sequenze appartenenti ad organismi diversi (possibilmente con la query cover più alta possibile e con identità compresa tra il 90% e il 50%); Oltre alla sequenza di partenza, ho selezionato altre 7 sequenze nucleotidiche riferite sempre all’Aspartoacilasi, però di diversi organismi: - Rattus norvegicus - Phodopus roborovskii - Microtus ochrogaster - Chionomys nivalis - Nannospalax galili - Jaculus jaculus - Marmota monax - Phoca vitulina Inoltre, ho scaricato le sequenze FASTA allineate, in quanto alcune sono molto più lunghe di altre. >Rattus_norvegicus TGGACATTGTGACAGAAACAGTTGTGAAGTCAGTTCCCAAGAGAGCTCTGTATTTTTCACTTCTCACTTAGATCTA AACTTGGAAACTTTTCTCAGAAGTTAAGTGTCCTTTGACCTCCTCTCTTCTGAATTGCAGAAACCAGACCAGATTT TGGTATTTGGTAAAATGACTTCTTGTGTTGCTGAAGAACCTATTAAAAAGATTGCCATCTTCGGAGGGACTCATGG AAATGAACTGACTGGAGTGTTTCTAGTTACTCACTGGCTAAAGAATGGCGCTGAAGTTCACAGAGCAGGGCTGGAA GTGAAGCCATTCATTACCAACCCAAGAGCGGTGGAGAAGTGCACCAGATACATTGACTGTGACCTGAACCGTGTTT TTGACCTTGAAAATCTTAGCAAAGAGATGTCTGAAGATTTGCCGTATGAAGTGAGAAGGGCTCAAGAAATAAATCA CTTATTTGGTCCAAAAAATAGTGATGATGCCTACGATGTCGTTTTTGACCTTCATAACACTACTTCTAACATGGGT TGCACTCTTATTCTTGAGGATTCCAGGAATGACTTTTTAATCCAGATGTTTCACTATATTAAGACCTGCATGGCTC CATTACCCTGCTCTGTTTACCTCATCGAGCATCCTTCCCTCAAATATGCAACCACTCGTTCCATTGCCAAGTATCC TGTTGGTATAGAAGTTGGTCCTCAGCCTCACGGTGTTCTGAGAGCTGATATTTTAGACCAAATGAGAAGAATGCTC AAGCACGCTCTTGATTTTATACAGCGTTTCAATGAAGGTAAAGAATTTCCCCCCTGTGCTATTGATGTCTATAAAA TAATGGAGAAAGTTGATTATCCAAGGAACGAAAGTGGAGACGTGGCTGCTGTTATCCATCCTAATCTGCAGGATCA AGACTGGAAACCATTGCACCCTGGAGATCCTGTGTTTGTGTCTCTTGATGGAAAAGTTATTCCACTGGGTGGAGAC TGTACCGTGTACCCAGTGTTTGTGAATGAAGCTGCATATTATGAAAAAAAAGAAGCATTTGCAAAGACAACAAAAC TAACACTCAACGCAAAAAGCATCCGCTCCACTTTGCACTAAACATCTCTGCAAGCTCACAGTTATGGGATCTTACA GACCTCTAGAAGTCTGTAAACGCTCCAAGACCAGAGTGCCTCATTCTAGTTCTTTTCCTCAGCACCTGGCCCCATG
>Nannospalax_galili TCTTACTTAGACTTAAATTTCTAAACTTTTCTTGGGAGTTAACCTCTGTTTGACCTCTATTCTGAACTGCAGAAAT CAGACAAACCTACTTGGTAAAATGGCCTCATGTTGGGTTGCTGAAGAACCTATAAAAAAGATTGCTATCTTTGGAG GAACTCACGGCAATGAACTGACAGGAGTGTTTCTAGTCAAGCACTGGCTAAGGAATGGCGCTGAAATTCAGAGAAC AGGTCTGGAAGTGAAACCATTTATTACCAACCCAAGAGCAGTGGAAAAATGTACCAGATACATTGACTGTGACCTA AATCGTGTTTTCAACCTTGAAAATCTTAGCAAAGAGATATCAGATGATTTGCCATATGAAGTGAGAAGGGCTCAAG AAATAAACCATTTGTTTGGTCCAAAAAATAGTGAAGATTCCTATGATATAATTTTTGACCTTCACAACACTACTTC TAACATGGGTTGCACTCTTATTCTTGAAGATTCCAAGAATGATTTTTTAATTCAGATGTTCCATTATATTAAGACT TCTTTGGCTCCATTACCCTGCTTTGTTTATCTTATTGAGCATCCTTCCCTCAAATATGCAACTACTCGCTCCATCG CCAAGTATCCTGTTGGTATAGAAGTTGGTCCTCAGCCCCAAGGTGTTCTGAGAGCTGATATTTTGTACCAAATGAG AAAAATGATTAAACATGCTCTTGATTTTATACAGCACTTCAATGAAGGAAAAGAATTTCCTCCCTGTGCTATTGAA GTCTATAAAACAATGGAGAAAGTTGATTATCCGAGGAATGAAAGTGGAGAAATTGCTGCTGTCATCCATCCTAATC TACAGGATCAAGACTGGAAACCACTGTACCCTGGAGATCCTGCATTTGTATCCCTTGATGGAATGATTATTCCACT AGGAGGAGACTGTACTGTATACCCCGTGTTTGTGAATGAGGCTGCATATTATGAAAAGAAAGAAGCATTTGCGAAG ACAACCAAACTAACACTCAATGCAAAAAGCATCGCACTACTTTCCAATAGAAATTAATGCTAGCTCAGTGTGACCT GGGAATTCCTCAGGAGCAGGGTTGTACCTTATTCTAGTTCTCCACAGCACCTGGCCCCATGCCTCATACATTAGGC ATCCAGACCAGTTTCTGGGAGGAAAGAATAAATTAATGAATGTCTTCCACATATATCATAGTTTATATATGTAGCT TACTCAAGCTAGTGTGTTTCTGATTTCTGTATAGCTCTTTATACAGTATACTTTGATAGTTTAACATTGTTAATAA ACAACCTTCACATTCAGAACATAAAATTAAGATGCATACTATATTCAAAGTTGTCAGCCTAACATACAATGAAACT GAATAAAATGTATGTTTTCAAGTAATATATAAGCGCTACTAGAAACTAACAGTGTAGACTTGATATTTTTCAGT >Jaculus_jaculus CTTTTCTTAGGAAAATAAGCTTTTCATCTCCTCTCTTCTGAATTACAGAGATCAGATAAAACTACTTGGTAAAAAT GACCTCTTGTCATGTTGCTAAAGAACCTATAAAAAAGGTTGCTATCTTTGGAGGAACTCATGGGAACGAACTAACA GGAGTATTTCTAGTTAAGCACTGGCTAACGAATGGCGCTGAAATTCAGAGAACAGGACTGGAAGTAAAACCATTTA TTACCAACCCAAGAGCAGTGGAGAAGTGTACCAGATATATTGACTGTGATCTGAATCGTGTTTTTAACCTTGAAAA TCTTGGCAAAAGGATGTCAGAGAATCTGCCCTACGAAGTGAGAAGGGCTCAAGAAATAAACCACTTATTTGGTCCA AAAAATAGTGAAGACGGCTATGATATTATTTTTGACCTTCATAACACTACTTCTAATATGGGGTGCACTCTTATTC TTGAAGATTCCAGGAATGACTTTTTAATTCAGATGTTTCACTATATTAAGACTTCTTTGGCTCCATTACCCTGCTA CATTTATCTTATTGATCATCCTTCTCTCAAATATGCAACTACTCGTTCTATTGCCAAGTATCCTGTTGGCATAGAA GTTGGTCCCCAGCCTCAAGGTGTTTTAAGAGCTGATATTTTGGATCAAATGAGAAAAATGATTAAACATGCTCTTG ATTTTATATATGATTTCAATGAAGGAAAAGAATTTCCTCCTTGTGCTATTGAAGTGTATAAAATAATAGAGAAAGT TGATTATCCCAGGAATGAAAGTGGAGAAATTGAAGCTGTTATCCATCCTAATCTGCAGGATCAAGACTGGAAACCG TTACACCCTGGGGATCCCGTGTTTGTGTCACTTGATGGAAAGATGATTCCGCTGGGTGGAGACTGTACCGTGTACC CTGTGTTTGTGAATGAGGCTGCATATTATGAAAAGAAAGAAGCTTTCGCCAAGACAATTAAACTGACACTCAGTGC AAAAAGCATTTGCTCCTCTTTCCACTAGAAATCACTGCTAGCTCACCGTTATAGGGCATCTTGAAAACTTCTAGAA TCTGTGAGCTGTTCAAGAGCATGCTTGTGCCTTATTCTAGTTCATCTCCAAGTCCCCTGGCCCATGCCTCACACAG TAAGCATGCAGACCAGGAAAGGGGAAGAATTAATTAGTGAATGCCTTTTAAGGATATCATATTTTATGTGTAGCTT ATTCAAAGAAGTATACTTCTTATTTCTATACAGCTGTCTATACATGACACTTTGATAGCTTACATTGTTATTAATA AATACCCTTTACATTCAAACCATAAAATGAAAATAGATACTATATGCAAAGTTACCCACTTGGACATACAATGAGA CAGAATGAAAGAGATTTTCAATTAATATTTAAATGCTACTAGAAATTAACAGTACATATTAGGTATGTTAAATTTT TGATATTTGAATTAATGACAGTATATTAAATATCCATTC >Marmota_monax TGTAACAGAAGATGTTTAAAGTCTTCCACTCAAGGGAACTCTGTACTTTGCACTTTGGTTAAATTCTCATTTGAAT TTAAATTTCTAAACTTTTCTTAGGACCTTAAGCTTCCTTTGATCTCCTCTCTTCTGAATTGCAGAAATCAGATAAA ACTATTGGTAAAATGACCTCTCCTCACATTACAGGAAAACCTATAAAAAAGATTGCTATCTTTGGAGGAACTCATG GGAATGAGCTAACGGGAGTATTTCTAGTTAAGCACTGGCTGGAGAATGACGCTGAGATTCAGAGAACAGGGCTGGA AGTAAAACCATTTATTACCAACCCAAGAGCAGTGAAGAAGTGTACCAGATATATCGACTGTGATCTGAATCGTGTT TGTGACCTTGAAAATCTTGGCAAAGAGATGTCAGAGGATTTGCCATATGAAGTGAAAAGGGCTCAAGAAATAAATC ATTTATTTGGTCCAAAAAACAGTGAAGATTCCTATGACATAATTTTTGACCTTCACAACACAACTTCTAACATGGG GTGCACCCTTATTCTTGAAGATTCCAGGAATGACTTTTTAATTCAGATGTCTCATTATATTAAGACTTCTTTGGAT CCATTACCCTGCTATGTTTATCTCATTGAGCATCCTTCCCTGAAATACACAACCATTTCTTCCGTAGCCAAGTATC CTGTTGGTATAGAAGTTGGTCCCCAACCCCAGGGTGTTCTGAGAGCTGATATTTTGGATCAAATGAGAAAAATGAT
>Phoca_vitulina CAAGAGAACTCTGCACTTTGCACTTTGGTTAAAGTCTCATTTAAATTTAAATTTCTAAACTTTTTTAAAGAAATTT TTATTTGATCTCCTCTTTTCTGAATTGCAGAAATCAGATAAAACTTCTTGATAAAAATGACTTCTTGTCATGTTAC TGAAGATCCTATAAAAAAGGTTGCTATCTTTGGAGGAACTCATGGGAATGAGTTAACAGGAGTATTTCTAGTTAAG CACTGGCTGGAGAATGGCGCTGAGATTCAGAGAACAGGGCTGGAAGTAAAACCATTTATTACCAACCCAAGAGCAG TGAAGAAGTGTACCAGATATATCGACTGTGACCTGAATCGAGTTTTTGACTCTGAAAATCTTGGCAAAACCATGTC AAAGGATTTGCCATATGAAGTGAGAAGGGCTCAAGAAATAAATCATTTATTTGGCCCAAAAGACAATGAAGATTCC TATGACGTTATTTTTGACCTTCACAACACTACTTCTAACATGGGATGCACTCTTATTCTTGAAGATTCCGGGAATG ACTTTTTAATTCAGATGTTTCATTATATTAAGACTTCTTTGGCTCCATTGCCCTGCTATGTTTATCTTATTGAACA TCCTTCCCTCAAATATGCAACCACTCGTTCTATAGCCAAGTATCCTGTTGGTATAGAAGTTGGTCCCCAGCCTCAA GGGGTTCTGAGAGCTGATATTTTGGATCAAATGAGAAAAATGATTAAACACGCTCTTGATTTTATACAGAATTTCA ATGAAGGAAAAGAATTTCCTCCCTGTGCTATTGAAGTCTATAAAATAATGGAGAAAGTTGATTATCCCAGGAATGA AAATGGAGATATTGCTGCTATTATCCACCCTAATCTGCAGGATCAAGACTGGAAACCGCTGCACCCTGGGGATCCT GTGTTTTTAACTCTTGATGGACAGATTATTCCACTGGGCGGAGATGGTACTGTGTACCCAGTGTTTGTAAATGAGG CCGCGTATTATGAAAAGAGAGAAGCTTTCGCAAAGACAACCAAACTAACACTCAACGCAAAAAGTGTTCGCTCCTC TTTGCATTAGGAATCACTTCTAGCTCACCGGTTGTACAGGACCTCTACTAGTTTGTAAGCTCTTGAAGGGCAGGAT CGTGCCTTATTCAACTTCACACCTGTGGCCCCTAGTCCAGTGCCTTGCACACAATGGGCATTGAGGCAAATTTTCT GAATGAATGAATAAATTAATGAGTATCTCTAAAATATCATATTGGGTAGGTAGCTTATTCAAAGAGGTGCATTTCT TATTTCTGTATAGCTCCTTATATATTCTACTTCAGTAGTTTAAGATTCTGAATAAAACAGCTTTTAAATTCAAATT TCAAAATTGAAATGGATACTATCTACAAAAATTATTAACTTGAGCATAGAATTAAATGTGTTTTCAAGTAATGTAT AAATGCTACTAGAAACTAATGATGCAGACATGCTATTTTTAAATTTTTCACATTTGAATTAATGATAATATATTA
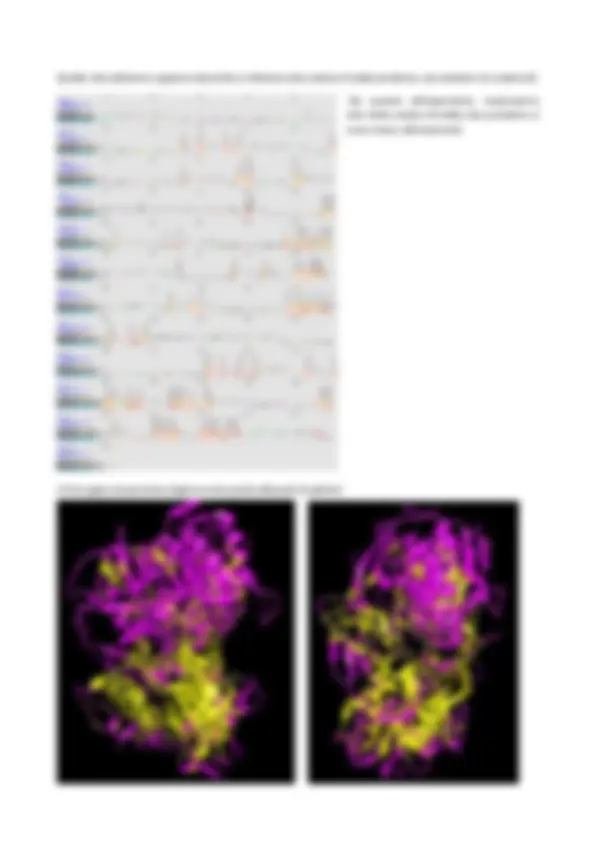
8. Tra le sequenze nucleotidiche scelte, effettuare multiallineamenti per la ricerca delle regioni conservate utilizzando quattro diversi programmi (CLUSTALw, Clustal Omega, Muscle e MAFFT) e commentare eventuali differenze nei risultati; Ho copiato le 8 sequenze e ho eseguito i multiallineamenti con i quattro diversi programmi. CLUSTALW è uno dei primi programmi di allineamento multiplo ampiamente utilizzati ed è noto per la sua semplicità e affidabilità. Fa parte della famiglia dei programmi di “allineamento globale progressivo”. Clustal Omega, successore di CLUSTALW, è stato sviluppato per migliorare la velocità e la precisione dell'allineamento rispetto al suo predecessore. Utilizza un approccio iterativo basato su modelli nascosti di Markov (Hidden Markov Models, HMM), migliorando progressivamente l'allineamento. Muscle consente di utilizzare matrici diverse, prodotte a partire da un multiallineamento, e in questo caso parte da un allineamento CLUSTALW. Da questo, si può leggermente modificare creando un nuovo albero filogenetico e un nuovo allineamento. Infine, suddivide gli alberi filogenetici e considera sequenze differenti, esaminando diversi sotto-allineamenti per perfezionare il risultato. MAFFT: è un altro popolare metodo di allineamento multiplo, basato su complessi modelli matematici ed è molto rapido. Utilizza la trasformata di Fourier e può essere utilizzato sia in modalità progressiva che iterativa.
Un asterisco (*) indica che tutte le sequenze in quella colonna hanno lo stesso nucleotide, quindi è una posizione altamente conservata. Dove una sequenza è più corta, il programma mette i GAP (-) e non riporta asterischi. Clustal Omega :
Anche se l'output può apparire simile a prima vista (poiché entrambi utilizzano il formato CLUSTAL per la visualizzazione), ci sono alcune differenze sottili legate ai metodi che usano per generare l'allineamento. Entrambi utilizzano graficamente * e -. Inoltre, Clustal Omega tende a produrre un allineamento graficamente più preciso e pulito rispetto a CLUSTALW. Le sequenze appaiono in un ordine diverso tra CLUSTALW e Clustal Omega perché i due programmi usano approcci diversi per costruire l'albero filogenetico e per determinare l'ordine di allineamento.
Come CLUSTAL Omega, MUSCLE ricalcola più volte l'albero guida per ottenere un allineamento ottimale. Di conseguenza, l'ordine delle sequenze può variare rispetto a quello originale, risultando in un output differente da quello di CLUSTALW. MUSCLE tende a gestire meglio i gap rispetto a CLUSTALW e, a volte, anche CLUSTAL Omega. Gli allineamenti prodotti da MUSCLE possono risultare graficamente più "puliti", con distribuzioni di gap più coerenti e meno lacune non necessarie. MAFFT :
Grazie alla sua capacità di ricalcolare le posizioni, MAFFT gestisce in maniera molto efficace i gap, specialmente nelle sequenze lunghe e divergenti. Nei risultati grafici, questo si traduce in una minore quantità di gap mal posizionati e in un allineamento più fluido e coerente. Nella configurazione, i punti (.) rappresentano cambiamenti tra nucleotidi che sono considerati conservativi, come le transizioni A- G o C-T. Questo riflette una somiglianza funzionale o chimica tra i nucleotidi. Dopo aver confrontato gli allineamenti con diversi programmi, non si riscontrano differenze significative, tranne il cambiamento nell'ordine delle sequenze. In generale, le sequenze sono più conservate nella parte centrale, mentre la mancanza di allineamento all'inizio e alla fine è dovuta alle diverse lunghezze delle sequenze.