Scarica Informatica - Appunti e più Appunti in PDF di Informatica solo su Docsity!
UNIVERSITÀ CA’ FOSCARI DI VENEZIA - COMMERCIO ESTERO E TURISMO
ELEMENTI DI INFORMATICA PER L’ECONOMIA
SETTIMANA 1
I TERMINI DELL’INFORMATICA
L’informatica è la scienza applicata che si occupa del trattamento automatico dei dati mediante l’ausilio di strumenti ad hoc. Gli strumenti informatici generalmente consentono di: ▶ ridurre i tempi di elaborazione ▶ aumentare l’affidabilità delle operazioni ▶ liberare l’attività umana da incombenze ripetitive e magari “noiose” ▶ migliorare l’accesso ad elaborazioni che richiedono competenze poco comuni Il termine informatica deriva dal fr. informatique, comp. di informat(ion) e (automat)ique informazione automatica, termine coniato da Dreyfus (1962), tuttavia l’etimologia della parola dovrebbe essere ricondotta alla combinazione di due parole, informazione e automatica, che derivano rispettivamente dal verbo latino informare e al sostantivo greco autòmatos ) Computer science è lo studio degli algoritmi matematici e dei processi che interagiscono con i dati e possono essere rappresentati sotto forma di programmi. Economia è la scienza sociale che studia la produzione, la distribuzione e il consumo di prodotti e servizi e si occupa della soddisfazione dei bisogni individuali e/o collettivi in situazione di risorse scarse (limitate o finite). Il termine economia deriva dal greco (oˆικoς (oikos), “casa” inteso anche come “beni di famiglia”, e νo´μoς (nomos), “norma” o “legge”). ESEMPI DI INFORMATICA PER L’ECONOMIA Esempio 1 https://www.borsaitaliana.it/borsa/azioni/contratti.html?isin=NL0011585146&lang=it&page= Esempio 2: Considerate due investimenti il primo in BOT e il secondo in Bitcoin. Quale investimento è più conveniente? Probabilmente avremo difficoltà a rispondere a tale domanda perché abbiamo incertezza sull’investimento in Bitcoin perché non conosciamo completamente il fenomeno.
L’investimento in BOT L’investimento in BitCoin
▶ Ammontare del flusso monetario in uscita certo ▶ Ammontare del flusso monetario in entrata certo ▶ Data di rimborso nota ▶ Ammontare del flusso monetario in uscita certo ▶ Ammontare del flusso monetario in entrata incerto ▶ Data di rimborso incerto Che cos'è l’incertezza? L’enciclopedia Treccani riporta che l’incertezza, "in economia [è] l’impossibilità di stabilire l’esito certo di eventi futuri. ▶ Si parla di incertezza forte quando non si conosce la distribuzione di probabilità degli eventi futuri, a differenza dell’incertezza debole, per la quale si può invece attribuire una probabilità per ogni stato o esito.
▶ La presenza di incertezza complica il processo decisionale in campo economico dal momento che usualmente gli operatori si trovano a dover effettuare al tempo presente delle scelte (per es. di produzione) condizionate da grandezze il cui valore sarà noto solo nel futuro (come l’andamento della domanda e quello dei prezzi). L’incertezza si può ridurre aumentando la conoscenza, per aumentare la conoscenza è necessario misurare e per misurare bisogna sapere qual è l’oggetto di misurazione. Per esempio, Se si considera un investimento per ridurre l’incertezza (e il rischio) sarà necessario conoscere: ▶ i flussi finanziari in uscita ▶ i flussi finanziari in entrata ▶ le tempistiche dei flussi Il processo di misurazione crea dati che devono essere: ▶ archiviati/immagazzinati per potere essere accessibili successivamente alla loro raccolta ▶ elaborati per trasformare i dati in informazioni Ciò ci riporta alla definizione di informatica INFORMATION AND COMUNICATION TECHNOLOGY (ICT) L’ambiente che integra informatica e telecomunicazioni e comprende un insieme di tecnologie, protocolli e metodi per la realizzazione di sistemi di ricezione, elaborazione e trasmissione di dati e informazioni in formato digitale. Il progresso dell’ICT è alimentato dalla continua innovazione che ha consentito di conservare, condividere ed elaborare le informazioni in modo sempre più efficiente e meno costoso. L’innovazione dell’ICT riguarda: ▶ Hardware ▶ Software ▶ Comunicazione SETTIMANA 2 I computer si differenziano per caratteristiche: ▶ velocità di elaborazione ▶ capacità di archiviazione ▶ sicurezza ▶ dotazione di periferiche ▶ capacità di connessione ▶ dimensioni (portabilità) ▶ modularità e scalabilità L’HARDWARE Cambiamenti importanti nella componente dura dell’ICT: ▶ Capacità di calcolo ▶ Capacità di archiviazione ▶ Riduzione delle dimensioni ▶ Ampliamento funzionalità La parola Hardware potrebbe essere tradotta letteralmente con ferraglia e costituisce tutto ciò che nel computer ha consistenza materiale, in altre parole è il supporto fisico del computer.
- L’architettura di von Neumann La macchina di von Neumann, questa era costituita da 5 componenti secondo lo schema seguente: la memoria , l' unità aritmetico-logica ( ALU, Arithmetic Logic Unit ), l' unità di controllo ( control unit ) e i dispositivi di ingresso e uscita ( input , output ).
▶ Periferiche gestiscono l’interazione con il mondo esterno mediante dispositivi di input e/o di output) ▶ Bus : canale di comunicazione che gestisce lo scambio di informazioni tra i sottosistemi. HARDWARE: LA SCHEDA MADRE (MOTHER BOARD) Le componenti interne di un computer moderno (sottosistemi di elaborazione e di memorizzazione e i bus) sono connesse ad un dispositivo noto come Scheda Madre. Sulla scheda madre si trova anche l’UEFI (Unified Extensible Firmware Interface) che ha sostituito il BIOS (Basic Input Output System), che si occupa di svolgere le prime operazioni quando si accende il computer (controllo periferiche, controllo memoria, etc.). Le attività del calcolatore vengono svolte dalle varie componenti che comunicano fra loro tramite circuiti dedicati: ▶ Bus di dati : trasferisce dati tra memoria e CPU e tra CPU e interfacce IO. ▶ Bus di indirizzi : identifica posizione delle celle di memoria. ▶ Bus di Controllo trasmette i segnali che selezionano le unità interessate al trasferimento dati e la direzione dello scambio.
HARDWARE: LA CPU
La CPU contiene un unico frammento di silicio che ha proprietà di semiconduttore (proprietà intermedie tra un conduttore ed un isolante). Il silicio viene drogato con impurità ed il movimento nel silicio di tale impurità consente di veicolare l’informazione (come le bolle d’acqua portano il calore in superficie dal fondo di una pentola). La CPU svolge sia operazioni nobili di calcolo sia operazioni elementari di spostamento/controllo/interrogazione. Per queste ultime operazioni la CPU è coadiuvata dai controller delle periferiche e da circuiti di supporto. La CPU è la parte di hardware che tipicamente lavora a frequenze maggiori (3-4 Ghz). La RAM ed il BUS lavorano a frequenze che attualmente raggiungono i 4600 Mhz per canale decisamente inferiori rispetto a quelle della CPU. Questo può provocare i cosiddetti problemi di bootleneck. Tavolta parte del carico computazionale viene svolto da componenti dedicate come ad esempio la GPU (Graphical Processing Unit). Nella CPU si trovano: ▶ unità aritmetico-logica ▶ celle di memoria interna alla CPU ▶ unità di controllo che coordina le varie componenti nell’esecuzione dei programmi HARDWARE: LA MEMORIA I dati, utilizzati o prodotti dal calcolatore, risiedono nella memoria. Nella memoria principale vengono caricati il programma che si vuole eseguire e i dati relativi. Questa memoria è un insieme di byte identificabili con indirizzi. Un byte è la più piccola unità di memoria indirizzabile, contenente, per convenzione, otto cifre ( digits ). Ciascuna di queste otto cifre è una cifra binaria o bit che può assumere quindi solo i valori 0 oppure 1 Il numero di byte utilizzabili da un processore come una singola entità dipende da come è stata progettata la CPU ed individua una parola ( word ) su cui la CPU esegue le operazioni. Al momento del caricamento di un dato in memoria si alloca uno o più byte a seconda della dimensione del dato (se il dato e di un solo byte occuperà un byte e sarà gestito tramite l’indirizzo del byte, se, invece, il dato e di quattro byte verrà immagazzinato in un’area di memoria di quattro byte contigui e gestito tramite l’indirizzo del primo byte). Il contenuto di due celle di memoria differisce se anche solo un bit differisce tra le due. Nei portatili odierni si possono avere tipicamente parole di quattro byte (32 bit) oppure otto byte (64 bit).
La memoria più lenta solitamente con capacità maggiori e meno costosa è la memoria di massa (o memoria secondaria). Si tratta dell’HD o dell’SSD, ma potrebbe essere anche un supporto removibile (CDROM o similari). La lentezza è dovuta alla presenza di una componente fisica (quella che fa girare il disco e il braccio del lettore che deve spostarsi) E’ una memoria dove risiedono i programmi (non “attivati’ ’) e gli archivi dati. Al secondo livello troviamo una memoria più veloce, meno capiente e più costosa è la memoria primaria. E’ una memoria a stretto contatto con la CPU, in essa vengono caricati programmi e dati che poi vengono passati alla CPU. Si tratta di una memoria volatile. Poiché la velocità del processore potrebbe essere tale da richiamare dati o istruzioni dalla RAM ad una velocità superiore a quella a cui può funzionare la memoria stessa, sono state introdotte delle memorie cache. Sono memorie ancor meno capienti, più costose e più veloci. In esse vengono memorizzati dati e istruzioni che vengono ripetuti frequentemente e pertanto essendo più veloci da richiamare e più vicini all’ALU riduce i tempi di latenza migliorando le performance della CPU. Anche questa è una memoria volatile. ▶ L1 è interna alla CPU ▶ L2 può essere interna alla CPU ▶ L3 è esterna alla CPU ▶ L4 è esterna alla CPU I DISPOSITIVI DI INPUT/OUTPUT Ogni periferica, o dispositivo di I/O, è costituita da 3 componenti: ▶ Una componente visibile, il dispositivo in senso lato ▶ Una componente elettronica di controllo chiamata controller ▶ Una componente software, detta driver INPUT OUTPUT ● Tastiera ● Mouse (e altro puntamento) ● Scanner ● Microfono ● Webcam, Macchine fotografiche e telecamere digitali ● Lettori di codici a barre ● Schermo ● Stampante ● Casse acustiche ● Plotter ● Proiettore INPUT/OUTPUT ● Touchscreen ● Modem, USB port, WiFi, Bluetooth ● Memorie secondarie INPUT
- la tastiera e il mouse La tastiera è una periferica di input del PC. La tastiera è una periferica “lenta” ed il microprocessore passa molto tempo ad interrogarla per verificare se l’operatore ha digitato un tasto. Ce n’è una diversa per ogni (o quasi) linguaggio parlato. Può essere connessa al BUS mediante filo o wireless. Il mouse è una periferica che permette di “muoversi” sullo schermo in maniera agevole. I più comuni sono opto-elettronici (con un diodo laser) collegabili mediante cavi o sistemi WiFi e bluetooth. Nei portatili sono stati sostituiti dal touchpad che rileva il movimento del dito misurando la sua capacità elettrica.
OUTPUT
- la stampante Le stampanti costituiscono un dispositivo lento essendoci una componente meccanica. Le prime stampanti erano B/N ed utilizzavano una matrice di aghi (9 o 24) per scrivere caratteri e simboli. La risoluzione di stampa (qualità) è misurata in Dots Per Inch (DPI). Ora le stampanti usano due tecnologie (entrambe B/N e colori): ● getto di inchiostro in cui l’inchiostro è prelevato da cartucce ed espulso elettronicamente attraverso minuscoli ugelli; ● laser in cui un laser viene usato per distribuire (elettrostaticamente) un materiale termosensibile (toner) su un foglio, per poi fissarlo per scioglimento sul foglio stesso.
- casse acustiche Gli altoparlanti possono essere integrati al case del PC oppure esterni. Sono controllati da una Scheda Audio, dedicata o integrata nella scheda madre, in modo da non caricare il microprocessore da molte operazioni non di calcolo. La scheda audio è importante anche per processare l’input del microfono permettendo di digitalizzare (convertito in sequenza 0/1) il suono registrato.
- schermo Il monitor consente la visualizzazione dell’output. Ciascun punto sullo schermo (pixel) viene acceso/spento creando ogni possibile simbolo. Il monitor/schermo viene controllato da una Scheda Video. Gli schermi piatti sono basati su diverse tecnologie principalmente LCD (Liquid Crystal Display) e LED (Light Emitting Diodes), da confrontare su parametri quali ▶ Pixel per pollice (PPI): più elevato migliore è la definizione dell’immagine ▶ Risoluzione: numero di pixel orizzontali x numero di pixel verticali ▶ Refresh rate: numero di volte per secondo che viene aggiornato il buffer del display ▶ Tempo di risposta: il tempo che impiega un pixel per cambiare colore ▶ pannello:
- TN (Twisted Nematic) tempi di risposta veloci ma angolo di visione stretto, più economici.
- IPS (In Plain Switching) tempi di risposta più lenti, angolo di visione più largo, migliore qualità del colore, prezzo più alto. Periferica di Output o periferica di Input/Output? Recentemente con la diffusione degli smartphone e dei tablet gli schermi (anche per laptop) sono anche una periferica di input, sostituendo il mouse e/o la tastiera.
- hard disk Hard-disk, detto anche disco rigido, consente di immagazzinare grandi quantità di dati (tipiche dimensioni nei PC da 100 Gb a 1.5 Tb). Memoria non volatile costituita da una serie di dischi sovrapposti non flessibili (da qui il nome), su cui i dati vengono prelevati/depositati mediante un braccio elettro-meccanico, pilotato da un controller. I dischi ruotano a velocità standard di circa 5000-7200 giri/minuto. I dati sono organizzati in unità logiche definite files (archivi). I più recenti sono memorie Solid State Disk (SSD) in questo caso essendo basato su un semiconduttore la memorizzazione avviene senza l'ausilio di organi meccanici. Tale caratteristica rende più veloce la lettura e la scrittura dei dati.
I numeri decimali vengono espressi in formato binario 33 10 = 100001 2 e 75 10 = 10010112 ; I numeri binari vengono rappresentati in virgola mobile cioè come segno, esponente e mantissa; ad esempio il numero 33 ha la seguente rappresentazione a 32 bit secondo gli standard IEEE 754 : 0 00000110 10000100000000000000000 I numeri vengono sommati, poi il risultato viene convertito in numero binario, infine il numero binario viene convertito in numero decimale e fornito come output. ▶ Capacità di archiviazione ▶ Riduzione delle dimensioni Vi è un processo di miniaturizzazione dei componenti e dei supporti. Ad esempio la dimensione fisica del processore non è variata pur aumentando notevolmente la sua capacità. I supporti di archiviazione dati sono stati ridotti fisicamente e aumentati in termini di capacità. ▶ Ampliamento funzionalità Un singolo dispositivo consente di soddisfare più bisogni perché incorpora in se più funzioni. Questa evoluzione fa parte di un processo più ampio detto convergenza digitale.
- convergenza digitale Unificazione di prodotti progettati per compiere funzioni diverse in un unico nuovo prodotto. Elemento che accomuna i prodotti è l’utilizzo di tecnologie digitali Ad esempio: gli smartphone che oltre a svolgere la loro funzione di telefono possono sostituire una calcolatrice, la sveglia, la radio ecc... La convergenza digitale è un fenomeno che ha portato le grandi aziende informatiche ad approdare in nuovi settori (es. Microsoft con Xbox o Apple con Apple TV). Alcuni dispositivi di uso comune hanno almeno in parte funzionalità analoghe ad un computer e sono assai spesso dotate di una propria CPU: ▶ Notebook o Laptop: sono PC con funzionalità e caratteristiche ormai in linea con i computer fissi da tavolo. La componentistica per Notebook è diversa da quella per Desktop, ma con requisiti del tutto analoghi. ▶ Videocamere e Macchine fotografiche digitali: sono collegabili al PC mediante interfaccia USB. Le versioni meno economiche sono dotate di una CPU. I ▶ Telefoni cellulari / Palmari: utilizzano CPU con frequenze di 500 Mhz -3 Ghz (più lenti dei PC), ed adottano sistemi operativi dedicati (semplificati). Consentono anche la connessione ad Internet con WiFi e sono dotati di Bluetooth. Sono molto più lenti di un Desktop. ▶ Lettore MP3 e MPEG: dispositivi specifici per ascoltare file musicali (.wav, .wma, etc.) e guardare video (.mpg, .jpg, wmv., etc.) IL SOFTWARE Istruzioni codificate all’interno della memoria per essere eseguite dall’hardware.garantisce flessibilità di utilizzo al calcolatore e si suddivide in: ▶ Di base che interagisce direttamente con l’hardware permettendo e controllando il suo funzionamento (Sistemi operativi, Linguaggi di programmazione, Utilità di sistema) ▶ Applicativo costituito dai programmi utilizzati dagli utenti per acquisire ed elaborare i dati al fine di produrre informazioni di cui si necessita (es. Firefox, Internet Explorer, Excel, Word, PowerPoint etc...) Il software è organizzato in programmi. Ciascun programma è scritto in un linguaggio: teniamo conto che in un PC si parlano anche 20-30 linguaggi differenti. Ciascuna operazione complessa da far svolgere alla CPU è scritta in un linguaggio evoluto, poi è tradotta in un linguaggio meno evoluto, così a cascata fino ad arrivare al linguaggio macchina che utilizza un alfabeto binario 0-1 che può essere eseguito dall’hardware.
Ciascun livello di hardware nel PC è in grado di leggere ed interpretare solo un tipo di linguaggio e non altri, al fine di rendere la macchina più efficiente in quanto consente di integrare hardware e software. Ogni programma necessita di un traduttore specifico in base a: ▶ linguaggio di programmazione usato ▶ linguaggio macchina (dipende quindi dalla specifica macchina su cui dovrà funzionare). Il traduttore può essere: ▶ Compilatore: traduce l’intero programma in linguaggio ad alto livello (input) producendo un programma eseguibile dalla macchina, cioè in linguaggio macchina (output). ▶ Interprete: traduce le singole istruzioni del programma sorgente e le fa eseguire direttamente una alla volta. Bootstrap: cosa succede all’avvio di un PC? La macchina in fase di avvio trasferisce il sistema operativo dalla memoria di massa (ove risiede) alla memoria principale: tale attivitá é svolta dal firmware il cui ruolo è fortemente legato alla macchina sulla quale viene avviato Il sistema operativo viene avviato e prende possesso della macchina (es. esegue i programmi nel menù di Avvio e della Barra delle Applicazioni) poi restituisce il controllo all’utente Il sistema operativo avvia i programmi applicativi decisi dall’utente (es. un gioco, la videoscrittura, etc.), inoltre avvia programmi che monitorano le periferiche periodicamente. SOFTWARE: SISTEMI OPERATIVI ▶ Microsoft Windows: è a pagamento ed è tra i più diffusi al mondo. Fornisce poche applicazioni incluse come un text editor semplice, un browser, etc. A causa della necessità di renderlo compatibile con vecchi software, risulta spesso instabile. ▶ Unix/Linux: sono free (non a pagamento), inoltre sono open source, ovvero è possibile disporre del codice sorgente (linguaggio) in cui sono scritti ed eventualmente modificarli a scelta. Sono creati nell’ambito di istituti di ricerca e sono molto stabili. Le versioni di questi sistemi operativi vengono dette “distribuzioni” ▶ Mac OS: a differenza dei precedenti è un sistema operativo proprietario della Apple Computer, che lo installa sulle macchine Macintosh. ▶ Android, Windows Mobile, Symbian, etc.: utilizzati su dispositivi palmari e tablet-PC. Nella preistoria dell’informatica il sistema operativo era un unico grande “programma”, nel quale erano scritte tutte le istruzioni per tenere sotto controllo l’hardware. Ora i sistemi operativi sono modulari, ovvero contengono blocchi di istruzioni, ognuno dei quali è deputato ad eseguire una specifica operazione. Questo consente: ▶ Flessibilità nello scriverlo (ogni programmatore scrive il proprio modulo) ▶ Robustezza nell’eseguire compiti (è possibile testarlo su casi specifici)
Questo perché un PC interagisce con diversi tipi di memoria, inclusa la memoria non volatile dell’hard disk o dei vari supporti (CD, DVD, Floppy Disk, pendrive, etc.). Questa parte del sistema operativo può anche essere molto complessa per consentire la compatibilità con sistemi operativi obsoleti. Per ogni cartella o file, il File System memorizza e gestisce: ▶ il formato: tipo di dati e applicazione associata ▶ dimensioni (in multipli di byte) ▶ data e ora di creazione e di ultima modifica ▶ autorizzazioni dei singoli utenti Ciò che l’utente finale vede è un’organizzazione del computer e dei dischi in cartelle (o directory) che coincide con la definizione del nome dei singoli file; ad es. " C:\Documents\Newsletters\Summer 2018.pdf " fa riferimento ad un file (siamo con sistema operativo Windows) presente nel disco C nella cartella Documents che al suo interno contiene un’altra cartella Newsletters al cui interno c’è il file Summer.pdf che è un file di tipo Portable Document Format leggibile ad esempio con Acrobat Reader.
- Gestore della rete I moderni SO integrano la gestione della connessione di rete (NOS = Network Operating System) ma è necessario gestire il vantaggio dello scambio di dati con il problema della privacy. Le diverse interazioni tra utenti e calcolatore nell’ambito della rete: ▶ Interazione uomo-calcolatore locale ▶ Interazione uomo-calcolatore remoto: tramite un’applicazione client nel computer locale, l’utente interagisce tramite un’applicazione server su un calcolatore remoto connesso in rete. ▶ Interazione uomini mediante calcolatori: tramite un’applicazione client nel computer locale, l’utente interagisce (magari usando più server) con un altro utente che usa un’altra applicazione client su un calcolatore connesso in rete
- Interprete dei comandi Interfaccia Utente: è quella parte del SO che si “allontana” dall’hardware e determina l’interazione tra l’utente e la macchina. Importante è l’autenticazione; è una parte rilevante del SO e deve considerare potenzialmente anche l’uso da parte di utenti inesperti. Anche se tecnicamente non è rilevante, può determinare le fortune/sfortune di un sistema operativo (es. DOS vs. Windows) Applicazioni (utilità) del sistema: sono software di ausilio che viene integrato con il sistema operativo, affinché l’utente possa più agevolmente usare le potenzialità del PC (es. Internet Explorer e Notepad per Windows, l’orologio o un calendario perpetuo, la calcolatrice, un player multimediale, etc.). Sono progettate in rapporto all’interfaccia utente del sistema operativo usato. Importanti innovazioni nel software sono: ▶ Facilità di utilizzo: non è necessario saper programmare (anche se sarebbe utile!). Es: per creare un testo non è necessario programmare il pc, ma è sufficiente utilizzare un software che funziona da interfaccia tra l’utente e la macchina. ▶ Ubiquità: posso usare lo stesso software su PC, Tablet, Smartphone. Es: il browser Chrome può essere installato e utilizzato su smartphone, su tablet, su pc con diversi sistemi operativi (iOS, Android, Mac OSX, Windows, ...). ▶ Fruibilità: non è necessario possedere il software perché vi è un accesso da remoto. Es.: per aprire file pdf, excel, word allegati ad una mail non è necessario avere il programma perché il file può essere “aperto” senza essere “scaricato”.
COMUNICAZIONE CON IL COMPUTER
Una volta che si sia progettato e costruito un calcolatore si pone il problema di comunicare con esso per dargli istruzioni. La situazione vede da un lato il calcolatore con un suo linguaggio specifico e dall’altro programmatori diversi, ciascuno con un proprio specifico linguaggio. Il problema e che questi linguaggi, a parte la differenza di simboli dell’alfabeto, utilizzati per comporre parole e frasi, e delle regole sintattiche, sono concettualmente diversi e sono stati sviluppati in epoche molto diverse, con metodi e finalità differenti. Quello della macchina è un linguaggio informatico, definito dai primi ingegneri ` che costruirono i primi calcolatori, mentre quelli dei programmatori sono linguaggi naturali che si sono evoluti per lo più per diffusione di idee. Nella progettazione e costruzione di un calcolatore non si devono affrontare e risolvere solo problemi hardware, ma anche il problema di come comunicare al computer le istruzioni che deve eseguire. Quindi il linguaggio della macchina è un linguaggio informatico, definito dagli ingegneri che progettarono e costruirono i primi calcolatori. Ma i linguaggi dei programmatori sono più simili al linguaggio naturale, che è concettualmente diverso dal linguaggio macchina non solo per l’alfabeto, ma anche per le regole sintattiche e soprattutto perché sono nati con metodi e obiettivi differenti.
- I linguaggi naturali I linguaggi naturali sono definiti da un numero ristretto di simboli con cui si possono costruire delle parole. Tali parole possono essere messe assieme, seguendo regole grammaticali, per esprimere concetti. Con i linguaggi naturali è possibile oltre che esprimere concetti anche contare ma non permettono di fare operazioni aritmetiche sulla base di regole generali precise. L’insieme dei linguaggi naturali oggi esistenti è molto ampio. Nel 1820 il fabbro analfabeta cherokee, Sequoyah, sviluppa un sillabario composto da 85 segni sillabici. Nel giro di poche generazioni tutti i Cherokee erano in grado di leggere e scrivere nella nuova lingua e pubblicare inoltre un giornale. A partire da una comunicazione verbale, si è passati a definire un numero ristretto di simboli con cui costruire delle parole, da assemblare, con regole grammaticali, per esprimere concetti Un problema legato ai linguaggi naturali è la possibile ambiguità delle parole o delle frasi. Può capitare, infatti, che la stessa frase in contesti diversi assuma significati diversi (es. Ho la fede). Di conseguenza utilizzare un linguaggio con le caratteristiche dei linguaggi naturali può avere conseguenze disastrose per l’esecuzione di un programma su di un calcolatore. È quindi necessario definire un linguaggio opportuno per comunicare con il calcolatore, con regole di scrittura non ambigue.
dall’aumento delle capacità di calcolo dei nuovi calcolatori. In generale, questi linguaggi evoluti sono stati sviluppati seguendo uno o più paradigmi di programmazione. L’introduzione successiva dei primi linguaggi ad alto livello (p.e. FORTRAN, COBOL, ALGOL) fu seguita da altri linguaggi, i cosiddetti linguaggi strutturati (per esempio il C e il Pascal), che furono la soluzione ad un certo numero di problemi e semplificarono in modo considerevole la scrittura di codici complessi. Nei linguaggi strutturati codice e dati possono essere compartimentalizzati, cioè́ isolati e nascosti al resto del programma. Tipicamente, per esempio in C, un insieme di istruzioni viene isolato dal resto racchiudendolo tra parentesi graffe: if (stepNum = 5) { ......... ......... } Le istruzioni tra parentesi graffe costituiscono un blocco di codice (code block) e vengono eseguite se stepNum ha il valore 5. Queste istruzioni costituiscono una unità logica: non possono essere eseguite l’una senza l’altra, bensì sequenzialmente, l’una dopo l’altra. I nuovi linguaggi permisero anche una maggiore comprensione della struttura del programma. I linguaggi strutturati hanno raggiunto il massimo negli anni ’70 del secolo scorso. L’aumentare ulteriore della complessità dei programmi ha messo in difficoltà anche questi linguaggi, non solo per la gestione dei dati ma anche per la manutenzione dei programmi prodotti. I programmi divennero il frutto del lavoro di più programmatori (ancora pochi rispetto allo standard odierno) e si riscoprì la validità di una vecchia affermazione ` popolare: indipendentemente da quante donne vengano assegnate al compito, far nascere un bambino richiede sempre nove mesi. Anzi, si trovò che il tempo di elaborazione del programma si allungava piuttosto che accorciarsi (uno dei primi lavori che misero in evidenza il problema fu quello di Brooks [1975]). Il problema nasceva dal fatto che bisognava comunicare a tutti i linguaggi C++ (1983) e Java (1995). I linguaggi di programmazione disponibili oggi per la programmazione dell'attività dei calcolatori, a livello di applicazione dell’architettura software, sono numerosi e specifici per il tipo di applicazione. Per sviluppare applicazioni si utilizzano quindi linguaggi progettati per permettere ad un utente di dare istruzioni al calcolatore in modo comprensibile all’utente ma seguendo regole rigorose di sintassi e con significato non ambiguo. Con i linguaggi di programmazione non c'è alcun margine per istruzioni di “buon senso”, né tantomeno per istruzioni che richiedano “intuizioni geniali”. I linguaggi di programmazione che permettono di sviluppare applicazioni sono detti linguaggi di alto livello ( higher level language ) perchè sono indipendenti dall’ hardware e comprensibili da parte degli utenti in lettura e scrittura. I linguaggi di programmazione di alto livello possono essere utilizzati tanto per compiti specifici come, per esempio, l’esecuzione su architetture parallele o la costruzione e la gestione di una base di dati, quanto per compiti di diverso tipo, per esempio intrattenimento o simulazione di sistemi fisici. In quest’ultimo caso si parla di l inguaggi di uso generale ( general purpose language ). E da sottolineare che oggi la maggior parte dei linguaggi di alto livello hanno introdotto elementi multiparadigma: il C++, dalla versione distribuita nel 2011, e Java, dalla versione distribuita nel 2014, hanno entrambi introdotto le cosiddette funzioni lambda per consentire, oltre ad una semplificazione del codice, la parallelizzazione sulle architetture multi–processore. IL PSEUDOCODICE Con lo pseudocodice si tenta di svincolarsi completamente dal linguaggio macchina e di avvicinarsi quanto più è possibile ai linguaggi naturali per definire istruzioni ( statement ) non ambigue da sottoporre al calcolatore. Un approccio di questo tipo permette di discutere
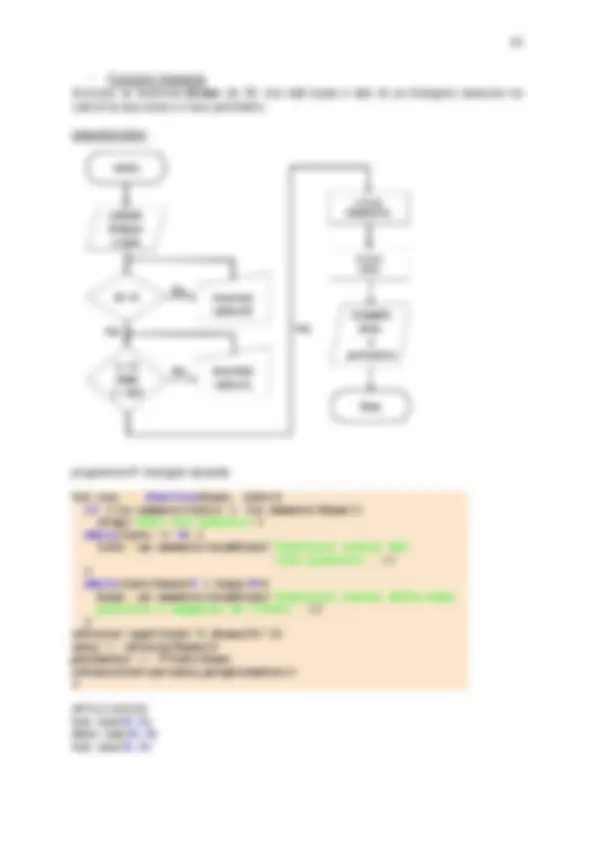
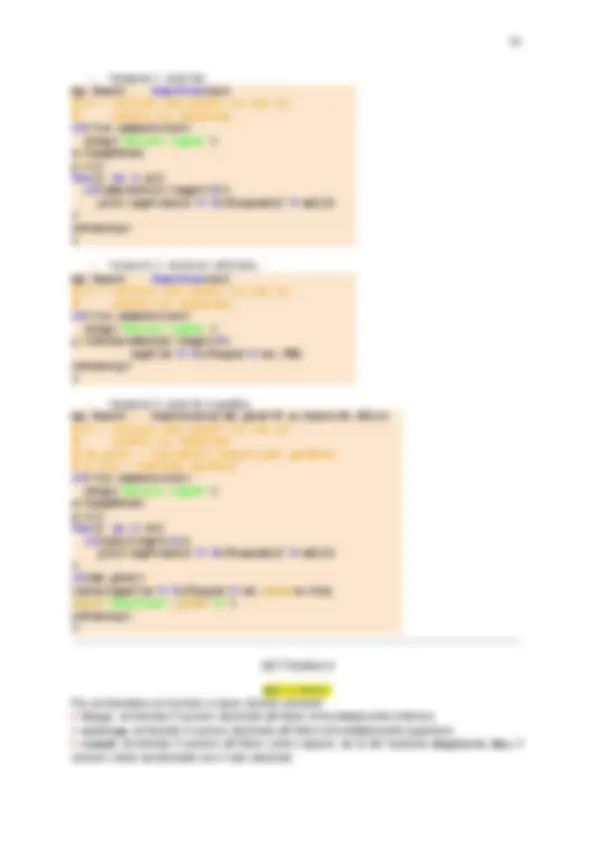
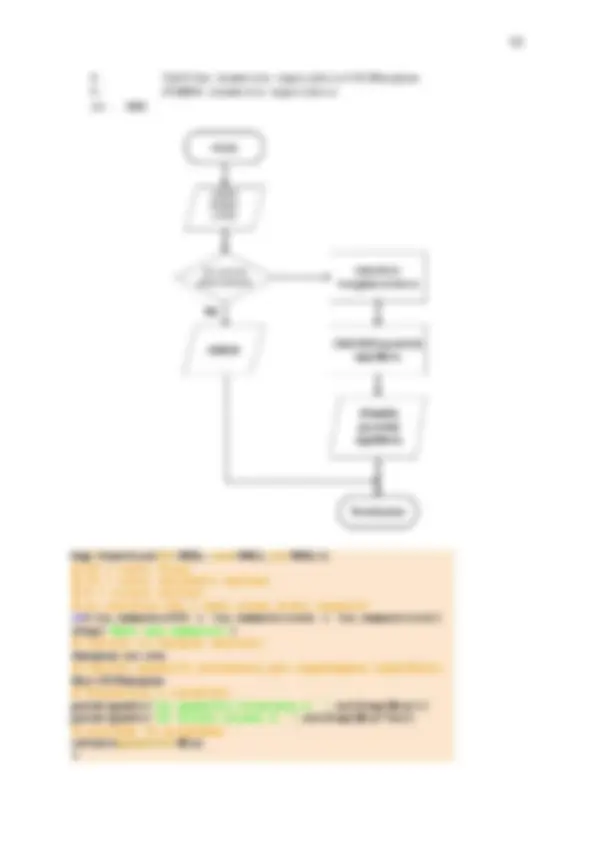
delle istruzioni da passare al calcolatore con termini molto più vicini al linguaggio naturale, senza ambiguità. Questa operazione è realizzabile, purché si riesca ad individuare un numero finito di strutture del tutto generali in un qualsiasi programma. Questo e possibile, infatti un qualunque programma può essere scritto con solo tre tipi di strutture: ● sequenza ( sequence ): sviluppo del programma secondo l’ordine delle istruzioni; ● selezione ( selection ): valutazione di una espressione logica il cui risultato determina la successiva esecuzione di una parte specifica del programma; ● iterazione ( iteration ): esecuzione ciclica di una serie di istruzioni identiche. Per queste tre strutture si possono definire istruzioni codificate senza necessariamente utilizzare un linguaggio di alto livello. Per l’esecuzione sequenziale, conveniamo di utilizzare le seguenti convenzioni: ● una riga per ciascuna istruzione, ● fine ( end ) per segnalare l’inizio (la fine) di un blocco coerente di istruzioni, ● nomi vicini al loro significato per le variabili coinvolte nel calcolo (per esempio, somma , sum ), ● ingresso ( input ) per ricevere in ingresso un valore di una variabile, ● uscita ( output ) per mostrare in uscita il valore di una variabile, ● il simbolo ← per assegnare valori ad una variabile, ● i simboli matematici +, −, ∗, / per le operazioni aritmetiche di base, somma, sottrazione, prodotto e divisione. Lo pseudocodice è la descrizione passo a passo del processo (o dell’algoritmo) in un linguaggio simile a quello naturale ed è utile per: ▶ descrivere come un algoritmo dovrebbe funzionare ▶ spiegare il processo di calcolo in termini meno tecnici ▶ progettare un codice in un gruppo di lavoro Essendo lo pseudocodice soggettivo è opportuno: ▶ indicare all’inizio lo scopo dell’algoritmo (all’inizio dello pseudocodice); ▶ scrivere un solo comando per riga; ▶ commentare ogni riga dello pseudocodice; ▶ utilizzare spazi bianchi e indentazioni per agevolarne la lettura e la comprensione. Ad esempio l’inserimento di una riga bianca tra “blocchi” di comandi aiutano a individuare differenti parti dello pseudocodice così come il rientro evidenzia i contenuti all’interno dei “blocchi”. SE il voto è superiore a 18 scrivi "superato" ELSE scrivi "non superato" ▶ L’utilizzare lettere maiuscole per indicare i comandi. ▶ Scrivere usando lessico semplice e vicino al linguaggio naturale ▶ Scrivere cosa il codice deve fare, non riassumerlo. Ad esempio il seguente segmento di pseudocodice non rispetta gli ultimi tre suggerimenti: Se l’input è dispari stampa "Y" risulta più chiaro ed efficace riscrivere le stesse operazioni nel seguente modo
Il processo di traduzione è realizzato da diversi programmi attraverso più passi eseguiti in successione o iterati, se ci sono degli errori. Ad ogni passo viene applicato un programma con funzioni diverse che permette, alla fine del processo, di eseguire il programma sulla macchina. I programmi utilizzati effettuano in sequenza o separatamente: ● la compilazione, tramite un compilatore ( compiler ); l’operazione preliminare, per ottenere un programma eseguibile sul calcolatore, consiste nella compilazione effettuata da un compilatore. Il compilatore, che e un programma appositamente scritto, verifica la correttezza lessicale e sintattica delle istruzioni e traduce le istruzioni, se corrette, in istruzioni comprensibili da parte del calcolatore, tramite un **codice oggetto riallocabile** ( **_relocatable object code_** ). In un codice riallocabile gli indirizzi di memoria non sono definiti al momento della compilazione bensı nella fase di esecuzione.70 Di norma, un file oggetto (object) ha estensione *.o , per esempio nomefile.o. ● il collegamento, tramite un collegatore ( linker ) che produce un file eseguibile ( executable file ). In questa fase si predispone tutto per l’assegnazione di indirizzi alle variabili e alle chiamate del programma. Se il programma è costituito da diversi file oggetto, quando si esegue il link del programma, tutti i file oggetto vengono messi
insieme nell’eseguibile. In questa fase si può predisporre anche il collegamento alle librerie ( library ). Le librerie possono essere di due tipi: librerie fornite con il linguaggio di programmazione per agevolare il programmatore permettendogli operazioni gia definite come, ` per esempio, la gestione di dati in ingresso ed in uscita o le operazioni matematiche (elevazione a potenza, radice quadrata, funzioni trigonometriche); oppure librerie fornite da altri programmatori per altre applicazioni, che si vogliono integrare nell’applicazione che si sta sviluppando. Un file di libreria contiene, in forma oggetto, i nomi di ogni funzione e il codice della funzione, oltre che le indicazioni per la riallocazione della memoria. Le librerie sono simili ai file oggetto ma ne differiscono in un aspetto fondamentale: non tutto il codice delle librerie viene aggiunto all’eseguibile del programmatore. Quando nel codice oggetto viene chiamata una funzione di libreria, il linker cerca la funzione nella libreria e aggiunge quella parte di codice al programma. Quindi solo le funzioni effettivamente utilizzate dal programma vengono aggiunte all’eseguibile. Un file eseguibile nel sistema operativo MS-OS ha solitamente estensione *.exe , per esempio nomefile.exe. Mentre nel sistema operativo Linux l’eseguibile ha di solito un nome senza estensione, per esempio nomefile. In entrambi i sistemi operativi gli eseguibili dei compilatori più diffusi possono avere un nome di default, a.out. Se si è superata la fase di compilazione senza errori, in questa fase possono intervenire errori dovuti al fatto che la libreria non è presente sulla macchina su cui si sta effettuando il link, oppure non si trova nelle directory indicate al momento della fase di link. ● il lancio, tramite un caricatore ( loader ). Un programma compilato su di una macchina viene compilato una sola volta ed è eseguibile più volte, ma se si porta il programma su di una macchina con hardware differente e stesso sistema operativo oppure su di una macchina con lo stesso hardware e sistema operativo diverso la compilazione deve essere eseguita di nuovo su quella specifica macchina.