Baixe Foundation HTML5 With CSS3 e outras Notas de estudo em PDF para Informática, somente na Docsity!
For your convenience Apress has placed some of the front
matter material after the index. Please use the Bookmarks
and Contents at a Glance links to access them.
Chapter 1
Getting Started
We’re sure you’re champing at the bit to start building web pages, but we’d like to set the stage first and cover some general information about the Internet and World Wide Web, as well as some background on HTML and CSS. This chapter isn’t a comprehensive overview by any means, but it will get you up to speed on some of the terminology and concepts you’ll need to be familiar with throughout the rest of this book. If you’re already pretty web-savvy, and if you’ve used and worked with websites for some time, feel free to skip ahead to Chapter 2 and start getting your hands dirty.
Introducing the Internet and the World Wide Web
“The Internet” is simply a catchall name for the vast, globe-spanning network of computers that are connected to each other and can transmit and receive data, shuttling information back and forth around the world at nearly the speed of light. It’s been around in some form for nearly half a century now, ever since a few smart people figured out how to make one computer talk to another computer. The Internet has since become so ubiquitous and pervasive, impacting so many aspects of modern life, that it’s hard to imagine a world without it.
The World Wide Web is one facet of the Internet, like a bustling neighborhood in a much larger city (other Internet “neighborhoods” include e-mail, news groups, and chat rooms). The Web is made up of millions of files and documents residing on different computers across the Internet, all interconnected to weave a web of information around the world, which is how it gets its name. In its relatively short history, the Web has
Chapter 1
grown and evolved far beyond the simple text documents it began with, carrying other types of information through the same channels: images, video, audio, and fully immersive interactive experiences. But at its core, the Web is fundamentally a text-based medium, and that text is usually encoded in HTML (more on that in a minute).
Many different devices can access the Web: desktop and laptop computers, tablets and PDAs, mobile phones, game consoles, and even some household appliances. Whatever the device, it in turn operates software that interprets HTML. These programs are technically known as user-agents , but the more familiar term is web browsers. A web browser is specifically a program intended to visually render web documents, whereas some user-agents interpret HTML but don’t display it.
In this book we’ll generally use the word browser to mean any user-agent capable of handling and rendering HTML documents, and we may use the term graphical browser when we’re specifically referring to one that renders the document in a visually enhanced format, in full color, and with styled text and images. It’s important to make this distinction because some web browsers are not graphical and only render plain, unstyled text without any images.
A browser or user-agent is also known as a client , because it is the thing requesting and receiving service. The computer that serves data to the client is called, not surprisingly, a server. The Internet is riddled with servers, all storing and processing data and delivering it in response to client requests. The client and the server are two ends of the chain, connected to each other through the Internet.
What Is HTML?
The World Wide Web originated as a purely textual medium, built upon the written word. Pictures were soon added to the mix, and eventually sound, animation, and video made the Web the rich multimedia tapestry it is today. But the overwhelming bulk of Web content still takes the form of written text, and that’s not likely to change any time soon. Most of the time you spend surfing the Web is probably spent reading.
The Web, for all its multimedia richness, is still essentially a textual medium. It’s a weave of documents, cross-referenced and interconnected by the humble hyperlink , wherein a bit of text in one document is linked directly to another document somewhere else on the Web. And just like that, what would otherwise be ordinary text becomes the much more exciting and dynamic hypertext , and hypertext needs to be encoded in a whole new language: HyperText Markup Language (HTML).
HTML is the computer coding language that describes the structure of a web page. It converts ordinary text into active text for display and use on the Web, and also gives plain, unstructured text the sort of structure human beings rely on to read it. As you read this book, you’re looking for visual cues to help you organize the words into smaller portions that you can process and comprehend. You recognize the significance of things like punctuation, capitalization, spacing, and font sizes. You know just by looking at it that this paragraph ends after this sentence.
Chapter 1
You can learn more about the W3C and read all of their public specifications, past and present, at their website, w3.org. The specifications can be difficult to read because they’re extremely technical in nature, written primarily for computer scientists and software vendors who program web user-agents. But this kind of standardization is essential for the widespread adoption of the Web, ensuring that websites function properly across different browsers and operating systems. The Web is meant to be “platform independent” and “device independent,” and adherence to web standards makes that possible.
The Evolution of HTML
HTML first appeared in 1990—built upon the pre-existing Standard Generalized Markup Language (SGML)—as the foundational language for the newborn World Wide Web, but it wasn’t formally defined until 1993. It was further refined and extended with HTML 2.0, the first official HTML standard, in 1995. Version 3.2 arrived in early 1997 with a slew of new features, and HTML 4.0 came shortly thereafter near the end of the same year.
In those early years of the Web, the language specifications weren’t always followed as closely as they should have been. Different browsers supported different features of HTML, and introduced their own nonstandard features just to get a leg up on the competition. Given the unruly landscape of the time, authors didn’t follow the standards any better than the browsers did. The early web was a tangle of bloated, convoluted markup and proprietary, browser-specific functionality. Developers often resorted to making multiple versions of their sites targeted to different browsers, or even worse, they built websites that worked properly in only one browser and failed utterly in others. Ask an old timer about the Browser Wars of the mid-90s and they’ll regale you with frightening tales of forked scripts, nested tables, and pixel shims. Those were dark days indeed.
Thankfully, this is no longer the case. The web browsers of today follow the standardized specs much more consistently than in previous generations, encouraging authors to do the same, and thus advancing the Web toward the ultimate goal of a truly universal medium.
As the Web really took off in the late 1990s, a few minor (but significant) changes to HTML 4.0 were released in 1999 as HTML 4.01. After a decade of rapid innovation, HTML 4.01 was expected to be the last complete specification of the HTML language. A new kid called XHTML had joined the class, and it was praised as the wave of the future.
The Age of X
Around the turn of the century (way back in the year 2000), the W3C was convinced that the future of the Web lay in eXtensible Markup Language (XML), a powerful language that allows authors to create customized elements rather than relying only on the elements predefined by the language itself. Extensible HTML (XHTML) is a reformulation of HTML following the more stringent syntax of XML. It was meant to bridge the gap between HTML and XML, preparing web authors for this bright XML future everyone expected to arrive any day now.
Getting Started
Whereas XML is extensible, XHTML offers a finite set of predefined elements to choose from—all the same elements that were available in HTML 4.01, in fact. The only real differences between HTML 4. and XHTML 1.0 are stylistic, with just a few more rules dictating how XHTML must be written. HTML is a lax language designed to be tolerant of minor transgressions in syntax, whereas XML is fussy and demands strict adherence to its rules. XHTML simply applies the strictness of XML to HTML, resulting in a hardened set of rules for authoring a document. An XHTML document is essentially just an HTML document written to a more exacting standard.
It was also right around the time XHTML came on the scene that web designers and developers began a serious campaign to improve the state of the Web, encouraging their clients and colleagues to develop in accordance with web standards, and pressuring browser makers to correctly support those same standards in their products. XHTML, with its stricter rules of conformance, was the darling of the web standards movement because it encouraged authors to pay closer attention to how they constructed their documents.
The Web Standards Project (WaSP) was founded in 1998 in reaction to the inconsistent browser behaviors and unsustainable development practices of the era. This group led the charge in what became “the web standards movement,” promoting a new set of best practices for web designers and developers, ultimately changing the way web sites are made and improving the state of the Web, for authors and users alike. WaSP continues to work with web authors, educators, browser vendors, and standards bodies to advance and promote web standards. Their website is webstandards.org.
Meanwhile, the W3C immediately began work on XHTML 2.0. No simple reformulation of existing standards, this was going to be a radical overhaul of the language from the ground up, a whole new approach to authoring documents for the Web. That was over a decade ago. The XHTML 2.0 specification stagnated and eventually stalled, while the Web continued to move inexorably forward, innovating on top of a foundation that was beginning to show its age. By the mid-2000s it became clear to some that XHTML 2.0 was perhaps not the best way forward after all, and it was time to re-examine and refresh good old HTML.
Out with the X, in with the 5
A splinter group formed within the W3C in 2004 and began to craft new addendums to HTML. They called themselves the Web Hypertext Application Technology Working Group (WHATWG, whatwg.org ) and their side projects were dubbed Web Apps 1.0 and Web Forms 2.0, both meant to be extensions of the stale HTML 4.01 spec. Eventually these two projects were united in a new fledgling specification: HTML5.
In due time the W3C also came to accept that XHTML 2.0 wasn’t working out as planned, and recognized that this new HTML5 business was something worth paying attention to. The W3C started the process of adopting and formalizing the work produced by WHATWG. And so HTML5 gained official status as the next HTML standard.
Getting Started
elements. All the useful elements from previous versions of HTML have been kept, but HTML5 eliminates some legacy elements that have outlived their usefulness. You’ll learn all about the elements of HTML5, both old and new, in detail throughout the rest of this book.
Also new in HTML5 are elements for embedding rich media in documents. Images have been on the Web almost from the beginning, but for years authors had to rely on third-party plug-in applications—such as Adobe’s Flash or Apple’s QuickTime—to play sound and video over the Web. HTML5 makes it possible to play sound and video natively in the browser, without plug-ins. HTML5 also brings the canvas element, an area in a document where scripts and programs can draw live graphics. You’ll learn more about embedding media in Chapter 5.
After all our “the Web is made of documents” talk, we shouldn’t gloss over the prevalence of web applications. A web application might be similar to other computer applications you’re familiar with—like an e-mail program, a word processor, or the spreadsheet shown in Figure 1-1—but it works directly in a web browser. Under the surface, a great many web apps are actually nothing more than enhanced documents, using sophisticated code to manipulate HTML right before your eyes, yet still built on that same HTML foundation. HTML5 is being written with web apps in mind, offering new abilities and frameworks to enhance the applications built on top of it.
Figure 1-1. A Google Docs spreadsheet offers most of the features of a desktop spreadsheet application like Microsoft Excel, but runs within a web browser and stores its data online. This web app is built entirely with HTML, CSS, and JavaScript.
Chapter 1
Alongside HTML5 and its regular content-structuring markup duties, a number of related scripting APIs (Application Programming Interfaces) are being developed and standardized to help web apps work with HTML5 content. For example, with HTML5-empowered web apps, you’ll be able to store application data offline, edit web documents directly in the browser, use a web app to work with files stored on your computer, send messages between web documents, share your location, and more. But don’t get too excited just yet; we won’t be covering these scripting APIs in any detail in this book. They’re related to HTML5, and are often grouped under the HTML5 umbrella, but they are not necessarily HTML5. As far as we’re concerned right now—and for the rest of this book—HTML5 is still just a language to mark up documents for the Web.
Separating Content from Presentation
HTML is intended to bestow a meaningful structure upon unstructured text, showing that different blocks of words are in fact different types of content. A headline is not the same as a paragraph; those two types of content should be marked up with different tags, making their innate difference absolutely clear to another computer. But human beings don’t want to read encoded tags. We’re used to reading text that looks a certain way—we expect headlines to appear in a large, boldfaced font to let us know that it’s a headline and not something else. Early browser developers knew this, and they programmed their software to display different types of content in different styles.
From its humble roots, the Web quickly blossomed and soon was no longer the exclusive domain of academics and computer scientists. Graphic designers discovered this exciting new medium and sought ways to make it more aesthetically appealing than ordinary, unadorned text. However, HTML lacked a proper means of influencing the display of content; it was strictly intended to provide structure, with only a few conceits to graphic design. Designers were forced to repurpose existing features of HTML, taking advantage of the way browsers displayed content in an effort to create something more visually compelling. Unfortunately, this resulted in many websites of the day being built with presentational markup that was messy, overcomplicated, hard to maintain, and had nothing to do with what the content meant but only how it should look.
In 1996, when the Web was still in its infancy, the W3C introduced Cascading Style Sheets (CSS). It was an entirely different language, one specifically created to describe how HTML documents should be visually presented while leaving the structural markup clean and meaningful. A style sheet written in CSS can be applied to an HTML document, adding an attractive layer of design without negatively impacting the markup that serves as its foundation. The code that gives the content its structure is kept separate from the code describing its presentation.
Separating content from presentation allows both aspects to become stronger and more adaptable. An HTML document can be changed without completely reconstructing it to correct the design. An entire website can be redesigned by changing a single style sheet without rewriting one line of structural markup.
Chapter 1
alongside the web standards, and the browser makers are directly involved in defining the very standards they follow. Quite simply, as soon as a browser—or a few browsers, hopefully—supports a given feature, that’s when you can use it.
You can get up-to-date information on which browsers support which new features in HTML5 and CSS3 as well as some of the new JavaScript APIs at Can I Use ( caniuse.com ) and at HTML5 Please ( html5please.com ).
It probably goes without saying that only newer web browsers support the newer features of HTML and CSS; older browsers couldn’t support what didn’t exist. However, not every web surfer out there is using the very latest browser, and even among the latest versions, not every current browser supports every new feature equally. Even so, you can still employ some of the more advanced features of HTML5 and CSS3 without shutting out less capable browsers and devices by following progressive enhancement.
Progressive enhancement isn’t a specific technique; it’s a general methodology, a particular approach to making websites that applies more advanced web technologies in a layered fashion. You’ll begin with pure content and basic structure, then enhance that with additional layers of meaning, presentation, and behavior in such a way that browsers and devices that support those enhancements can benefit from them, but those that don’t support the enhancements can still access the original content.
Web browsers are pretty easy-going when it comes to parsing HTML and CSS. When a browser encounters some piece of markup or styling it doesn’t support, rather than lock up and refuse to proceed, the browser will simply ignore that unsupported code and continue on its merry way. The directive to ignore unsupported code is baked right into the web standards. The browsers’ built-in fault tolerance is what makes progressive enhancement possible; they’ll just skip over any code they don’t understand and get on with rendering the code they already know.
With progressive enhancement, you can add bells and whistles from HTML5 and CSS3 without destroying the nutritious kernel of content underneath. The real key to a progressive enhancement methodology is to avoid making your websites completely dependent on a specific bell or whistle. Start simple and add layers of complexity in such a way that each subsequent layer is an optional enhancement on top of the layer that supports it.
First give your content a solid and stable structure with simple HTML that every web-capable device will have no trouble processing. Enhance that basic structure with some of the more cutting edge parts of HTML5 and browsers that don’t support the newer features will still have the basic structure to fall back on. Use simple, well-supported CSS to further enhance your content and make it more presentable. Add in some of the newer techniques from CSS3—the ones that only the latest browsers support—and older browsers will still render the simpler, time-tested styling (and any devices that don’t even support the simple styling will still fall back to the unadorned HTML). Enhance that styled content even further with layers of behavior and interaction using JavaScript, and devices that don’t support the scripting will still render readable, accessible, styled content.
Getting Started
Unlike HTML and CSS, JavaScript is not a fault tolerant language. Any unsupported methods or functions that appear in your JavaScript—even a simple syntax mistake— will generate an error and bring the script to a screeching halt. Every part of a script needs to be in working order or else the entire thing can fall apart. However, you can incorporate checks and failsafes into your JavaScript to detect whether the browser supports a given feature, and to fail gracefully if it doesn’t. JavaScript is another important layer in the progressive enhancement stack, but that’s a subject for another book.
At every stage and with every new layer of enhancement you add, think about how the content will degrade if and when that layer is stripped away. If removing a layer would make the content nonfunctional or unusable, then perhaps you need to revise your strategy.
Working with HTML and CSS
Though HTML and CSS can seem overwhelming when you first dive in, creating your own web pages is actually quite easy once you get the hang of it. All you really need is a way to edit text files, a browser to view them in, and a place to store the files you create.
Choosing an Editor
HTML documents are plain text, devoid of any special formatting or style—all of the visual formatting happens when a graphical web browser renders the document. To create and edit plain-text electronic documents, you’ll need to use software that can do so without automatically imposing any formatting of its own. Fortunately, every operating system comes with some kind of simple text-editing program:
Windows users can use Notepad, which you will find under Start All Programs Accessories Notepad. WordPad is another Windows alternative, but it will format documents by default. If you use WordPad, be sure to edit and save your documents as plain text, not “rich text.”
Linux users can choose from several text editors, such as vi, vim, or emacs.
Mac users can use TextEdit, which ships natively with OS X in the Applications folder. Like WordPad for Windows, TextEdit defaults to a rich-text format. You can change this by selecting Format Make Plain Text.
In addition to these basic text editors, more advanced, specialized text editors are available for Windows, Linux, and Macintosh systems, many specially designed for editing web documents. Some of them are even available free of charge. There are also so-called What You See Is What You Get (WYSIWYG, pronounced as “wizzy wig”) editors on the market that offer a graphical interface wherein you can edit documents in their formatted, rendered state while the software automatically produces the markup behind
Getting Started
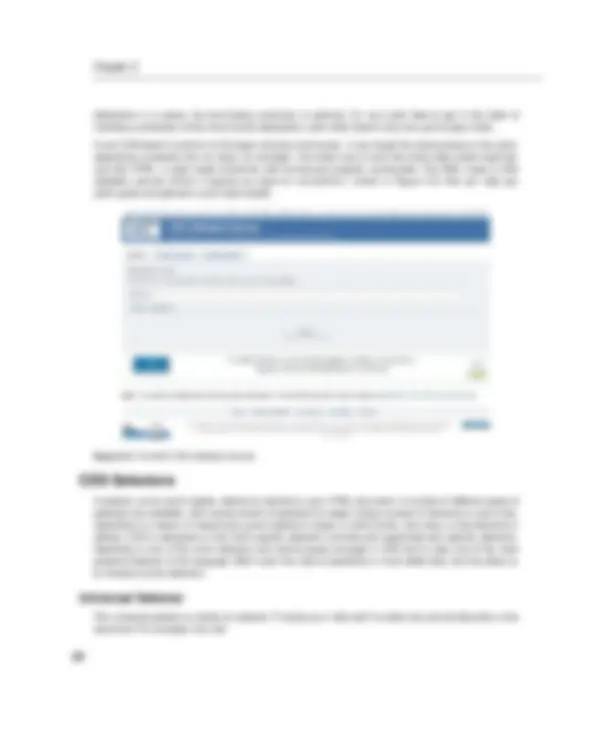
Figure 1-2. The W3C Markup Validation Service
The W3C validator can automatically analyze your markup and display any errors it encounters so you can correct them. It will also display validation warnings , which are simply cautions about issues you might want to address but are not quite as severe as errors; warnings can be ignored if you have good reason to do so, but errors are flaws that really must be fixed. When no errors are found, you’ll see a joyful banner declaring that your document is valid. A document that is valid and correctly assembled according to the rules of the language is said to be well-formed. Other validation tools are also available—both online and offline—that can help you check your documents.
CSS also needs to be authored in accordance with the specifications, and the W3C offers a similar CSS validation service ( http://jigsaw.w3.org/css-validator/ ) to check your CSS files for problems.
Most web browsers are still able to interpret and render invalid documents, but only because they’ve been designed to compensate for minor errors. Valid, well-formed documents are much more stable, and you won’t have to depend on a browser’s built-in error handling to display them correctly.
Chapter 1
Hosting Your Web Site
You can save all of your work locally on your own computer, but when it’s time to make it available to the World Wide Web, you need to move those files to a web server. You have a few hosting options if you’re building your own website:
Using web space provided by your ISP: An Internet service provider (ISP) is the company that connects you to the Internet. Many service providers offer a limited amount of web space where you can host your own site. Ask your ISP whether web space is included with your service contract and how you can use it.
Using free web space: Many companies provide free web hosting, though “free” is a relative term because free web hosts are usually supplemented by advertising. If you’re not bothered by such ads appearing on your website, free hosting may be a quick solution to getting your files online.
Paying for web hosting: Perhaps the best option is to purchase service from a company that specializes in hosting websites. Many offer hosting packages for as little as $10 (US) per month and include more robust features than free hosting or ISP hosting provides (such as e-mail service, server-side scripting, and databases). Research your options, and choose a host that can meet your needs.
If you opt for paid web hosting, you’ll also need to purchase and register a unique domain name to be your site’s address on the Web. Some hosting companies offer domain registration as an included service (and some domain registrars also offer hosting services), but securing a domain and securing a host are usually two separate processes.
We won’t go into all the particulars of registering a domain and getting your site online with a web host. After all, this is still the first chapter, and numerous resources online can provide more information. To learn more about hosting your websites when the time comes, just visit your favorite search engine and have a look around for information about “web hosting basics” or some similar phrase. One good place to start is the Wikipedia entry about web hosting service ( http://en.wikipedia.org/wiki/Web_hosting ), which offers a fairly detailed introduction to set you on your way.
Introducing the URL
Every file or document available on the Web resides at a unique address called a Uniform Resource Locator (URL). The term Uniform Resource Identifier (URI) is sometimes used interchangeably with URL, though URI is a more general term; a URL is a type of URI. We’ll be using the term URL in this book to discuss addressed file locations. It’s this address that allows a web-connected device to locate a specific file on a specific server in order to download and display it to the user (or employ it for some other purpose; not all files on the Web are meant to be displayed).
Chapter 1
servers are configured to recognize these extensions and handle the files appropriately, processing different types of files in different ways.
You won’t see a file name and extension in every URL you encounter. Most web servers are configured to automatically locate a specially named file when a directory is requested without a specified file name. This could be the file called index.html, default.html , or some other name, depending on the way the server has been set up. Indeed, most of the various parts of the URL may be optional depending on the particular server configuration.
The URL is the instrument that allows you to build links to other parts of the Web, including other parts of your own site. You’ll use URLs extensively in the HTML and CSS you author, which is why we’ve spent so much time exploring them in this first chapter.
Absolute and Relative URLs
A URL can take either of two forms when it points to a resource elsewhere within the same site. An absolute URL is one that includes the full string, including the protocol and hostname, leaving no question as to where that resource is found on the Web. You’ll use an absolute URL when you link to a site or file outside your own site’s domain, though internal URLs can also be absolute.
A relative URL is one that points to a resource within the same site by referencing only the path and/or file, omitting the protocol and hostname because those can be safely assumed. It might look something like this:
examples/chapter1/example.html
If the destination file is kept within the same directory as the file where the URL occurs, the path can be assumed as well so only the file name and extension are required, like so:
example.html
If the destination is in a directory above the source file, you can indicate that relative path with two dots and a slash ( ../ ), instructing the browser to go up one level to find the resource. Each occurrence of ../ indicates one up-level directive, so a URL pointing two directories upwards might look like this:
../../example.html
Almost all web servers are configured to interpret a leading slash in a relative URL as the site root directory, so URLs can be “site root relative,” showing the full path from the site root down:
/examples/chapter1/example.html
Lastly, if the destination is a directory rather than a specific file, only the path is needed:
/examples/chapter1/
Getting Started
Relative URLs are a useful way to keep file references short and portable; an entire site can be moved to another domain and all of its relative URLs will remain intact and functional.
Summary
This chapter has provided a high-level overview of what the Internet and World Wide Web are and how they work. You’ve been introduced to HTML and CSS and are beginning to understand how you can make these languages work together to produce a rendered web page. You got a short history lesson on how HTML and CSS have changed over time, and some inkling of what the future holds for these fundamental web languages. We mentioned a few different text editors you can use to create your documents and some popular web browsers with which to view them. You’ve also learned a little about web hosting and a lot about the components of a URL, information you’ll find essential as you begin assembling your own websites. We haven’t gone into all the gory details in this introduction—after all, we’ve got the rest of the book to cover them. In Chapter 2 you’ll finally get to sink your teeth into some real HTML and CSS. Buckle up; this should be a fun ride!