


Zachary Radtka
& Donald Miner
Hadoop
with Python







































Estude fácil! Tem muito documento disponível na Docsity

Ganhe pontos ajudando outros esrudantes ou compre um plano Premium

Prepare-se para as provas
Estude fácil! Tem muito documento disponível na Docsity
Prepare-se para as provas com trabalhos de outros alunos como você, aqui na Docsity
Encontra documentos específicos para os exames da tua universidade
Prepare-se com as videoaulas e exercícios resolvidos criados a partir da grade da sua Universidade
Responda perguntas de provas passadas e avalie sua preparação.
Ganhe pontos para baixar
Ganhe pontos ajudando outros esrudantes ou compre um plano Premium
hadoop - with - python
Tipologia: Notas de estudo
1 / 71

Esta página não é visível na pré-visualização
Não perca as partes importantes!
978-1-491-94227-
[LSI]
Hadoop with Python by Zachary Radtka and Donald Miner
Copyright © 2016 O’Reilly Media, Inc.. All rights reserved.
Printed in the United States of America.
Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA
O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or [email protected].
Editor: Meghan Blanchette Production Editor: Kristen Brown Copyeditor: Sonia Saruba
Interior Designer: David Futato Cover Designer: Karen Montgomery Illustrator: Rebecca Demarest
October 2015: First Edition
Revision History for the First Edition 2015-10-19 First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781491942277 for release details.
While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is sub‐ ject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
Source Code
All of the source code in this book is on GitHub. To copy the source code locally, use the following git clone command:
$ git clone https://github.com/MinerKasch/HadoopWithPython
vii
Overview of HDFS
The architectural design of HDFS is composed of two processes: a process known as the NameNode holds the metadata for the filesys‐ tem, and one or more DataNode processes store the blocks that make up the files. The NameNode and DataNode processes can run on a single machine, but HDFS clusters commonly consist of a dedi‐ cated server running the NameNode process and possibly thousands of machines running the DataNode process.
The NameNode is the most important machine in HDFS. It stores metadata for the entire filesystem: filenames, file permissions, and the location of each block of each file. To allow fast access to this information, the NameNode stores the entire metadata structure in memory. The NameNode also tracks the replication factor of blocks, ensuring that machine failures do not result in data loss. Because the NameNode is a single point of failure, a secondary NameNode can be used to generate snapshots of the primary NameNode’s memory structures, thereby reducing the risk of data loss if the NameNode fails.
The machines that store the blocks within HDFS are referred to as DataNodes. DataNodes are typically commodity machines with large storage capacities. Unlike the NameNode, HDFS will continue to operate normally if a DataNode fails. When a DataNode fails, the NameNode will replicate the lost blocks to ensure each block meets the minimum replication factor.
The example in Figure 1-1 illustrates the mapping of files to blocks in the NameNode, and the storage of blocks and their replicas within the DataNodes.
The following section describes how to interact with HDFS using the built-in commands.
2 | Chapter 1: Hadoop Distributed File System (HDFS)
Figure 1-1. An HDFS cluster with a replication factor of two; the NameNode contains the mapping of files to blocks, and the DataNodes store the blocks and their replicas
Interacting with HDFS
Interacting with HDFS is primarily performed from the command line using the script named hdfs. The hdfs script has the following usage:
$ hdfs COMMAND [-option
The COMMAND argument instructs which functionality of HDFS will be used. The -option argument is the name of a specific option for the specified command, and
To perform basic file manipulation operations on HDFS, use the dfs command with the hdfs script. The dfs command supports many of the same file operations found in the Linux shell.
It is important to note that the hdfs command runs with the per‐ missions of the system user running the command. The following examples are run from a user named “hduser.”
To list the contents of a directory in HDFS, use the -ls command:
$ hdfs dfs -ls $
Interacting with HDFS | 3
After a directory has been created for the current user, data can be uploaded to the user’s HDFS home directory with the -put com‐ mand:
$ hdfs dfs -put /home/hduser/input.txt /user/hduser
This command copies the file /home/hduser/input.txt from the local filesystem to /user/hduser/input.txt on HDFS.
Use the -ls command to verify that input.txt was moved to HDFS:
$ hdfs dfs -ls Found 1 items -rw-r--r-- 1 hduser supergroup 52 2015-09-20 13: input.txt
Multiple commands allow data to be retrieved from HDFS. To sim‐ ply view the contents of a file, use the -cat command. -cat reads a file on HDFS and displays its contents to stdout. The following com‐ mand uses -cat to display the contents of /user/hduser/input.txt:
$ hdfs dfs -cat input.txt jack be nimble jack be quick jack jumped over the candlestick
Data can also be copied from HDFS to the local filesystem using the -get command. The -get command is the opposite of the -put command:
$ hdfs dfs -get input.txt /home/hduser
This command copies input.txt from /user/hduser on HDFS to /home/hduser on the local filesystem.
The commands demonstrated in this section are the basic file opera‐ tions needed to begin using HDFS. Below is a full listing of file manipulation commands possible with hdfs dfs. This listing can also be displayed from the command line by specifying hdfs dfs without any arguments. To get help with a specific option, use either hdfs dfs -usage
Interacting with HDFS | 5
Usage: hadoop fs [generic options] [-appendToFile
Generic options supported are -conf
6 | Chapter 1: Hadoop Distributed File System (HDFS)
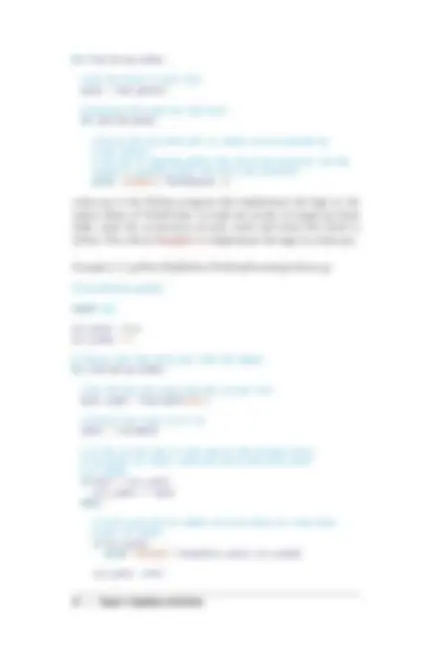
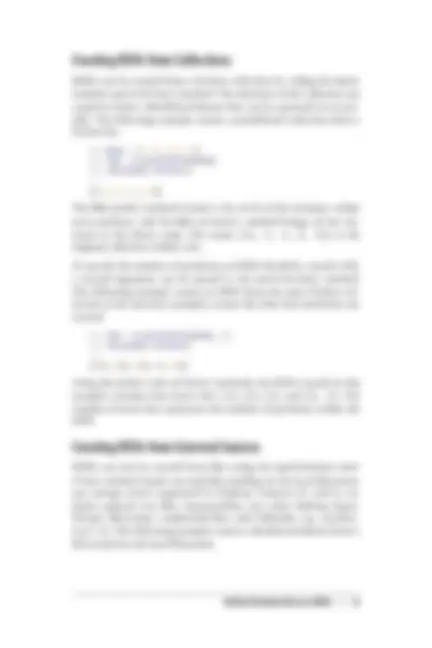
Example 1-1. python/HDFS/list_directory.py
from snakebite.client import Client
client = Client('localhost', 9000) for x in client.ls(['/']): print x
The most important line of this program, and every program that uses the client library, is the line that creates a client connection to the HDFS NameNode:
client = Client('localhost', 9000)
The Client() method accepts the following parameters:
host ( string ) Hostname or IP address of the NameNode
port ( int ) RPC port of the NameNode
hadoop_version ( int ) The Hadoop protocol version to be used (default: 9)
use_trash ( boolean ) Use trash when removing files
effective_use ( string ) Effective user for the HDFS operations (default: None or cur‐ rent user)
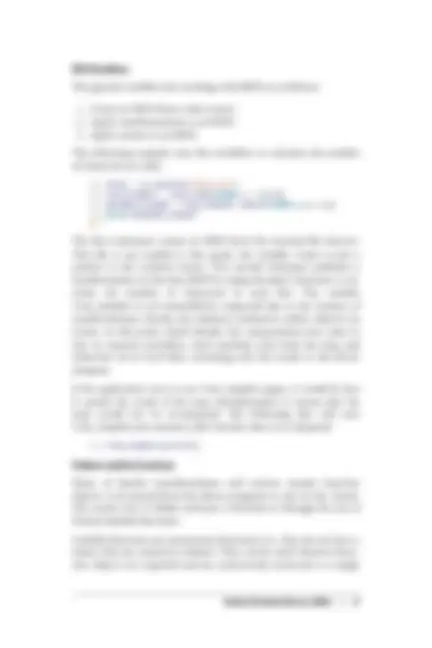
The host and port parameters are required and their values are dependent upon the HDFS configuration. The values for these parameters can be found in the hadoop/conf/core-site.xml configura‐ tion file under the property fs.defaultFS:
For the examples in this section, the values used for host and port are localhost and 9000 , respectively.
After the client connection is created, the HDFS filesystem can be accessed. The remainder of the previous application used the ls command to list the contents of the root directory in HDFS:
8 | Chapter 1: Hadoop Distributed File System (HDFS)
for x in client.ls(['/']): print x
It is important to note that many of methods in Snakebite return generators. Therefore they must be consumed to execute. The ls method takes a list of paths and returns a list of maps that contain the file information.
Executing the list_directory.py application yields the following results:
$ python list_directory.py {'group': u'supergroup', 'permission': 448, 'file_type': 'd', 'access_time': 0L, 'block_replication': 0, 'modifica- tion_time': 1442752574936L, 'length': 0L, 'blocksize': 0L, 'owner': u'hduser', 'path': '/tmp'} {'group': u'supergroup', 'permission': 493, 'file_type': 'd', 'access_time': 0L, 'block_replication': 0, 'modifica- tion_time': 1442742056276L, 'length': 0L, 'blocksize': 0L, 'owner': u'hduser', 'path': '/user'}
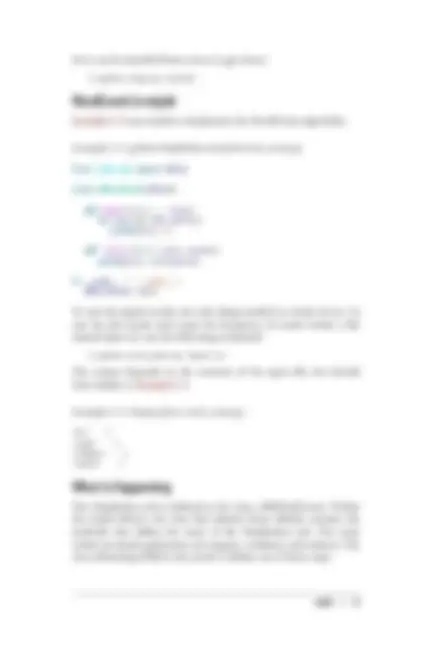
Use the mkdir() method to create directories on HDFS. Example 1-2 creates the directories /foo/bar and /input on HDFS.
Example 1-2. python/HDFS/mkdir.py
from snakebite.client import Client
client = Client('localhost', 9000) for p in client.mkdir(['/foo/bar', '/input'], create_parent=True): print p
Executing the mkdir.py application produces the following results:
$ python mkdir.py {'path': '/foo/bar', 'result': True} {'path': '/input', 'result': True}
The mkdir() method takes a list of paths and creates the specified paths in HDFS. This example used the create_parent parameter to ensure that parent directories were created if they did not already exist. Setting create_parent to True is analogous to the mkdir -p Unix command.
Snakebite | 9
$ python copy_to_local.py {'path': '/tmp/input.txt', 'source_path': '/input/input.txt', 'result': True, 'error': ''}
To simply read the contents of a file that resides on HDFS, the text() method can be used. Example 1-5 displays the content of /input/input.txt.
Example 1-5. python/HDFS/text.py
from snakebite.client import Client
client = Client('localhost', 9000) for l in client.text(['/input/input.txt']): print l
Executing the text.py application produces the following results:
$ python text.py jack be nimble jack be quick jack jumped over the candlestick
The text() method will automatically uncompress and display gzip and bzip2 files.
The CLI client included with Snakebite is a Python command-line HDFS client based on the client library. To execute the Snakebite CLI, the hostname or IP address of the NameNode and RPC port of the NameNode must be specified. While there are many ways to specify these values, the easiest is to create a ~.snakebiterc configura‐ tion file. Example 1-6 contains a sample config with the NameNode hostname of localhost and RPC port of 9000.
Example 1-6. ~/.snakebiterc
{ "config_version" : 2, "skiptrash" : true , "namenodes" : [ { "host" : "localhost", "port" : 9000, "version" : 9}, ] }
Snakebite | 11
The values for host and port can be found in the hadoop/conf/core- site.xml configuration file under the property fs.defaultFS.
For more information on configuring the CLI, see the Snakebite CLI documentation online.
To use the Snakebite CLI client from the command line, simply use the command snakebite. Use the ls option to display the contents of a directory:
$ snakebite ls / Found 2 items drwx------ - hadoop supergroup 0 2015-09-20 14:36 /tmp drwxr-xr-x - hadoop supergroup 0 2015-09-20 11:40 /user
Like the hdfs dfs command, the CLI client supports many familiar file manipulation commands (e.g., ls, mkdir, df, du, etc.).
The major difference between snakebite and hdfs dfs is that snakebite is a pure Python client and does not need to load any Java libraries to communicate with HDFS. This results in quicker interactions with HDFS from the command line.
The following is a full listing of file manipulation commands possi‐ ble with the snakebite CLI client. This listing can be displayed from the command line by specifying snakebite without any arguments. To view help with a specific command, use snakebite [cmd] -- help, where cmd is a valid snakebite command.
snakebite [general options] cmd [arguments] general options: -D --debug Show debug information -V --version Hadoop protocol version (default:9) -h --help show help -j --json JSON output -n --namenode namenode host -p --port namenode RPC port (default: 8020) -v --ver Display snakebite version
commands: cat [paths] copy source paths to stdout chgrp
12 | Chapter 1: Hadoop Distributed File System (HDFS)