



Computer Organization
Lecture 2
Review of MIPS ISA and Performance
Docsity.com









































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A lecture note from docsity.com covering the instruction set architecture (isa) and performance of mips. It includes details on instruction sets, isa classes, general purpose registers, mips i registers, memory addressing, addressing modes, instruction formats, and administrative matters.
Typology: Slides
1 / 51

This page cannot be seen from the preview
Don't miss anything!
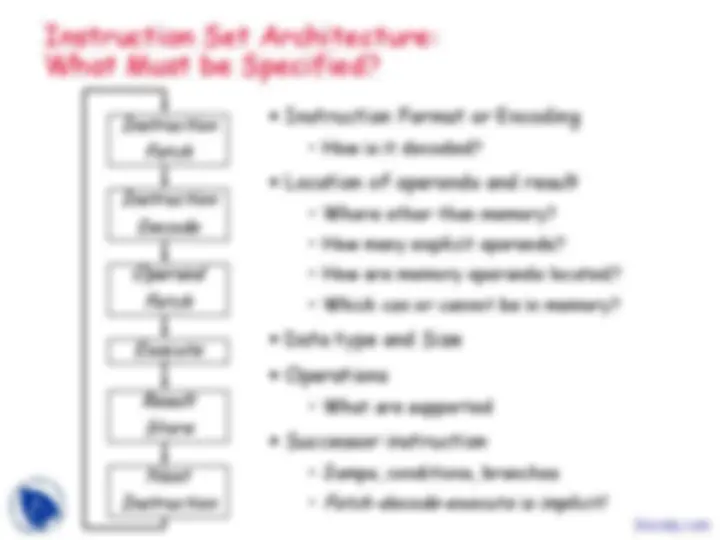
Instruction Format or Encoding
Location of operands and result
Data type and Size
Operations
Successor instruction
Accumulator (1 register):
1 address add A acc acc + mem[A]
1+x address addx A acc acc + mem[A + x]
Stack:
0 address add tos tos + next
General Purpose Register (can be memory/memory):
2 address add A B EA[A] EA[A] + EA[B]
3 address add A B C EA[A] EA[B] + EA[C]
Load/Store:
3 address add Ra Rb Rc Ra Rb + Rc
load Ra Rb Ra mem[Rb]
store Ra Rb mem[Rb] Ra
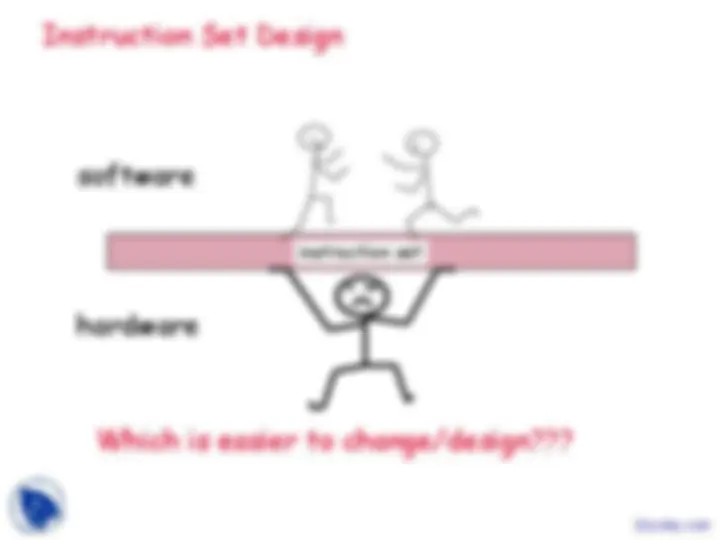
Comparison: Bytes per instruction? Number of Instructions? Cycles per instruction?
Most real machines are hybrids of these:
r0^0 r ° ° ° r PC lo hi
msb lsb
Alignment: require that objects fall on address
that is multiple of their size.
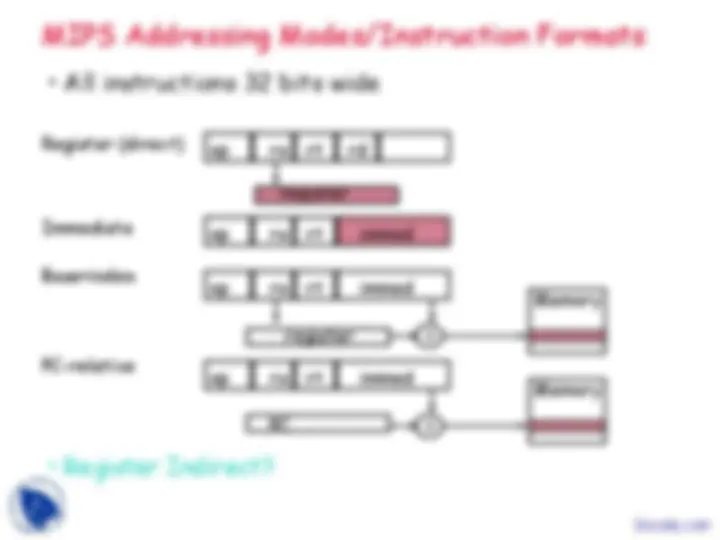
Addressing mode Example Meaning
Register Add R4,R3 R4 R4+R
Immediate Add R4,#3 R4 R4+
Displacement Add R4,100(R1) R4 R4+Mem[100+R1]
Register indirect Add R4,(R1) R4 R4+Mem[R1]
Indexed / Base Add R3,(R1+R2) R3 R3+Mem[R1+R2]
Direct or absolute Add R1,(1001) R1 R1+Mem[1001]
Memory indirect Add R1,@(R3) R1 R1+Mem[Mem[R3]]
Post-increment Add R1,(R2)+ R1 R1+Mem[R2]; R2 R2+d
Pre-decrement Add R1,–(R2) R2 R2–d; R1 R1+Mem[R2]
Scaled Add R1,100(R2)[R3] R1 R1+Mem[100+R2+R3*d]
Docsity.com
° Avg. of 5 SPECint92 programs v. avg. 5 SPECfp92 programs
° 1% of addresses > 16-bits
° 12 - 16 bits of displacement needed
Int. Av g. FP Av g.
op rs rt rd
immed
register
Register (direct)
op rs rt
register
Base+index
Memory
Immediate op rs rt immed
op rs rt immed
PC-relative
Memory