Download DRAM: Architecture, Interfaces and Systems - Slides | ECE 4100 and more Study notes Computer Architecture and Organization in PDF only on Docsity!
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
DRAM: why bother? (i mean, besides the “memory wall” thing? ... is it just a performance issue?)
think about embedded systems: think cellphones, think printers, think switches ... nearly every embedded product that used to be expensive is now cheap. why? for one thing, rapid turnover from high performance to obsolescence guarantees generous supply of CHEAP, HIGH-PERFORMANCE embedded processors to suit nearly any design need.
what does the “memory wall” mean in this context? perhaps it will take longer for a high- performance design to become obsolete?
DRAM: Architectures,
Interfaces, and Systems
A Tutorial
Bruce Jacob and David Wang
Electrical & Computer Engineering Dept.
University of Maryland at College Park
http://www.ece.umd.edu/~blj/DRAM/
UNIVERSITY OF MARYLAND
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
NOTE
Outline
- Basics
- DRAM Evolution: Structural Path
- Advanced Basics
- DRAM Evolution: Interface Path
- Future Interface Trends & Research Areas
- Performance Modeling:
Architectures, Systems, Embedded
Break at 10 a.m. — Stop us or starve
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
first off -- what is DRAM? an array of storage elements (capacitor-transistor pairs)
“DRAM” is an acronym (explain) why “dynamic”?
- capacitors are not perfect ... need recharging
- very dense parts; very small; capactiros have very little charge ... thus, the bit lines are charged up to 1/2 voltage level and the ssense amps detect the minute change on the lines, then recover the full signal
Basics
DRAM ORGANIZATION
... Bit Lines...
Memory
Array
Row Decoder
. .. Word Lines ...
DRAM
Storage element
Switching
element
Bit Line
Word Line (^) Data In/Out
Buffers
Sense Amps
Column Decoder
(capacitor)
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
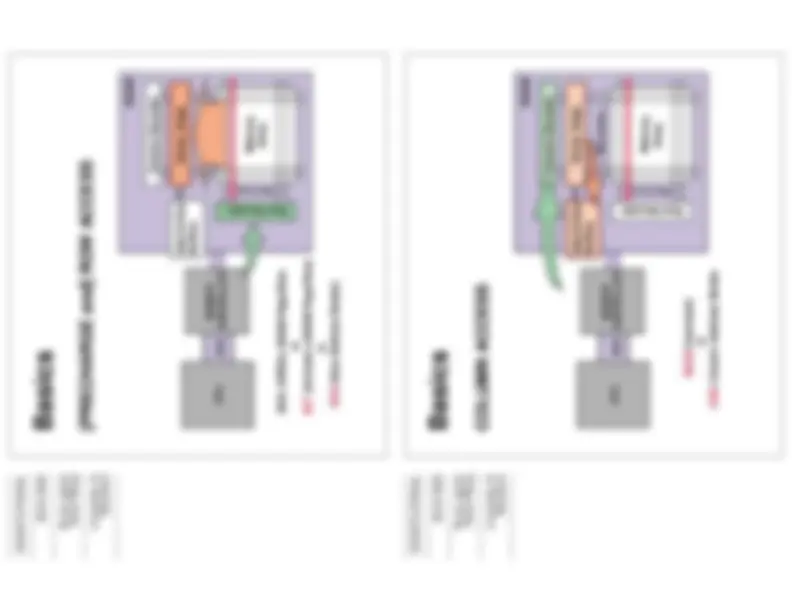
so how do you interact with this thing? let’s look at a traditional organization first ... CPU connects to a memory controller that connects to the DRAM itself.
let’s look at a read operation
Basics
BUS TRANSMISSION
BUS
MEMORY
CPU CONTROLLER
... Bit Lines...
Memory
Array
Row Decoder
. .. Word Lines ...
DRAM
Data In/Out
Buffers
Sense Amps
Column Decoder
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
then the data is valid on the data bus ... depending on what you are using for in/out buffers, you might be able to overlap a litttle or a lot of the data transfer with the next CAS to the same page (this is PAGE MODE)
Basics
DATA TRANSFER
note: page mode enables overlap with CAS
BUS
MEMORY
CPU CONTROLLER
... Bit Lines...
Memory
Array
Row Decoder
. .. Word Lines ...
DRAM
Data In/Out
Buffers
Sense Amps
Column Decoder
... with optional additional
CAS: Column Address Strobe
Data Out
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
NOTE
Basics
BUS TRANSMISSION
BUS
MEMORY
CPU CONTROLLER
... Bit Lines...
Memory
Array
Row Decoder
. .. Word Lines ...
DRAM
Data In/Out
Buffers
Sense Amps
Column Decoder
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
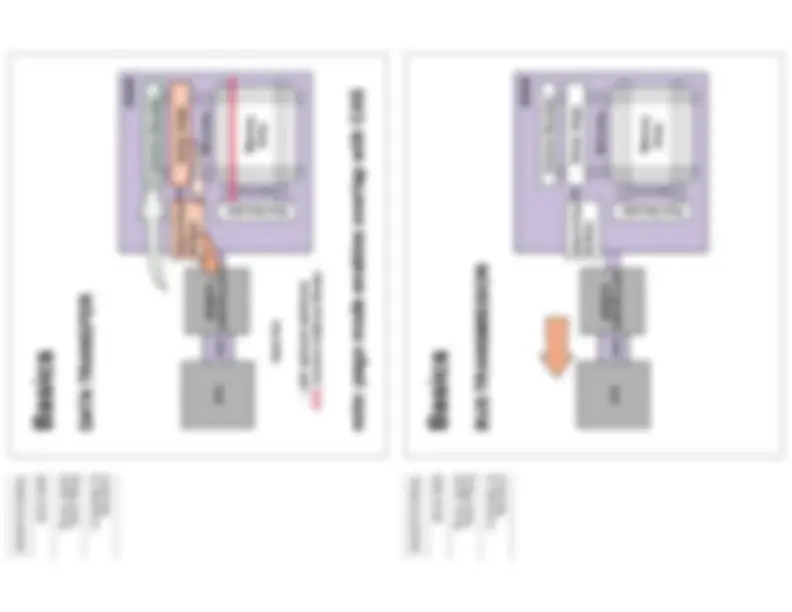
DRAM “latency” isn’t deterministic because of CAS or RAS+CAS, and there may be significant queuing delays within the CPU and the memory controller Each transaction has some overhead. Some types of overhead cannot be pipelined. This means that in general, longer bursts are more efficient.
Basics
B
C
D
DRAM
E 2 /E 3
E 1
F
A
CPU (^) Mem
Controller
A: Transaction request may be delayed in Queue
B: Transaction request sent to Memory Controller
C: Transaction converted to Command Sequences
(may be queued)
D: Command/s Sent to DRAM
E
: Requires only a CAS or
E 2 : Requires RAS + CAS or
F: Transaction sent back to CPU
“DRAM Latency” = A + B + C + D + E + F
E3: Requires PRE + RAS + CAS
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
NOTE
Basics
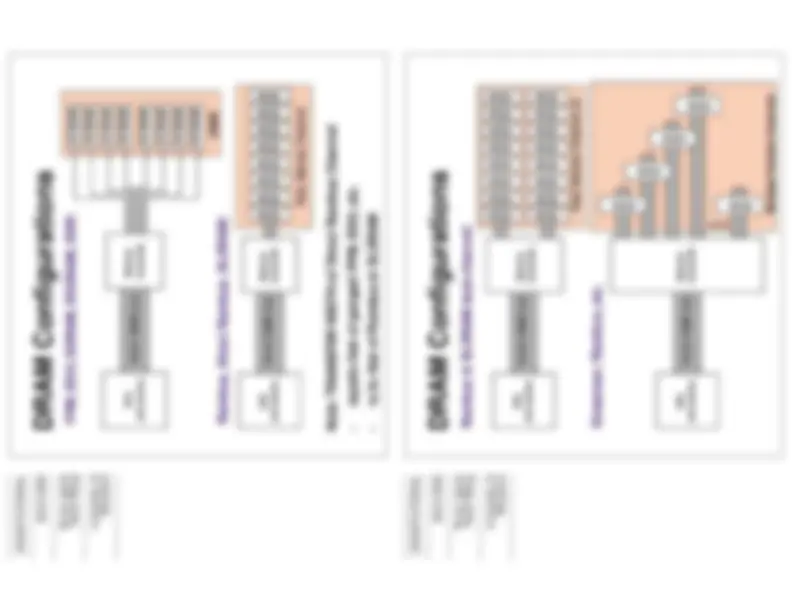
PHYSICAL ORGANIZATION
This is per bank …
Typical DRAMs have 2+ banks
x2 DRAM x4 DRAM x8 DRAM
... Bit Lines...
Sense Amps
Data Buffers
x8 DRAM
Row Decoder
Memory Array
Column Decoder
... Bit Lines...
Sense Amps
Data Buffers
x2 DRAM
Row Decoder
Memory Array
Column Decoder
... Bit Lines...
Sense Amps
Data Buffers
x4 DRAM
Row Decoder
Memory Array
Column Decoder
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
NOTE
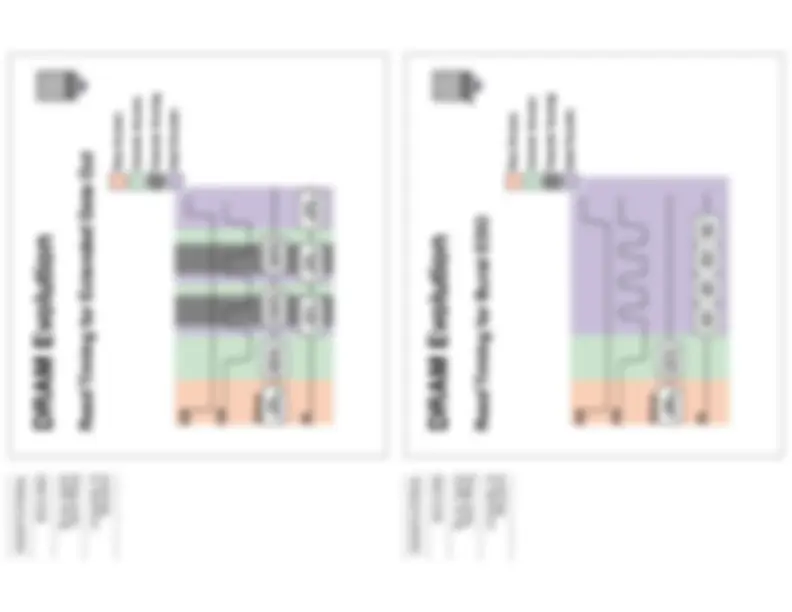
DRAM Evolution
Read Timing for Conventional DRAM
Row
Address
Column
Address
Valid
Dataout
RAS
CAS
Address
DQ
Row
Address
Column
Address
Valid
Dataout
Data Transfer
Column Access
Transfer Overlap
Row Access
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
FPM aallows you to keep th esense amps actuve for multiple CAS commands ...
much better throughput
problem: cannot latch a new value in the column address buffer until the read-out of the data is complete
DRAM Evolution
Read Timing for Fast Page Mode
Row
Address
Column
Address
Valid
Dataout
Column
Address
Column
Address
Valid
Dataout
Valid
Dataout
RAS
CAS
Address
DQ
Data Transfer
Column Access
Transfer Overlap
Row Access
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
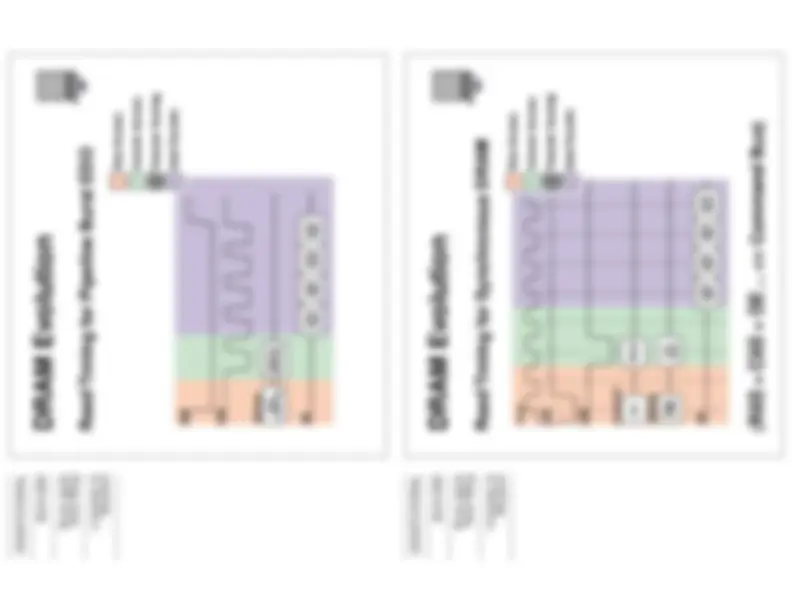
solution to that problem -- instead of simple tri-state buffers, use a latch as well.
by putting a latch after the column mux, the next column address command can begin sooner
DRAM Evolution
Read Timing for Extended Data Out
Row
Address
Column
Address
Valid
Dataout
RAS
CAS
Address
DQ
Column
Address
Column
Address
Valid
Dataout
Valid
Dataout
Data Transfer
Column Access
Transfer Overlap
Row Access
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
by driving the col-addr latch from an internal counter rather than an external signal, the minimum cycle time for driving the output bus was reduced by roughly 30%
DRAM Evolution
Read Timing for Burst EDO
Row
Address
Column
Address
RAS
CAS
Address
DQ
Data Transfer
Column Access
Transfer Overlap
Row Access
Valid
Data
Valid
Data
Valid
Data
Valid
Data
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
output latch on EDO allowed you to start CAS sooner for next accesss (to same row)
latch whole row in ESDRAM -- allows you to start precharge & RAS sooner for thee next page access -- HIDE THE PRECHARGE OVERHEAD.
DRAM Evolution
Inter-Row Read Timing for ESDRAM
Command
Address
DQ
Clock
Row Addr
Col Addr
Valid Data
Valid Data
Valid Data
Valid Data
ACT READ
Row Addr
Col Addr
Valid Data
Valid Data
Valid Data
Valid Data
PRE ACT READ
Regular CAS-2 SDRAM, R/R to same bank
Command
Address
DQ
Clock
Row Addr
Col Addr
Valid Data
Valid Data
Valid Data
Valid Data
ACT READ
Row Addr
Col Addr
Valid Data
Valid Data
Valid Data
Valid Data
ACT READ
ESDRAM, R/R to same bank
PRE
Bank
Bank
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
neat feature of this type of buffering: write-around
DRAM Evolution
Write-Around in ESDRAM
(can second READ be this aggressive?)
Command
Address
DQ
Clock
Row Addr
Col Addr
Valid Data
Valid Data
Valid Data
Valid Data
ACT READ
Row Addr
Col Addr
Valid Data Valid Data Valid Data Valid Data
PRE ACT WRITE
Regular CAS-2 SDRAM, R/W/R to same bank, rows 0/1/
Command
Address
DQ
Clock
Row Addr
Col Addr
Valid Data Valid Data Valid Data Valid Data
ACT READ
Row Addr
Col Addr
Valid Data Valid Data Valid Data
Valid Data
ACT WRITE
ESDRAM, R/W/R to same bank, rows 0/1/
PRE
Bank
Bank
Row Addr
Col Addr
Valid Data
Valid Data
Valid Data
PRE ACT READ
Bank
Col Addr
Valid Data
Valid Data
Valid Data
Valid Data
READ
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
main thing ... it is like having a bunch of open row buffers (a la rambus), but the problem is that you must deal with the cache directly (move into and out of it), not the DRAM banks ... adds an extra couple of cycles of latency ... however, you get good bandwidth if the data you want is cache, and you can “prefetch” into cache ahead of when you want it ... originally targetted at reducing latency, now that SDRAM is CAS-2 and RCD-2, this make sense only in a throughput way
DRAM Evolution
Internal Structure of Virtual Channel
Segment cache is software-managed, reduces energy
$
Row Decoder
2Kb Segment
2Kb Segment
2Kb Segment
2Kb Segment
Bank A
Bank B
16 Channels
Input/Output
Buffer
DQs
Sel/Dec
(segments)
Sense
Amps
2Kbit # DQs
Activate Prefetch
Restore
Read
Write
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
FCRAM opts to break up the data array .. only activate a portion of the word line
8K rows requires 13 bits tto select ... FCRAM uses 15 (assuming the array is 8k x 1k ... the data sheet does not specify)
DRAM Evolution
Internal Structure of Fast Cycle RAM
Reduces access time and energy/access
tRCD = 15ns tRCD = 5ns
8M Array
13 bits
Sense Amps
8M Array
15 bits
Sense Amps
SDRAM FCRAM
(two clocks) (one clock)
Row Decoder Row Decoder
(8Kr x 1Kb) (?)
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
Outline
- Basics
- DRAM Evolution: Structural Path
- Advanced Basics
- Memory System Details (Lots)
- DRAM Evolution: Interface Path
- Future Interface Trends & Research Areas
- Performance Modeling:
Architectures, Systems, Embedded
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
Some Technology has legs, some do not have legs, and some have gone belly up.
We’ll start by emaining the fundamental technologies (I/O packaging etc) then explore ome of these technologies in depth a bit later.
What Does This All Mean?
EDO
BEDO
FPM
SLDRAM
DDR II
DDR
SDRAM
SDRAM
D-RDRAM
ESDRAM
FCRAM
RLDRAM
xDDR II
netDRAM
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
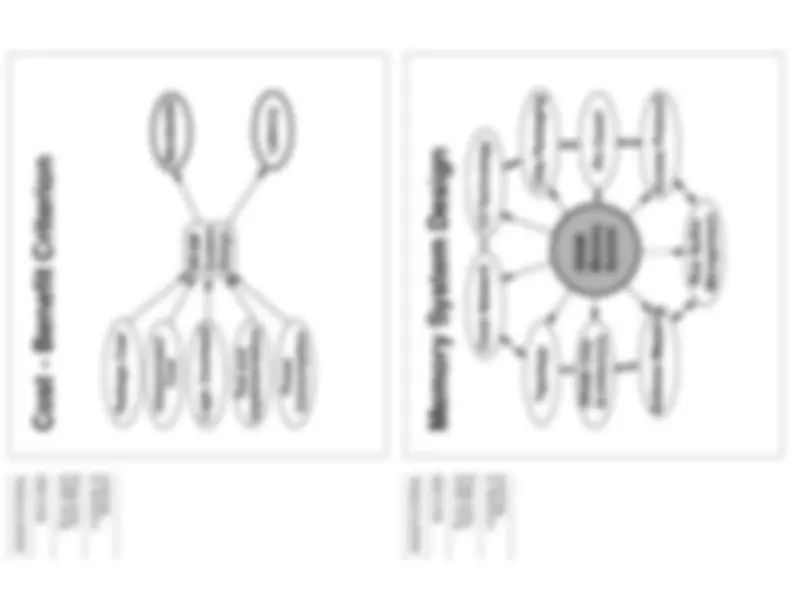
What is a “good” system?
It’s all about the cost of a system. This is a multi- dimensional tradeoff problem. Especially tough when the relative cost factors of pins, die area, and the demands of bandwidth and latency keeps on changing. Good decisions for one generation may not be good for future generations. This is why we don’t keep a DRAM protocol for a long time. FPM lasted a while, but we’ve quickly progressed through EDO, SDRAM, DDR/RDRAM, and now DDR II and whatever else is on the horizon.
Cost - Benefit Criterion
Logic Overhead
Power
Consumption
Package Cost
Test and
DRAM
System
Design
Bandwidth
Latency
Implementation
Interconnect Cost
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
Now we’ll really get our hands dirty, and try to become DRAM designers. That is, we want to understand the tradeoffs, and design our own memory system with DRAM cells. By doing this, we can gain some insight into some of the basis of claims by proponents of various DRAM memory systems.
A Memory System is a system that has many parts. It’s a set of technologies and design decisions. All of the parts are inter-related, but for the sake of discussion, we’ll splite the components into ovals seen here, and try to examine each part of a DRAM system separately.
Memory System Design
DRAM
Memory
System
Topology
I/O Technology
Access Protocol
DRAM Chip
Architecture
Clock Network
Row Buffer
Address Mapping
Management
Pin Count
Chip Packaging
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
First, we have to introduce the concept that signal propagation takes finite time. Limited by the speed of light, or rather ideal transmission lines we should have speed of approximately 2/ the speed of light. That gets us 20cm/ns. All signals, including system wide clock signals has to be sent on a system board, so if you sent a clock signal from point A to point B on an ideal signal line, point B won’t be able to tell that the clock has change until at the earliest, 1/20 ns/cm * distance later that the clock has risen.
Then again, PC boards are not exactly ideal transmission lines. (ringing effect, drive strength, etc) The concept of “Synchronous” breaks down when different parts of the system observe different clocks. Kind of like relativity
Signal Propagation
Ideal Transmission Line
A (^) B
PC Board + Module Connectors +
Varying Electrical Loads
= Rather non-Ideal Transmission Line
~ 0.66c = 20 cm/ns
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
When we build a “synchronous system” on a PCB board, how do we distribute the clock signal? Do we want a sliding time domain? Is H Tree do-able to N-modules in parallel? Skew compensation?
Clocking Issues
0
th N
th
0
th N
th
Clk
SRC
Clk
SRC
What Kind of Clocking System?
Figure 1:
Sliding Time
Figure 2:
H Tree?
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
We would want the chips to be on a “global clock”, everyone is perfectly synchronous, but since clock signals are delivered through wires, different chips in the system will see the rising edge of a clock a little bit earlier/ later than other chips.
While an H-Tree may work for a low freq system, we really need a clock for sending (writing) signals from the controller to the chips, and another one for snding signals from chips to controller (reading)
Clocking Issues
0
th N
th
0
th N
th
Clk
SRC
Clk
SRC
We need different “clocks” for R/W
Figure 1:
Write Data
Figure 2:
Read Data
Signal Direction
Signal Direction
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
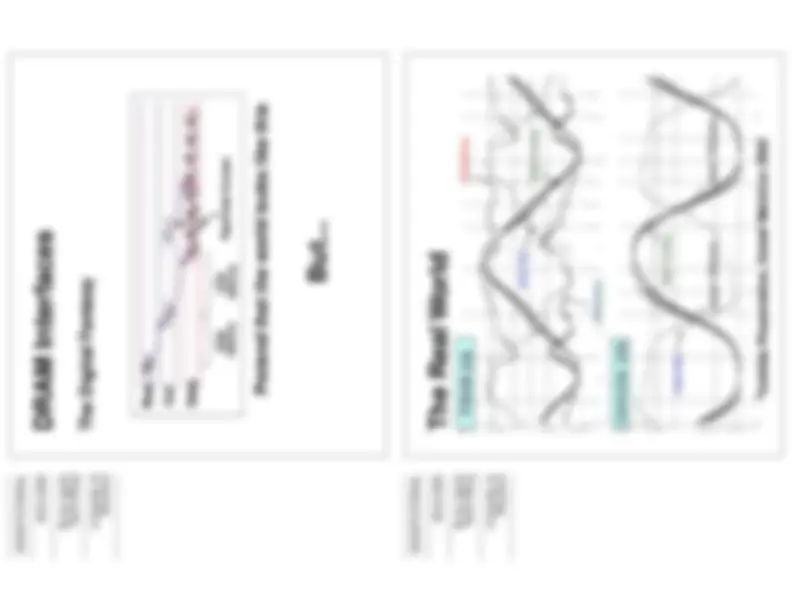
We purposefully “routed path # to be a bit longer than path #1 to illustrate the point in between the signal path length differentials. As illustrated, signals will reach load B at a later time than load A simply because it is farther away from controller than load A.
It is also difficult to do path length and impedence matching on a system board. Sometimes heroic efforts must be utilized to get us a nice “parallel” bus.
Path Length Differential
A
Controller
Path #
Path #
Path #
Bus Signal 2 Bus Signal 1
Intermodule Connectors
B
High Frequency AND Wide Parallel
Busses are Difficult to Implement
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
A “System” is a hard thing to design. Especially one that allows end users to perform configurations that will impact timing. To guarentee functional correctness of the system, all corner cases of variances in loading and timing must be accounted for.
Timing Variations
Controller
Controller
4 Loads
1 Load
Clock
Cmd to 1 Load
Cmd to 4 Loads
How many DIMMs in System?
How many devices on each DIMM?
Infinite variations on timing!
Who built the memory module?
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
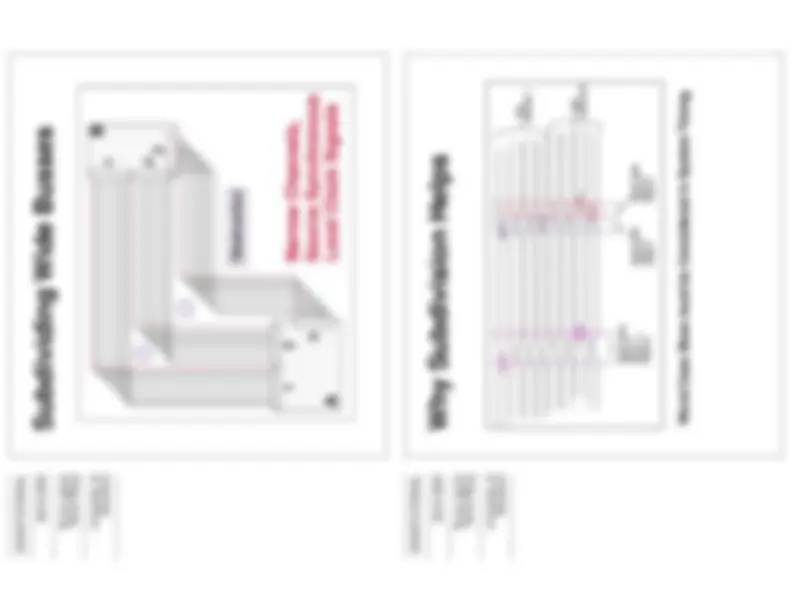
To ensure that a lightly loaded system and a fully loaded system do not differ significantly in timing, we either have duplicate signals sent to different memory modules, or we have the same signal line, but the signal line uses variable strengths to drive the I/O pads, depending on if the system has 1,2,3 or 4 loads.
Loading Balance
Controller
Controller
Controller
Controller
Duplicate
Signal
Lines
Variable
Signal
Drive
Strength
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
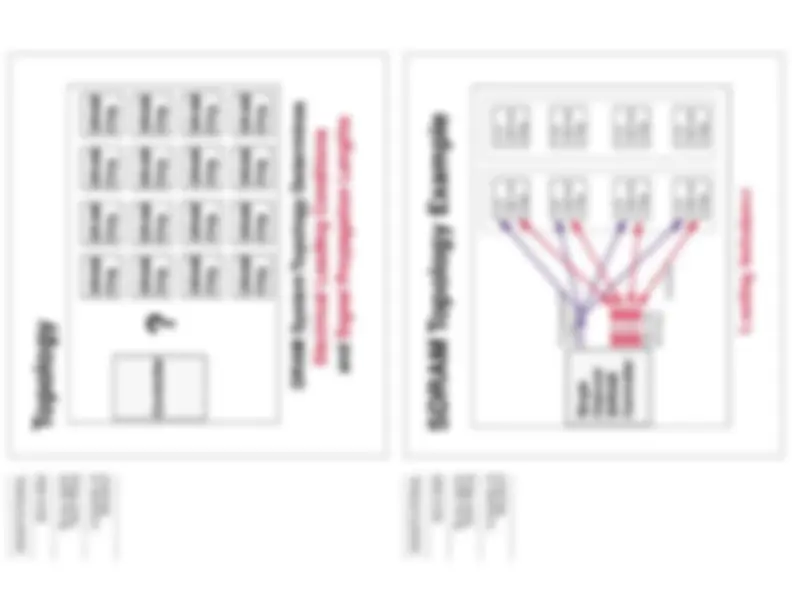
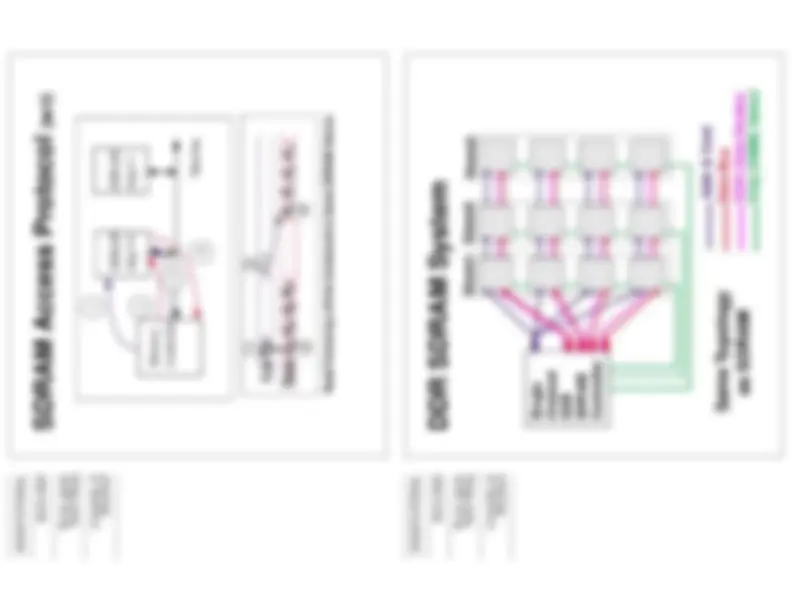
Self Explanatory. topology determines loading and signal propagation lengths.
Topology
Controller
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM
Chip
DRAM System Topology Determines
and Signal Propagation Lengths
Electrical Loading Conditions
DRAM TUTORIAL
ISCA 2002
Bruce Jacob
David Wang
University of
Maryland
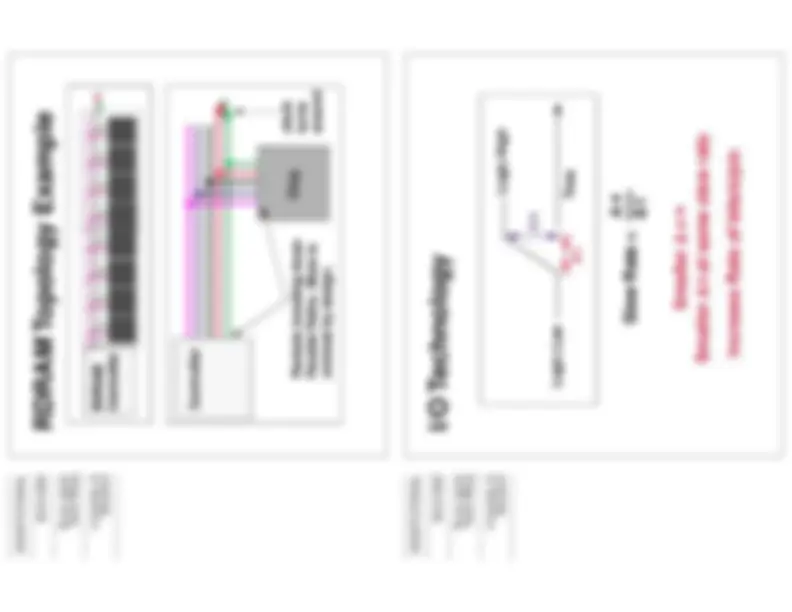
Very simple topology. The clock signal that turns around is very nice. Solves problem of needing multiple clocks.
SDRAM Topology Example
Command &
Data bus
Single
Channel
SDRAM
Controller
Address
(64 bits)
(16 bits)
Loading Imbalance
x
DRAM
Chip
x
DRAM
Chip
x
DRAM
Chip
x
DRAM
Chip
x
DRAM
Chip
x
DRAM
Chip
x
DRAM
Chip
x
DRAM
Chip