Download Module 8: Cache Memory Optimizations | ECE 4100 and more Study notes Computer Architecture and Organization in PDF only on Docsity!
ECE 4100/6100: Yalamanchili^
Module 8: Cache MemoryModule 8: Cache MemoryOptimizationsOptimizations
Improving the Performance of the Cache Hierarchy • Reductions in miss penalty • Reductions in the miss rate • Reductions in the hit time • Compiler optimizations
Hit Time Miss PenaltyMiss Rate
Analysis AMAT = Hit_time+ miss_rate* miss_penalty^ L1 L1^ L1 Miss_penalty = hit_time + miss_rate^ * miss_penalty^ L1 L2 L2^ L2 AMAT = Hit_time+ miss_rateL1 L1 (hit_time + miss_rate* miss_penalty^ L2 L2^ L2 • Local miss rate – Defined with respect to the cache • Global miss rate – Defined with respect to the total number of memory references
Performance • Note L2 hit time not that important, why? • Miss rate behavior of large L2 indistinguishable from a singlecache – Global miss rate a good indicator of performance
ECE 4100/6100: S. Yalamanchili^
Multilevel Inclusion/Exclusion 0x40 0x22 0x35^ 0x27v 0x66 0x76 0x01^ 0x00v 0x40 0x22 0x35^ 0x27v 0x55 0x56 0x12^ 0x34v 0x08 0x16 0x32^ 0x64v 0x66 0x76 0x01^ 0x00v^ •^ Increase in miss rate • Simplifies coherencebut reduced costmaintenance
0x54^ 0x36^ 0x22^ 0x47v0x000x270x69^ 0x36^ 0x21^ 0x02v0x400x00 0x50^ 0x22^ 0x35^ 0x28v0x270x770x55^ 0x76^ 0x42^ 0x34v0x340x440x08^ 0x26^ 0x38^ 0x64v0x640x620x68^ 0x76^ 0x01^ 0x40v0x400x Invalidate L1 entry when replaced
Swap with L2 entry when replaced
2. Critical Word First/Early Restart • Fetch referenced^ word^ first^ and^ remainder
of^ the^ line^ in^ the Wordboundary background • Standard line fetch but referenced word is forwarded to the CPUwhen it is fetched • Gains improve for larger line size • Complexity of multiple, successive references to the same block Memory 0x400x44 line 0x480x4C WordReferenced bythe CPU
4. Merging Write Buffer (write combining) • Improving the efficiency of write buffers • Combine sequential writes into a burst transaction to memory • Amortize transfer startup overhead
Fall 2003^^11
Performance of Write Combining^ Effects of Write-Combining on PIO 1401201008060402001 10 100 1000 10000 • Close to 90% bus bandwidth utilization
(^100000 1000000) Injection Burst Size Injection Bandwidth (MB/s)
PIO Write-CombiningPIO Plain
Reducing the Miss Rate • Reading: Section 5.5 • Focus on reducing – Compulsory misses^ Æ^ e.g., larger block size – Capacity misses^ Æ^ e.g., larger cache – Conflict misses^ Æ^ e.g., higher associativity • Trade-off miss rate with – Hit time – e.g., higher associativity can increase hit time – Miss penalty – e.g., larger block size can increase miss penalty
1: Larger Block Size • Larger block size increases spatial locality at the (eventual) expenseof temporal locality (compare Figures 5.17 & 5.18) • Reduces compulsory^ misses^ but^ (eventually)^
increases^ conflict misses • Reductions in miss rate are accompanied by increase in miss penalty^ –^ What happens to AMAT?^ –^ High (low) latency, high (low) bandwidth memory impact on block size
3. Way Prediction and Pseudo Associative Caches • Way Prediction^ –^ Use set-associative caches but predict the line in the set^ –^ Multiplexer is set early^ –^ Makes the common case fast^ –^ We can see a natural affinity with I-cache behavior^ –^ 2-way set associative 21264 I-cache with predictor bit– 1cycle hit vs. 3 cycle hit^ –^ Activity management for power management • Variant is pseudo associative cache^ –^ Each set has a fast hit line and a slow hit line (fixed!)^ –^ Maintenance of a fast hit block requires transfers from the slowhit block^ –^ Performance degradation due to too many slow hits
4. Compiler Techniques • Memory hierarchy exposed to the compiler – We can schedule for execution performance, why not schedulefor miss rate or miss penalty? • Examples – Re-ordering instructions to improve locality – Re-ordering data accesses to improve locality – Reduce conflict misses by re-mapping of instructions or data inmemory
ECE 4100/6100: S. Yalamanchili^
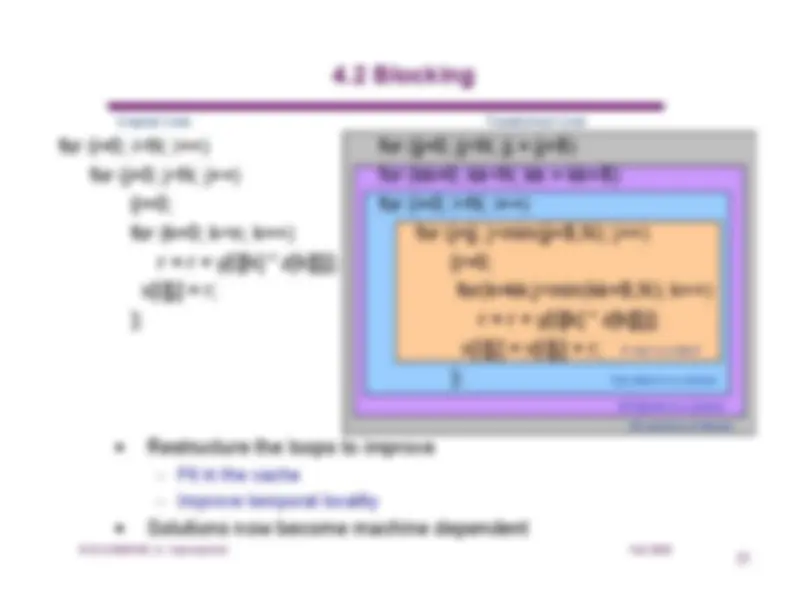
4.2 Blocking
for (i=0; i<N; i++)for (j=0; j<N; j++){r=0;for (k=0; k<n; k++)r = r + y[i][k] * z[k][[j];x[i][j] = r;};
for (jj=0; jj<N; jj = jj+B)for (kk=0; kk<N; kk = kk+B)for (i=0; i<N; i++)for (j=jj; j<min(jj+B,N); j++){r=0;for(k=kk;j<min(kk+B,N); k++)r = r + y[i][k] * z[k][[j];x[i][j] = x[i][j] + r;};
-^ Restructure the loops to improve^ –^ Fit in the cache^ –^ Improve temporal locality •^ Solutions now become machine dependent
Transformed Code A row in a blockOne block in a column^ All blocks in a columnAll columns of blocks Original Code
4.2 Blocking (cont.) Compute the partialproduct for this blockCompute a row in theblock (j and k)Complete computationof Block (0,0) (i)Complete computationof Blocks in a column(kk) • What is the miss behavior? • Decompose the computation to operate on BxB blocks such thatthree blocks fit in the cache • Reduce the overall number of worst case misses by a factor of B
y[i][k] Complete computationof all columns (jj) z[k][j]