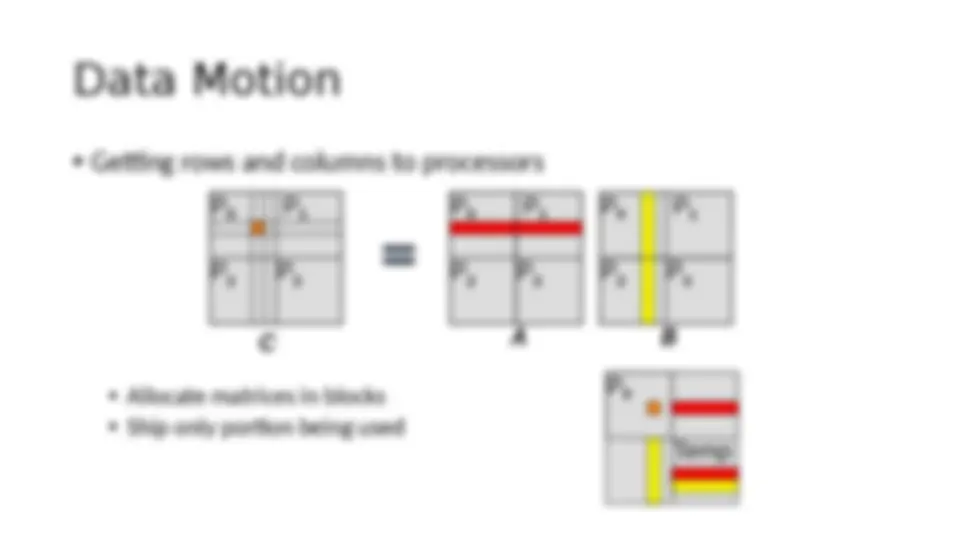
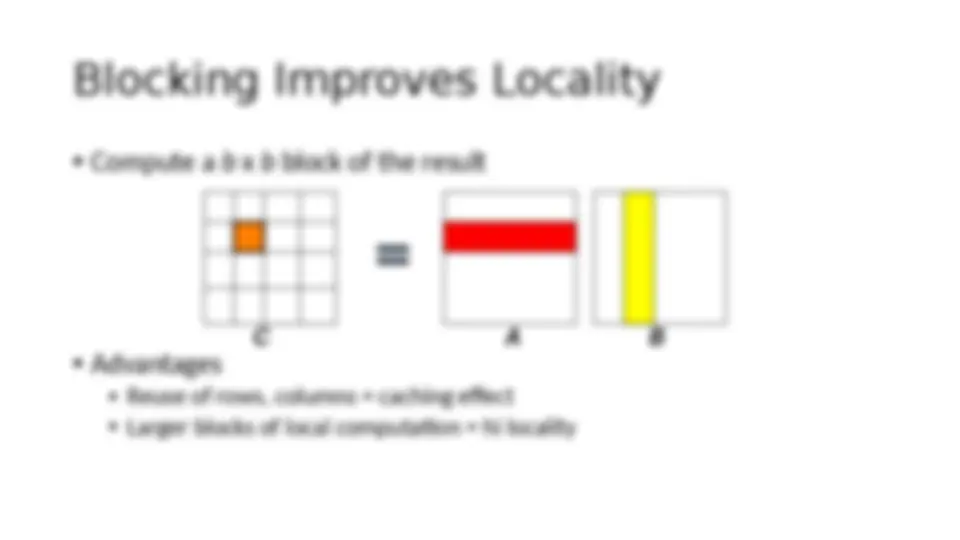
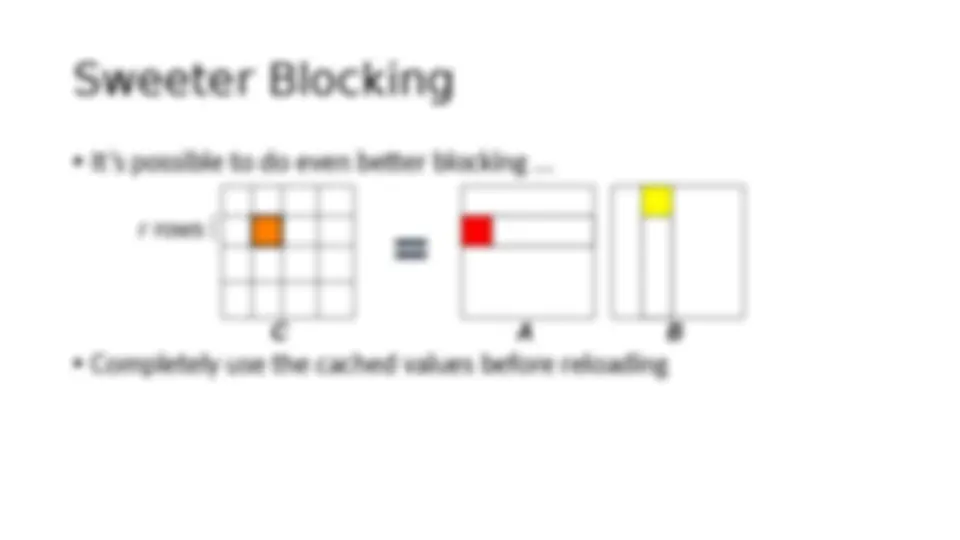
Download PARALLEL ALGORITHMS CONTEXT and more Lecture notes Parallel Computing and Programming in PDF only on Docsity!
Parallel and &
Distributed Systems
MOD 4: PARALLEL
ALGORITHMS
MOD 4 - Parallel Algorithms
CSE524 Parallel
Algorithms
Part I: Introduction
Goal: Set the parameters for studying parallelism
Why Study Parallelism?
- (^) After all, for most of our daily computer uses, sequential processing is plenty fast - It is a fundamental departure from the “normal” computer model, therefore
it is inherently cool
- (^) The extra power from parallel computers is enabling in science, engineering,
business, …
- (^) Multicore chips present a new opportunity
- (^) Deep intellectual challenges for CS -- models, programming languages,
algorithms, HW, …
Size vs Power
- (^) Power5 (Server)
- (^) 389mm^
- (^) 120W@1900MHz
- Intel Core2 sc (laptop)
- ARM Cortex A8 (automobiles)
- (^) Tensilica DP (cell phones / printers)
- (^) 0.8mm^
- (^) 0.09W@600MHz
- (^) Tensilica Xtensa (Cisco router)
- 0.32mm^2 for 3!
- (^) 0.05W@600MHz
Intel Core
ARM TensilicaDP Xtensa x 3
Power 5
Each processor operates with 0.3-0.1 efficiency of the largest chip: more threads, lower power
Topic Overview
- (^) Goal: To give a good idea of parallel computation
- Concepts -- looking at problems with “parallel eyes”
- (^) Algorithms -- different resources; different goals
- (^) Languages -- reduce control flow; increase independence; new abstractions
- (^) Hardware -- the challenge is communication, not instruction execution
- (^) Programming -- describe the computation without saying it sequentially
- (^) Practical wisdom about using parallelism
Parallel vs Distributed Computing
- (^) Comparisons are often matters of degree Characteristic Parallel Distributed Overall Goal Speed Convenience Interactions Frequent Infrequent Granularity Fine Coarse Reliable Assumed Not Assumed
Parallel vs Concurrent
- (^) In OS and DB communities execution of multiple threads is logically simultaneous
- (^) In Arch and HPC communities execution of multiple threads is physically simultaneous
- (^) The issues are often the same, say with respect to races
- (^) Parallelism can achieve states that are impossible with concurrent execution because two events happen at once
Parallel Summation
- (^) To sum a sequence in parallel
- add pairs of values producing 1st level results,
- add pairs of 1st level results producing 2nd level results,
- (^) sum pairs of 2nd level results …
- (^) That is,
(…((A[0]+A[1]) + (A[2]+A[3])) + ... + (A[n-2]+A[n-1]))…)
Express the Two Formulations
- (^) Graphic representation makes difference clear
- (^) Same number of operations; different order 6 4 16 10 16 14 2 8
What’s the Problem?
- (^) It’s not likely a compiler will produce parallel code from a C specification any time soon…
- (^) Fact: For most computations, a “best” sequential solution (practically, not theoretically) and a “best” parallel solution are usually fundamentally different … - (^) Different solution paradigms imply computations are not
“simply” related
- (^) Compiler transformations generally preserve the solution
paradigm
Therefore... the programmer must discover the || solution
A Related Computation
- (^) Consider computing the prefix sums
- (^) Semantics ...
- (^) A[0] is unchanged
- (^) A[1] = A[1] + A[0]
- A[2] = A[2] + (A[1] + A[0])
- (^) A[n-1] = A[n-1] + (A[n-2] + ( ... (A[1] + A[0]) … )
for (i=1; i<n; i++) {
A[i] += A[i-1];
A[i] is the sum of the first i + 1 elements What advantage can ||ism give?
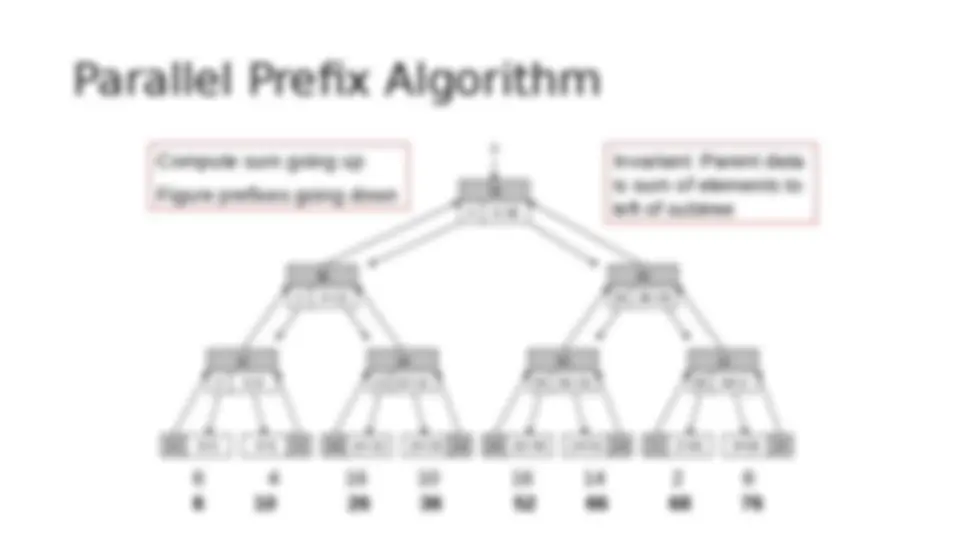
10 0 0+ 6 6+0 4+6 4 16 16+10 10+26 10 16 16+36 14+52 14 2 2+66 8+68 8 26 10 10+ 30 36 36+ 10 66 66+ 36 0 0+ 40 36 36+ 76 0 0+ 0 Parallel Prefix Algorithm 6 4 16 10 16 14 2 8 6 10 26 36 52 66 68 76 Compute sum going up Figure prefixes going down Invariant: Parent data is sum of elements to left of subtree
Fundamental Tool of || Pgmming
- (^) Original research on parallel prefix algorithm published by R. E. Ladner and M. J. Fischer Parallel Prefix Computation Journal of the ACM 27(4):831-838, 1980 The Ladner-Fischer algorithm requires 2log n time , twice as much as simple tournament global sum, not linear time
Applies to a wide class of operations