Download Parallel Processing and more Assignments Parallel Computing and Programming in PDF only on Docsity!
Thread-‐Level Parallelism
15-‐213: Introduc0on to Computer Systems
th
Lecture, Nov. 30, 2010
Instructors:
Randy Bryant and Dave O’Hallaron
Today
Parallel Compu:ng Hardware
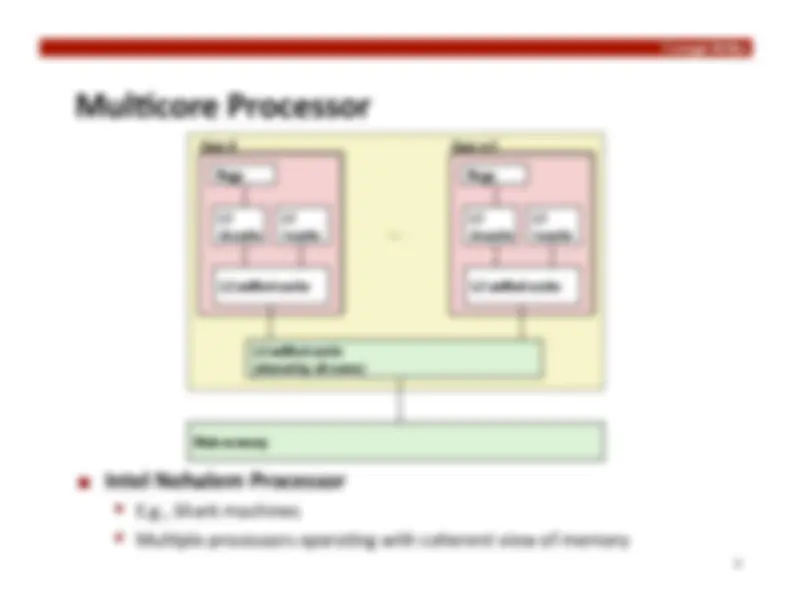
Mul0core
Mul0ple separate processors on single chip
Hyperthreading
Replicated instruc0on execu0on hardware in each processor
Maintaining cache consistency
Thread Level Parallelism
SpliMng program into independent tasks
Example: Parallel summa0on
Some performance ar0facts
Divide-‐and conquer parallelism
Example: Parallel quicksort
Memory Consistency
What are the possible values printed?
Depends on memory consistency model
Abstract model of how hardware handles concurrent accesses
Sequen:al consistency
Overall effect consistent with each individual thread
Otherwise, arbitrary interleaving
int a = 1;
int b = 100;
Thread1:
Wa: a = 2;
Rb: print(b);
Thread2:
Wb: b = 200;
Ra: print(a);
Wa Rb
Wb Ra
Thread consistency
constraints
Sequen:al Consistency Example
Impossible outputs
100, 1 and 1, 100
Would require reaching both Ra and Rb before Wa and Wb
Wa
Rb Wb Ra
Wb
Rb Ra
Ra Rb
Wb
Ra Wa Rb
Wa
Ra Rb
Rb Ra
Wa Rb
Wb Ra
Thread consistency
constraints
int a = 1;
int b = 100;
Thread1:
Wa: a = 2;
Rb: print(b);
Thread2:
Wb: b = 200;
Ra: print(a);
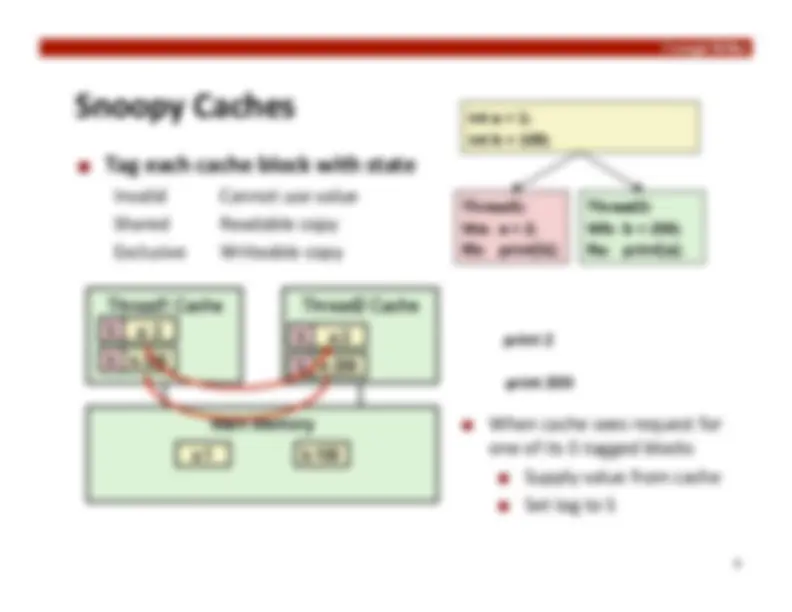
Snoopy Caches
Tag each cache block with state
Invalid Cannot use value
Shared Readable copy
Exclusive Writeable copy
Main Memory
a:1 b:
Thread1 Cache Thread2 Cache
E a: 2
E b:
int a = 1;
int b = 100;
Thread1:
Wa: a = 2;
Rb: print(b);
Thread2:
Wb: b = 200;
Ra: print(a);
Snoopy Caches
Tag each cache block with state
Invalid Cannot use value
Shared Readable copy
Exclusive Writeable copy
Main Memory
a:1 b:
Thread1 Cache Thread2 Cache
E a: 2
E b:
print 200
S b:200 S b:
S a:2 print 2
S a: 2
int a = 1;
int b = 100;
Thread1:
Wa: a = 2;
Rb: print(b);
Thread2:
Wb: b = 200;
Ra: print(a);
When cache sees request for
one of its E-‐tagged blocks
Supply value from cache
Set tag to S
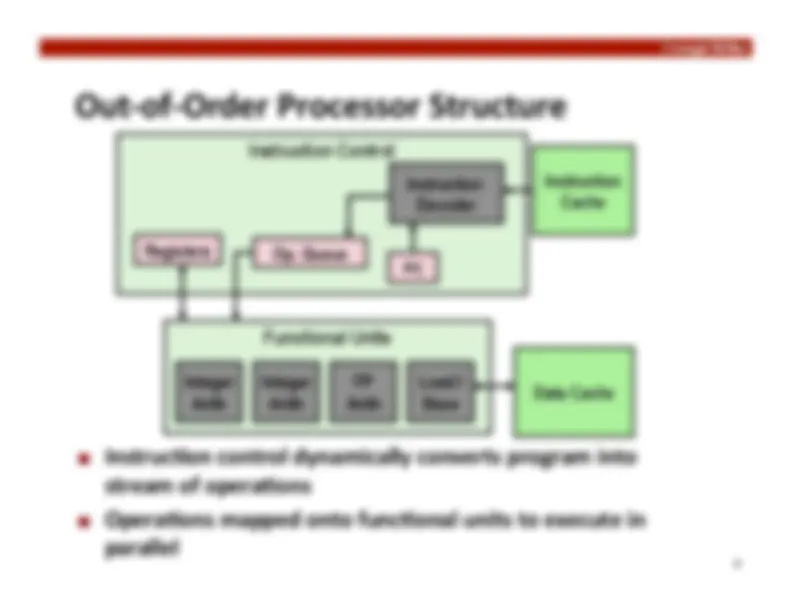
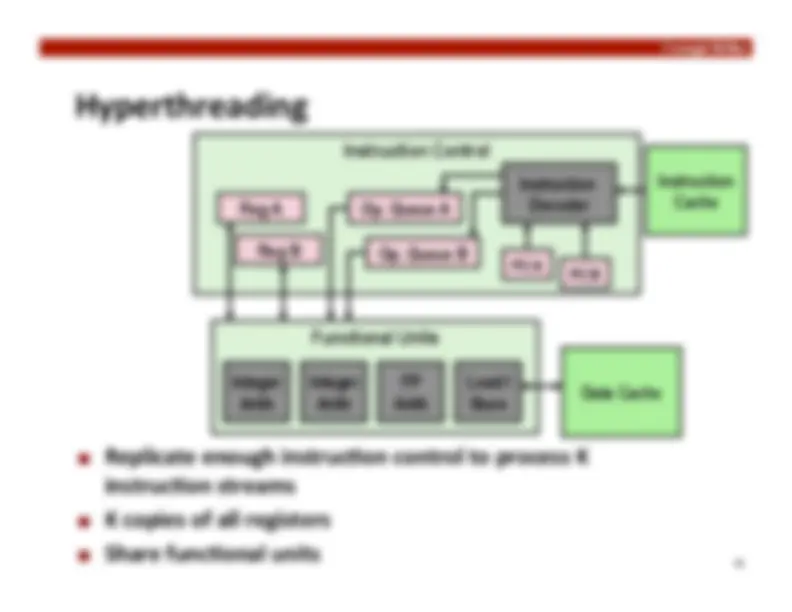
Hyperthreading
Replicate enough instruc:on control to process K
instruc:on streams
K copies of all registers
Share func:onal units
Functional Units
Integer
Arith
Integer
Arith
FP
Arith
Load /
Store
Instruction Control
Reg B
Instruction
Decoder
Op. Queue B
Data Cache
Instruction
Cache
Reg A Op. Queue A
PC A
PC B
Summary: Crea:ng Parallel Machines
Mul:core
Separate instruc0on logic and func0onal units
Some shared, some private caches
Must implement cache coherency
Hyperthreading
Also called “simultaneous mul0threading”
Separate program state
Shared func0onal units & caches
No special control needed for coherency
Combining
Shark machines: 8 cores, each with 2-‐way hyperthreading
Theore0cal speedup of 16X
Never achieved in our benchmarks
Accumula:ng in Single Global Variable:
Declara:ons
typedef unsigned long data_t; /* Single accumulator / volatile data_t global_sum; / Mutex & semaphore for global sum / sem_t semaphore; pthread_mutex_t mutex; / Number of elements summed by each thread / size_t nelems_per_thread; / Keep track of thread IDs / pthread_t tid[MAXTHREADS]; / Identify each thread */ int myid[MAXTHREADS];
Accumula:ng in Single Global Variable:
Opera:on
nelems_per_thread = nelems / nthreads; /* Set global value / global_sum = 0; / Create threads and wait for them to finish / for (i = 0; i < nthreads; i++) { myid[i] = i; Pthread_create(&tid[i], NULL, thread_fun, &myid[i]); } for (i = 0; i < nthreads; i++) Pthread_join(tid[i], NULL); result = global_sum; / Add leftover elements */ for (e = nthreads * nelems_per_thread; e < nelems; e++) result += e;
Unsynchronized Performance
N = 2
Best speedup = 2.86X
Gets wrong answer when > 1 thread!
Thread Func:on: Semaphore / Mutex
void *sum_sem(void *vargp) { int myid = *((int *)vargp); size_t start = myid * nelems_per_thread; size_t end = start + nelems_per_thread; size_t i; for (i = start; i < end; i++) { sem_wait(&semaphore); global_sum += i; sem_post(&semaphore); } return NULL; } sem_wait(&semaphore); global_sum += i; sem_post(&semaphore); pthread_mutex_lock(&mutex); global_sum += i; pthread_mutex_unlock(&mutex);
Semaphore
Mutex
Separate Accumula:on
Method #2: Each thread accumulates into separate
variable
2A: Accumulate in con0guous array elements
2B: Accumulate in spaced-‐apart array elements
2C: Accumulate in registers
/* Partial sum computed by each thread / data_t psum[MAXTHREADSMAXSPACING]; /* Spacing between accumulators */ size_t spacing = 1;
Separate Accumula:on: Opera:on
nelems_per_thread = nelems / nthreads; /* Create threads and wait for them to finish / for (i = 0; i < nthreads; i++) { myid[i] = i; psum[ispacing] = 0; Pthread_create(&tid[i], NULL, thread_fun, &myid[i]); } for (i = 0; i < nthreads; i++) Pthread_join(tid[i], NULL); result = 0; /* Add up the partial sums computed by each thread / for (i = 0; i < nthreads; i++) result += psum[ispacing]; /* Add leftover elements */ for (e = nthreads * nelems_per_thread; e < nelems; e++) result += e;