Download Verification Techniques - Design Verification and Test - Lecture Notes and more Study notes Design and Analysis of Algorithms in PDF only on Docsity!
1
Module-V
Lecture-I
Verification Techniques
1. Introduction In Module 4 (on Binary Decision Diagrams (BDDs)) we have discussed that BDD serves as a good data structure to represent and operate on Boolean equations. So they are widely used for verification (e.g., equivalence checking) when we work at the binary level. Following that in Module 5 (on Temporal Logic), we have discussed that if we are working at higher levels of design abstraction (than Boolean level), then clauses to be verified and modelling of the design need to be done at higher levels. We have presented Computational Tree Logic (CTL) in detail which can be used to formulate clauses to be verified at higher levels of abstraction. Also we have broadly given the idea regarding how to determine if a CTL formula holds in a state of the model. However, we have not discussed any algorithm or automated techniques that perform the CTL model checking i.e., “determine if a CTL formula holds in a state of the model”. In this module (from next lecture) we will discuss CTL model checking algorithm. Before that in the present lecture we will present an overview of different verification techniques.
In traditional design flow, generally after going through the design phase, we go for implementation/fabrication and then testing. If a design error reports at the later point of design/implementation phase, then more time and so money is spent to rectify the design. Therefore emphasis has been given to capture the design fault at the early phase of the system development and fault removal can be done in the early phase. Generally functional verification is carried out just after the design phase to check the correctness of the design. Formal methods become a very useful technique to formally verify the design [1].
Several Formal Verification methods have been proposed and are under research as an alternative to classical simulation techniques, since it cannot guarantee sufficient coverage of the design [2]. In addition to this simulation is a slow process. Formal Verification techniques ensure functional correctness and they are more reliable and cost effective, less time consuming. The main concept of Formal Verification is not simulate some vectors; instead prove the functional correctness of a design.
2
Several proof methodologies are employed to verify the design. Notably among them are Equivalence checkers, Theorem Prover, Satisfiability solver, Model checker, etc [2]. Mathematical logic is the basis to most of these methodologies.
4
Now that we have established the importance of verification in the manufacturing process, it is time to look into how we are actually going to carry out the verification process. There are a multitude of approaches and techniques available when it comes to the problem of carrying out the verification process. We can classify all of them into three broad categories and look into each one of them at a time.
Simulation This is the most basic approach towards verification. In this we exhaustively test the system for all possible case scenarios based on the expected environment of use. The aim is to locate the conditions under which the design will fail or produce undesirable results. It is a very robust method of verification and is able to find any type of design anomalies in the system. The main shortcoming of this approach is that the circuits today are very complex and simulation involves a very large input set of possible test cases. It is sometimes even impossible to simulate the entire system because of the complexity or time constraint.
Non-Exhaustive Simulation As the name suggests, in this approach we try to counter the shortcomings of the simulation approach by testing the design only for some input patterns which are selected based on certain criteria. This type of non-exhaustive simulation had found prominence in the industry in the 80s and the 90s as it was able to detect most of the functional shortcomings with the smallest amount of test scenarios. But the main problem with the approach was that it was not checking the entire system for problems. This led to some very famous design failures and forced the engineers to look into alternate verification approaches. One famous design failure was the Pentium Bug (1994) which was able to slip past the verification process and into thousands in Intel processors manufactured at that time. The problem was with the division algorithm. In Pentium series Intel decided to change the division algorithm to make it more efficient and choose to use SRT division algorithm. It uses a look up table to implement the SRT division algorithm and one of the entries in the lookup table of the processor was incorrect leading to incorrect division in some cases. Non- exhaustive simulation based testing was done and the chip was released to the public. The error was detected later when some users reported incorrect division results. This led to the conclusion that the simulation approach was not sufficient and turned industry’s attention to a different approach towards verification.
5
Formal Methods Even though the formal method approach was available for some time it got little attention before the Pentium bug was reported. To use formal method in practice, we need the proper expertise from the domain. In formal methods certain parameters have to be stated first, like:
- The system problem has to be formally stated.
- The system requirements and the system model have to be stated. After the problem and the model of the system have been formalized all we have to do is to test whether the model will satisfy the given system requirements. By formal definition we mean defining the system based on formal languages and mathematical logic. This may seem like a complex process, but, as we will see it gets greatly simplified in our case because we deal with digital systems which are mathematically very easy to define. For example: In a communication system, the requirement that every transmission should get back in acknowledgement (ack) can be verified based on the communication protocol.
7
- Intended domain of application: The domain of application is also important factor. The verification or specification of hardware is very much different from the software part. And similar differences exist with concurrent versus sequential and reactive versus terminating.
- Pre- vs. post-development: Verification is of greater advantage if introduced early in the development, because errors caught in the early course of system development and production cycle are less costly to rectify.
3.1 Modelling
Modelling is about building representations of things in the ‘real world’ and allowing ideas to be investigated; it is central to all activities in the process for building or creating an artefact of some form or other. In effect, a model is a way of expressing a particular view of an identifiable system of some kind. Models are:
- A means of understanding the problems involved in building something;
- An aid to communication between those involved in the project, especially between the requirements analyst (a development role) and the user, as part of some deliverable;
- A component of the methods used in development activities such as the analysis of the requirements for an artefact and the design of the artefact.
A model is an abstraction, which allows people to concentrate on the essentials of a (complex) problem by keeping out non-essential details. Since there is a limit to how much a person can understand at any one time, we build models to help in activities such as the development of large software systems. For example, developers build different models throughout the development process in order to verify that the eventual software system will meet the requirements.
Models are, in one respect, idealisations in the sense that they are less complicated than reality; they are simplifications of reality. The benefit arises from the fact that only the properties of the world relevant to the job in hand are represented. For example, a road map is a model of a particular part of the earth's surface. We do not show things like vegetation or birds' nests as they are not relevant to the map's purpose. We use a road map to plan our journeys from one place to another and so the map should only contain those aspects of the real world that serve the purpose of planning journeys.
8
A model and the real world are alike in some ways, but different in others. For example, road maps are helpful because they represent the distance between, and relative positions of, a set of places and the routes between them. They use the relevant properties of the real thing with just a change in scale; one centimetre on the road map, for instance, may be equivalent to one kilometre on the ground. A map may be unhelpful if it shows only major roads.
Quite often, a property of the real world may be represented by a different kind of property in a model. In the case of the road map, different colours are normally used to represent different classes or types of road. Such a road map should have a key or legend so that those who read the map can understand what the different coloured lines are intended to represent. In effect, an analogy is being used to exploit the similarity between two different properties: one in the real world and one in the model.
Models of a problem situation are only an approximate representation of that situation. The real world situation will have a complexity that tends to reduce your chances of achieving an exact representation. So, you need to find some way of achieving an acceptable balance between accuracy and manageability. As a project unfolds, there will be a number of practical considerations that result in some compromise. It is for this reason that several different models are built, each one representing different aspects (views) of the real world.
If a model is so complex that its author (or other team members) cannot use it, then that model is of little or no value. However, simplification is only of value if all simplifying assumptions, and their consequences, are made explicit. At some point in a project, any of these assumptions may need to be justified.
Models are subject to change. At the very least they require some form of testing so that a model can maintain its correspondence with reality. As towns and cities expand and contract, a road map must be changed to reflect the new situation. In the worst case, a change in scope necessitates a whole new model. For example, if there was a need to reflect the current status of roads and the traffic on them, a simple road map is inadequate since we would want to show, amongst other things, the changes in traffic density over time.
Unfortunately, not all models of a particular type share the same notation, often because they originate from different sources. For example, different publishers will have different ways of constructing and presenting road maps.
10
References
[1]. Lam, William K., “Hardware Design Verification: Simulation and Formal Method- Based Approaches, 1 st^ Edition, Prentice Hall PTR, 2008. [2]. Fujita, Masahiro, Ghosh, Indradeep and Prasad, Mukul, “Verification Techniques for System-Level Design, 1 st^ Edition, Morgan Kaufmann Publishers Inc, 2007
1
Module-V
Lecture-II, III and IV
CTL Model Checking Algorithm
1. Introduction In the last module we have discussed that CTL is branching time logic and so a model can be best viewed as a tree, rooted at the present instance of time and branching out into the future. Also, when we want to see if a state satisfies a CTL formula, we may find it easier to do so, on the model which is un-winded (infinitely branched out) into infinite trees. However, if we think of implementing a model checker as a program, we certainly cannot unwind transition systems into infinite trees. To cater to this issue we need an efficient algorithm which, given ‘M’ (model), s (state) S (set of states) and Φ(CTL formula) computes whether M,s Φ holds, without unwinding M. If Φ is not satisfied, such an algorithm can be augmented to produce an actual path (=run) of the system demonstrating that M cannot satisfy Φ. In other words, the following is to be done 1. Given the model ‘ M ’, the CTL formula Φ and a state s 0 S as input and the model checking algorithm generates answer ‘yes’ (M, s 0 Φ holds), or ‘no’ (M , s 0 Φ does not hold). 2. If M, s 0 Φ holds, then the set of states s of the model M which satisfy Φ is also generated. 3. If M, s 0 Φ does not hold then a path (=run) of the system demonstrating that M cannot satisfy Φ s also generated; this is called counter example.
In the last module, we have discussed that some of the CTL operators can be expressed with the help of other operators. We have also seen that EX, AF and EU form an adequate set of CTL operators. If we have methods for these three operators, then others can be expressed with the help of these three and eventually we may have methods for other operators also. In this lecture we will study CTL modeling checking algorithms for EX, AF and EU which work without unwinding the model. Also some practical examples of CTL model checking are presented.
3
S
S2 S3^ S
S5 S6 S
p
Figure 1. Example to illustrate SATEX (ψ)
S
S2 S3^ S
S5 S6 S
p
EXp
EXp
Figure 2. States of the example of Figure 1 after labeling
4
2.2 Labeling Algorithm of AF AFψ:
- If any state s is labeled with ψ, label it with AFψ.
- Repeat: label any state with AFψ if all successor states are labeled with AFψ, until there is no change. function SATAF (ψ) /* determines the set of states satisfying AFψ / Begin X := S ; Y := SAT (ψ) ; //set of states satisfying ψ. Repeat until X=Y Begin X := Y; Y:= Y { s S | for all s', (s s' implies s' Y)} / Y pre (Y)*/ End return Y End The algorithm is illustrated using example in Figure 3. Let ψ=p. Initially, X= { S1, S2, S3, S4, S5, S6, S7} and Y= { S4, S5}. Loop 1: X= { S4, S5} Y= Y { S2, S5, S7}= {S2, S4, S5, S7} Loop 2: X= { S2, S4, S5, S7} Y= Y {S2, S5, S6, S7}= {S2, S4, S5, S6, S7} Loop 3: X= {S2, S4, S5, S6, S7} Y= Y {S2, S3, S5, S6, S7}= { S2, S3, S4, S5, S6, S7}
6
2.3 Labeling Algorithm of E(ψ 1 U ψ 2 ) E(ψ 1 U ψ 2 )
- If any state is labeled with ψ2, label it with E(ψ 1 U ψ 2 ).
- Repeat: label any state with E(ψ 1 U ψ 2 ) if it is labeled with ψ 1 and at least one of its successors is labeled with E(ψ 1 U ψ 2 ), until there is no change. function SATEU (ψ 1 U ψ 2 ) /* determines the set of states satisfying E(ψ 1 U ψ 2 ) */ Begin X := S; W := SAT (ψ 1 ); // set of states satisfying ψ 1 Y := SAT (ψ 2 ); // set of states satisfying ψ 2 repeat until X = Y begin X :=Y; Y := Y (W { s S | exists s', ( s s' and s' Y)}) End return Y end
The algorithm is illustrated using example in Figure 5. Let ψ 1 = p1 (^) , ψ 2 = p2. Initially, X = {S1, S2, S3, S4, S5, S6, S7}, Y = {S4, S5} and W = {S1, S6, S7} Loop 1 : X = Y = {S4 ,S5} Y = Y {{S1, S6, S7} {S1,S2, S5, S6, S7}} = {S1, S4, S5, S6, S7} Loop 2 : X = Y = {S1, S4, S5, S6, S7} Y = Y {{S1, S6, S7} {S1, S2, S3, S5, S6, S7}} = { S1, S4, S5, S6, S7}
Since, Y do not change, we stop looping; this is illustrated in Figure 6.
7
S
S2 S3^ S
S5 S6 S
p
p
p2 p1 p Figure 5. Example to illustrate E(ψ 1 U ψ 2 )
S
S2 S3^ S
S5 S6 S E(p1Up2) E(p1Up2) E(p1Up2)
E(p1Up2)
E(p1Up2)
Figure 6. States of the example of Figure 5 after labeling
9
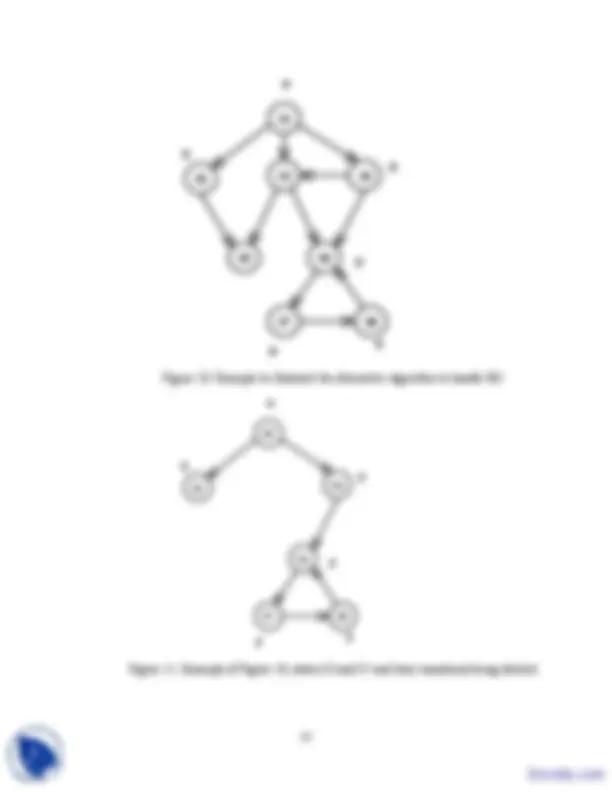
2.4 Handling EG connective directly Step1: Label all the states with EGp. Step2: If any state s is not labeled with p, delete the label EGp. Step3: Repeat Step 3; delete the label EGp from any state if none of its successors is labeled with EGp until there is no change. The algorithm is illustrated with an example shown in Figure 7. As Step 1, all states are labeled with EGp; shown in Figure 7. As Step 2, if any state s is not labeled with p, delete the label EGp; shown in Figure 8. As Step 3, we delete the label of state S since S5 is not labeled with EGp. For all other states, at least one of the successor along a path is labeled with EGp; this is shown in Figure 9.
S2 S3^ S
S
S7 S
S
p,EGp p,EGp
p,EGp
p,EGp
p,EGp
p,EGp
S
EGp
EGp
Figure 7. Example to illustrate EG (all states labeled with EG p)
10
S2 S3^ S
S
S7 S
S
p,EGp p,EGp
p,EGp
p,EGp
p,EGp
p,EGp
S
Figure 8. Example of Figure 7 where label EGp is deleted in states not labeled with p
S2 S3^ S
S
S7 S
S
p,EGp p,EGp
p,EGp
p,EGp
p,EGp
S
Figure 9. Example of Figure 7, label EGp deleted if none of the successors is labeled with p
Broadly speaking, in a similar way we can develop the algorithm for AG, were we need to change Step 3 as “delete the label AGp from any state if at least of its successors is not labeled with AGp until there is no change”.