



PEQUEÑO RESUMEN DE
ESTADÍSTICA
Curso 2016-2017

























Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
Asignatura: estadistica, Profesor: julian julian, Carrera: Química, Universidad: UNIOVI
Tipo: Apuntes
1 / 33

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Curso 2016-
Población : conjunto de elementos de los que queremos obtener información sobre alguna(s) característica(s) de interés.
Muestra : subconjunto de la población del que obtenemos información. Si se ha seleccionado adecuadamente, los datos obtenidos con esta muestra pueden extenderse a toda la población (Inferencia Estadística).
Variable : Se suele denotar con una letra mayúscula (por ejemplo 𝑋). Es la característica estudiada sobre los elementos de una población. Podemos clasificarla según el número de valores que toma en Discretas : el número de valores que toma es finito o numerable Ejemplo : 𝑋 = “número de clientes que son atendidos en un día por un administrativo de un banco” Continuas : puede tomar cualquier valor dentro de, al menos, un intervalo Ejemplo : 𝑋 = “proporción de piezas defectuosas del total de las producidas en una fábrica durante una semana” o según el tipo de valores en Cuantitativas : 𝑋 = “salario que reciben los empleados de una empresa” Cualitativas : 𝑋 = “nacionalidad de los solicitantes de empleo” En general, los valores que toma una variable, cualquiera que sea el tipo de ésta, se denotan por 𝒙𝒊.
Consideremos, por ejemplo, que tenemos 𝑘 valores distintos. Frecuencia absoluta de 𝒙𝒊: número de veces que se observa un valor 𝑥𝑖. Se denota 𝑛𝑖. El tamaño de la muestra es entonces
𝑁 = ∑ 𝑛𝑖
𝑘
𝑖= Frecuencia relativa de 𝒙𝒊: proporción de veces que se observa un valor 𝑥𝑖. Se denota 𝑓𝑖 y se calcula
𝑓𝑖 =
𝑛𝑖 𝑁 Frecuencias acumuladas : cuando trabajamos con variables cuantitativas, podemos ordenar sus valores en orden creciente, y definir las frecuencias acumuladas respectivas: Frecuencia absoluta acumulada de 𝒙𝒊: número de veces que se observa un valor menor o igual que 𝑥𝑖. Se denota 𝑁𝑖 y se calcula
𝑁𝑖 = ∑ 𝑛𝑗
𝑖
𝑗= Frecuencia relativa acumulada de 𝒙𝒊: proporción de veces que se observa un valor menor o igual que 𝑥𝑖. Se denota 𝐹𝑖 y se calcula
∑ 𝑓𝑗
𝑖
𝑗=
ó 𝑁𝑖 ⁄𝑁
Se verifica que 𝑛𝑖 = 𝑁𝑖 − 𝑁𝑖−1 (se da la misma relación con frecuencias relativas 𝑓𝑖 = 𝐹𝑖 − 𝐹𝑖−1).
(frecuencias no acumuladas) (datos no agrupados – aplicado al Ejercicio 1)
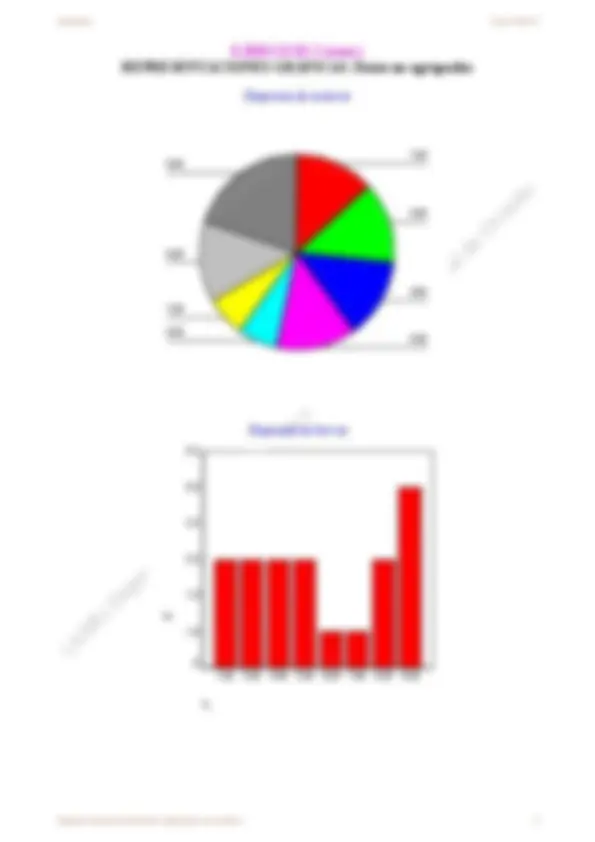
Diagrama de sectores : consiste en asignar, a cada valor de una variable, un sector (circular, o semicircular) de ángulo (o de área) proporcional a su frecuencia. Puede verse lo poco informativo que resulta cuando hay muchos valores. Diagrama de barras : consiste en asignar a cada valor de una variable una barra de longitud (o área o volumen, según cómo la dibujemos) proporcional a su frecuencia (comparar con los datos de la
Histograma : cuando nos dan los datos agrupados en intervalos, consiste en asignar a cada intervalo un rectángulo de área proporcional a su frecuencia
Si consideramos, por ejemplo, que los datos del ejemplo 1 se han agrupado en once clases distintas (todas de la misma amplitud), el resultado que se obtendría sería aproximadamente el que aparece en la gráfica adjunta.
En este ejemplo, puede verse que resulta mucho más apropiado tener los datos agrupados en intervalos, pues un exceso de valores puede llevarnos a representaciones gráficas que no sean sencillas de ver (aquí, por ejemplo, aparece un “hueco” en el que no se observan valores de la variable; en los diagramas anteriores este “hueco” existía, pero se veía a simple vista pues se limitaban a ordenar todos los datos y disponerlos correlativamente, sin tener en cuenta las “distancias” entre ellos). Basta con comparar la gráfica del diagrama de barras y del histogramas, muy parecidas en cuanto a la forma, pero mucho más clara la segunda que la primera para este conjunto de datos.
Para agrupar en intervalos hay que tener en cuenta cómo son las frecuencias de los valores que se agrupan. No obstante, con la aparición de los ordenadores este procedimiento está en desuso, y sólo se utiliza cuando el número de valores diferentes con los que se trabaja es “desmesurado”, y eso impide que, con la tabla de frecuencias y las representaciones gráficas habituales, podamos tener una visión de conjunto apropiada.
20 , 0 25 , 0 30 , 0 35 , 0 40 , 0 45 , 0 50 , 0 55 , 0 60 , 0 65 , 0 70 , 0
8
6
4
2
0
Desv. típ. = 11 , 09 Media= 49 , 3 N= 35 , 00
De dispersión : Si centramos nuestro estudio en la media, podemos reducir el estudio de las medidas de dispersión (separación de los valores observados respecto a un valor central) a: Varianza : está asociada con la media de la distribución. Se define como la media de las distancias al cuadrado entre los valores observados y la media de la distribución. Se denota habitualmente por 𝑆𝑋^2 y se calcula como Algunas propiedades interesantes son𝑆𝑋^2 = ∑^ 𝑘𝑖=1(𝑥 𝑖 − 𝑥̅)^2 𝑓𝑖 ó 𝑆𝑋^2 = 1 𝑁 ∑ 𝑘𝑖=1(𝑥𝑖 − 𝑥̅)^2 𝑛𝑖 𝑆𝑋^2 ≥ 0 𝑆𝑋^2 = 𝑥̅̅^2 ̅^ − 𝑥̅ 2 1 𝑆𝑎𝑋^2 +𝑏= 𝑎^2 𝑆𝑋^2 ∀𝑎, 𝑏 ∈ ℝ Además, si pensamos en calcular la distancia cuadrática media entre los valores de la variable y una constante, la constante en la que se minimiza dicha distancia es la media aritmética. Por eso la varianza es óptima para la media. No obstante, tiene el problema de que no viene en las mismas unidades Desviación típica : para resolver el problema de las unidades se calcula la desviación típica (o desviación estándar). Se define como la raíz cuadrada positiva de la varianza. Se denota 𝑆𝑋 Recorrido : es la diferencia entre el valor más grande y el más pequeño de los observados. Suele denotarse 𝑅𝑒, aunque la notación no está generalizada. También se le conoce en algunos casos como rango. 𝑥 1 ≤ ⋯ ≤ 𝑥𝑘 ⇒ 𝑅𝑒 ≡ 𝑅 ≡ 𝑅(𝑋) = 𝑥𝑘 − 𝑥 1 Rango (o recorrido) intercuartílico : diferencia entre el tercer y el primer cuartil (percentiles 75 y 25, respectivamente). Suele denotarse 𝑅𝐼 y es 𝑅𝐼 = 𝑃 75 (𝑋) − 𝑃 25 (𝑋) ≡ 𝑄 3 (𝑋) − 𝑄 1 (𝑋) Desviación media : es la media de las distancias en valor absoluto entre los valores observados y la mediana de la distribución. Suele denotarse DM. Su uso no está tan extendido por la dificultad de manejar valores absolutos. No obstante, si se intenta minimizar la distancia media en valor absoluto entre los valores de una variable y una constante, esta distancia se minimiza cuando la constante es la mediana, por lo que esta medida es óptima para la mediana.
𝐷𝑀(𝑋) = ∑|𝑥𝑖 − 𝑀𝑒(𝑋)|
𝑘
𝑖= 1
𝑓𝑖
Otras medidas : existen coeficientes de asimetría y de curtosis (o apuntamiento), que nos informan sobre la “forma” de la distribución en relación al “equilibrio” respecto a algún valor central, y la “concentración” alrededor del mismo. Y los momentos que engloban a casi todas las anteriores. Aunque según los campos, existen todavía muchas otras medidas que se pueden definir. Momento de orden r respecto al origen :
𝑎𝑟 = ∑ 𝑥𝑖𝑟^ 𝑓𝑖 𝑖 Momento de orden r respecto a la media :
𝑚𝑟 = ∑(𝑥𝑖 − 𝑥̅)𝑟𝑓𝑖 𝑖 Coeficiente de asimetría :
𝑔 1 =
𝑚 3 𝑆𝑋^3 Coeficiente de curtosis :
𝑔 2 =
𝑚 4 𝑆𝑋^4
− 3
Medidas de concentración : en economía, por ejemplo, se utilizan índices que comparan concentraciones de rentas en población (como el Índice de Gini) y que sirven para saber la equidad de reparto de la riqueza.
(^1) La varianza de 𝑋 es la media de los cuadrados menos el cuadrado de la media, es decir, el momento de orden 2
respecto al origen menos el cuadrado del momento de orden 1 respecto al origen.
Los intervalos de tiempo entre fallos sucesivos del sistema de acondicionamiento de aire de un modelo de avión utilizado habitualmente por una compañía aérea son un indicativo de la calidad del procedimiento de mejora introducido. Seleccionado un avión al azar se han encontrado, en 15 observaciones sucesivas, los siguientes datos en relación al número de días entre dos fallos consecutivos
1 9 7 4 9 4 1 3 8 5 6 5 9 8 3
La variable en estudio es 𝑋 = “número de días entre dos fallos consecutivos” Como son un número finito de datos aislados (variable discreta), la distribución de frecuencias será 𝑥𝑖 𝑛𝑖 𝑓𝑖 𝑁𝑖 𝐹𝑖 1 2 2 / 15 2 2/ 2 0 0 2 2/ 3 2 2 / 15 4 4/ 4 2 2 / 15 6 6/ 5 2 2 / 15 8 8/ 6 1 1 / 15 9 9/ 7 1 1 / 15 10 10/ 8 2 2 / 15 12 12/ 9 3 3 / 15 15 1 𝑁 = 15
NOTA: normalmente en las tablas de frecuencias no se introducen los valores con frecuencia cero, salvo que sea un intervalo en el que se quiere resaltar la ausencia de observaciones.
La media de la distribución sería
𝑥̅ = ∑ 𝑥𝑖𝑓𝑖
𝑘
𝑖=
= 1
2 15
2 15
2 15
2 15
1 15
1 15
2 15
3 15
=
2 + 6 + 8 + 10 + 6 + 7 + 16 + 27 15
=
82 15 La media de los cuadrados es
𝑥̅̅^2 ̅^ = ∑ 𝑥𝑖^2 𝑓𝑖
𝑘
𝑖=
= 1^2
2 15
2 15
2 15
2 15
1 15
1 15
2 15
3 15
=
2 + 18 + 32 + 50 + 36 + 49 + 128 + 243 15
=
558 15 Y, por lo tanto, la varianza será
𝑆𝑋^2 =
558 15
− (
82 15
)
558 15
−
6724 225
=
8370 − 6724 225
=
1646 225 Y la desviación típica
𝑆𝑋 = +√𝑆𝑋^2 = √
1646 225
=
√ 15
La mediana es el valor que está en posición 8 (( 1 2 15 = 7.5) que será^ 𝑀𝑒 = 5. La moda el más frecuente, que corresponde con la frecuencia absoluta 3 que es 𝑀𝑜 = 9.
El percentil de orden 20 (segundo decil) es el que está en la posición 3 ( 2 10 15 = 3) que será^ 𝑃^20 = 3 El percentil de orden 85 es el que está en la posición 13 ( 85 100 15 = 12.75) que será^ 𝑃^85 = 9.
NOTA: algunos textos hacen interpolación entre los valores de la variable situados en las posiciones anterior y posterior al obtenido en el caso en que el porcentaje no proporciona un número entero.
Variable bidimensional : (𝑋, 𝑌)^ denota una variable bidimensional que representa el estudio simultáneo de dos características sobre los elementos de una población.
Valores y frecuencias : Los valores observados se denotarán ahora (𝑥𝑖, 𝑦𝑗) y las frecuencias
asociadas a ese “valor” serán Frecuencia absoluta 𝒏𝒊𝒋: número de veces que un elemento de la muestra ha dado como valor el par (𝑥𝑖, 𝑦𝑗) Frecuencia relativa 𝒇𝒊𝒋: proporción de veces que un elemento de la muestra ha dado como valor el par (𝑥𝑖, 𝑦𝑗)
Ejecicio 3 : Hemos observado el número de días que faltan al trabajo por enfermedad y el salario que cobran al año 10 empleados de una empresa
Empleado Faltas por enfermedad Salario Juan Martínez 2 25. Luis López 5 18. María Fernández 3 17. Gloria Álvarez 7 15. José García 3 17. Jesús González 4 25. Félix Sánchez 2 25. Sara Suárez 6 18. Manuel Alonso 4 15. Belén Rodríguez 3 17.
Si llamo 𝑋=“días que falta por enfermedad” e 𝑌=“salario”, la distribución conjunta de frecuencias de la variable bidimensional es
𝑥𝑖 𝑦𝑗 𝑛𝑖𝑗
2 25.000 2 Hay 2 empleados con 25.000 de salario cada uno y que faltan 2 días por enfermedad cada uno 3 17.500 3 Hay 3 empleados con 17.500 de salario cada uno y que faltan 3 días por enfermedad cada uno 4 15.000 1 Hay un empleado con 15.000 de salario y que falta 4 días por enfermedad 4 25.000 1 Hay un empleado con 25.000 de salario y que falta 4 días por enfermedad 5 18.500 1 Hay un empleado con 18.500 de salario y que falta 5 días por enfermedad
6 18.500 1 Hay un empleado con 18.500 de salario y que falta 6 días por enfermedad 7 15.000 1 Hay un empleado con 15.000 de salario y que falta 7 días por enfermedad 𝑁 = 10 Hay en total 10 empleados
Además puedo decir, por ejemplo: Hay 3 empleados con 25.000 de salario cada uno. Hay 2 empleados que faltan, cada uno, 4 días por enfermedad ….
Distribuciones marginales : dan la información de una de las variables sin tener en cuenta los valores de la otra. Hay dos: Marginal de 𝑿: valores de 𝑋 junto con sus frecuencias 𝑛𝑖. = ∑ 𝑛𝑖𝑗 𝑗 Marginal de 𝒀: valores de 𝑌 junto con sus frecuencias 𝑛.𝑗 = ∑ 𝑛𝑖𝑗 𝑖
Ejemplo : Con los datos del ejercicio 3, las distribuciones marginales son
Marginal de 𝑋 Marginal de 𝑌
𝑥𝑖 𝑛𝑖. 𝑦𝑗 𝑛.𝑗 2 2 15.000 2 3 3 17.500 3 4 2 18.500 2 5 1 25.000 3 6 1 7 1
Distribuciones condicionadas : aparecen cuando estudiamos el comportamiento de una de las variables bajo ciertas condiciones de la otra. Podemos definir tantas como condiciones podamos poner.
Ejemplo : Con los datos del ejercicio 3, podemos calcular, por ejemplo
Faltas por enfermedad para los que cobran 25. 𝑋 ⁄𝑌 = 25. 000
Salarios de los que faltan 4 días por enfermedad 𝑌 ⁄𝑋^ = 4
𝑥𝑖 𝑛𝑖 𝑦𝑗 𝑛𝑗 2 2 15.000 1 4 1 25.000 1 𝑛.𝑗 = (^3) 𝑛𝑖. = 2
Faltas por enfermedad para los que cobran menos de 20. 𝑋 ⁄𝑌 ≤ 20. 000
Salario de los que faltan como mucho 5 días 𝑌 ⁄𝑋^ ≤ 5
𝑥𝑖 𝑛𝑖 𝑦𝑗 𝑛𝑗 3 3 15.000 1 4 1 17.500 3 5 1 18.500 1 6 1 25.000 3 7 1 𝑛𝑖. = 8 𝑛.𝑗 = 7
Se han recogido datos relativos a 𝑋=”número de pulsaciones por minuto que tiene un trabajador concreto de una línea de montaje después de 6 horas de trabajo” e 𝑌=”número de accidentes en la línea de montaje después de 6 horas de actividad provocados por ese trabajador”. Estos datos corresponden a la evolución de un trabajador en concreto durante los últimos 50 días laborables. 𝑌 \ 𝑋 75 80 90 100 0 1 1 5 1 12 15 10 2 4 2 Nos preguntamos: si existe alguna relación entre las dos variables si podemos encontrar una función que nos explique el comportamiento de una de ellas a partir de la otra si podemos predecir lo que ocurrirá con ese trabajador un día que se le han detectado 100 pulsaciones por minuto si la existencia (o no) de accidente en esas condiciones está “garantizada” si tendríamos la misma “garantía” al hacer la previsión para un día en el que ese trabajador tuviera 120 pulsaciones por minuto Está claro: que las variables son estadísticamente dependientes ya que, por ejemplo, 𝑓(𝑋 = 75, 𝑌 = 0) = 1 50 pero^ 𝑓(𝑋 = 75) =^
7 50 y^ 𝑓(𝑌 = 0) =^
1 50 , por lo que se obtiene que^ 𝑓(𝑋 = 75, 𝑌 = 0) ≠ 𝑓(𝑋 = 75)𝑓(𝑌 = 0) ⟺
1
7 50 ≠^
7 2500 que podemos buscar una recta de regresión (no está claro si se altera porque hay accidentes o si hay accidentes porque se altera, así que, en principio, cualquiera de las rectas de regresión sería válida). Recta de 𝑌 sobre 𝑋:
𝑦 − 0.98 =
(𝑥 − 89.5) ⟺ 𝑦 = 0.0164𝑥 − 0. que sustituyendo en la recta el valor de 𝑋 por 100, se obtiene para 𝑌 el valor 𝑦𝑥=100 = (0.0164)100 − 0.4883 = 1.1517, es decir, cuando ese trabajador tiene 100 pulsaciones es de esperar que en la línea de montaje haya 1.15 accidentes. que la fiabilidad de la predicción nos la da el coeficiente de correlación lineal, ya que hemos utilizado una recta para hacer la previsión. En este caso, el coeficiente de determinación,
𝑅^2 =⏞
𝑙𝑖𝑛𝑒𝑎𝑙 𝑟^2 = 𝑆𝑋𝑌^2 𝑆𝑋^2 𝑆𝑌^2 =^
(0.89)^2 (54.25)(0.2596) = 0.056^ con^ lo^ que^ la^ garantía^ que^ tenemos^ en^ esa predicción es mínima (5.6% de fiabilidad)
que la garantía al hacer una previsión para un valor alejado de los que hemos manejado en nuestra recogida de información no puede estudiarse, pues sólo podemos aceptar el modelo en valores próximos a los estudiados, pero nunca podemos garantizar si ese modelo es o no válido cuando nos alejamos de esos valores. Podemos intentar ver si una gráfica nos da información de esta relación.
Casos ponderados por FREC
X
70 80 90 100 110
Y
2,
1,
,
0, -,
Experimento aleatorio : aquel experimento del que no sabemos predecir el resultado concreto que obtendremos aunque lo repitamos siempre en las mismas condiciones.
Ejercicio 5 : lanzamiento de dos monedas
Espacio muestral : resultados posibles de un experimento aleatorio. Suele denotarse 𝐸 aunque en algunos libros se denota 𝒮 y en los más teóricos Ω.
Ejercicio 5 (cont.) : Si denotamos por 𝑐=”obtener cara” y por 𝑥=”obtener cruz” entonces 𝐸 = {(𝑐, 𝑐), (𝑐, 𝑥), (𝑥, 𝑐), (𝑥, 𝑥)} donde entendemos que el primer componente del par es el resultado del primer lanzamiento y el segundo componente del par es el resultado del segundo lanzamiento de la moneda.
Suceso : cualquier resultado del experimento que nos interese estudiar
Ejercicio 5 (cont.) : Podemos querer comprobar si se ha verificado 𝐴=”ha salido el mismo resultado en las dos monedas”={(𝑐, 𝑐), (𝑥, 𝑥)} o bien 𝐵=”ha salido cara en la primera moneda”={(𝑐, 𝑐), (𝑐, 𝑥)} o quizás 𝐶=”ha salido cara al menos una vez”={(𝑐, 𝑐), (𝑐, 𝑥), (𝑥, 𝑐)}, o cualquier otro resultado de interés.
Propiedades de los sucesos : son análogas a las de conjuntos, extendiéndose las operaciones de unión, intersección y paso al complementario de la misma forma que en la teoría de conjuntos.
Ejercicio 5 (cont.) : para los sucesos anteriores tenemos, Suceso unión de 𝑨 y 𝑩 es el que se verifica cuando se verifica al menos uno de los dos sucesos: 𝐴 ∪ 𝐵=”ha salido lo mismo en las dos o bien cara en la primera” ={(𝑐, 𝑐), (𝑐, 𝑥), (𝑥, 𝑥)} Suceso intersección de 𝑨 y 𝑩 es el que se verifica cuando se han verificado los dos sucesos: 𝑨 ∩ 𝑩 =”han salido las dos iguales y además cara en la primera” = {(𝒄, 𝒄)} Complementario de 𝑨 es el que se verifica cuando no se verifica el suceso de partida: 𝐴̅ = “ no han salido las dos iguales” = {(𝑐, 𝑥), (𝑥, 𝑐)}
Hay que tener en cuenta que la propiedad asociativa : 𝐴 ∪ (𝐵 ∪ 𝐶) = (𝐴 ∪ 𝐵) ∪ 𝐶 = 𝐴 ∪ 𝐵 ∪ 𝐶 A ∩ (B ∩ C) = (A ∩ B) ∩ C = 𝐴 ∩ 𝐵 ∩ 𝐶 la propiedad conmutativa : 𝐴 ∪ 𝐵 = 𝐵 ∪ 𝐴 𝐴 ∩ 𝐵 = 𝐵 ∩ 𝐴 la propiedad distributiva : 𝐴 ∩ (𝐵 ∪ 𝐶) = (𝐴 ∩ 𝐵) ∪ (𝐴 ∩ 𝐶) 𝐴 ∪ (𝐵 ∩ 𝐶) = (𝐴 ∪ 𝐵) ∩ (𝐴 ∪ 𝐶) así como las Leyes de De Morgan : 𝐴 ∩ 𝐵̅̅̅̅̅̅̅ = 𝐴̅ ∪ 𝐵̅ 𝐴 ∪ 𝐵̅̅̅̅̅̅̅ = 𝐴̅ ∩ 𝐵̅ son algunas de las propiedades de conjuntos que se aplican con frecuencia entre sucesos.
Probabilidad condicionada : Sabiendo que se ha verificado el suceso 𝐴 de probabilidad no nula, la incertidumbre sobre la verificación de otro suceso 𝐵 cambia al valor dado por la probabilidad de 𝐵 condicionada por 𝐴, es decir,
𝑃(𝐵 ⁄ ) = 𝐴
𝑃(𝐴 ∩ 𝐵) 𝑃(𝐴) Si esta incertidumbre no cambia ante el conocimiento “parcial” del experimento, entonces la información que hemos obtenido (en este caso el suceso 𝐴) será irrelevante para conocer la verificación o no del suceso de interés (en este caso 𝐵). Se dirá entonces que 𝐵 es independiente de
𝐴 y se verifica que 𝑃(𝐵 ⁄ ) = 𝑃(𝐵)𝐴.
Probabilidad total : Sea un sistema completo de sucesos , es decir, una familia {𝐴𝑖}𝑖=1𝑛^ de sucesos tales que son disjuntos dos a dos (𝐴𝑖 ∩ 𝐴𝑗 = ∅ ∀𝑖 ≠ 𝑗), con probabilidades no nulas (𝑃(𝐴𝑖) > 0) y su unión es el total (⋃ 𝑛𝑖=1 𝐴𝑖= 𝐸). Si suponemos conocidas las probabilidades de cualquier suceso
𝐵 condicionadas por los 𝐴𝑖, 𝑃 (𝐵 𝐴 ⁄ (^) 𝑖 ), la probabilidad de 𝐵 se obtiene como
𝑃(𝐵) = ∑ 𝑃 (𝐵 𝐴 𝑖 ⁄ ) 𝑃(𝐴𝑖)
𝑛
𝑖=
Teorema de Bayes : Dado un sistema completo de sucesos, y sabiendo que se ha verificado el suceso 𝐵, la probabilidad de 𝐴𝑖 condicionada por 𝐵 es
𝑃 (𝐴𝑖⁄ 𝐵 ) =
𝑃 (𝐵 𝐴 𝑖 ⁄ ) 𝑃(𝐴𝑖)
∑ 𝑃 (𝐵 𝐴 ⁄ (^) 𝑗 𝑛𝑗=1 ) 𝑃(𝐴𝑗)
Ejercicio 6 : Una alarma de incendios funciona el 90% de las veces que hay incendio y da avisos falsos el 15% de las veces que no los hay. Si la probabilidad de que haya un incendio es del 20%, ¿cuál es la probabilidad de que la alarma haya sonado? Si ha sonado, ¿cuál es la probabilidad de que realmente hubiera un incendio? Sean los sucesos 𝐴:”haber un incendio” y 𝐵:”sonar la alarma”. Nuestro sistema completo de sucesos es {𝐴, 𝐴̅}.
La información que tenemos en el enunciado es 𝑃(𝐵 ⁄ ) = 0.9𝐴 , 𝑃 (𝐵 ⁄ ) = 0.15𝐴̅ y 𝑃(𝐴) = 0. En el primer caso nos piden 𝑃(𝐵) que será 𝑃(𝐵) = 𝑃(𝐵 ⁄ ) 𝑃(𝐴) + 𝑃 (𝐴 𝐵 ⁄ ) 𝑃(𝐴̅) = (0.9)(0.2) + (0.15)(0.8) = 0.18 + 0.12 = 0.3𝐴̅ En el segundo caso nos dicen que la alarma ha sonado, por lo tanto se pide la probabilidad de 𝐴 condicionada por 𝐵
𝑃(𝐴 ⁄𝐵 ) =
𝑃(𝐵 ⁄ ) 𝑃(𝐴)𝐴
𝑃(𝐵 ⁄ ) 𝑃(𝐴) + 𝑃 (𝐴 𝐵 𝐴̅ ⁄ ) 𝑃(𝐴̅)
=
(0.9)(0.2)
= 0.
En este caso el saber que ha sonado la alarma (𝐵) modifica mi impresión sobre la presencia de incendio (𝐴) ya que pasa de tener un 20% de probabilidad a un 60%. Los sucesos 𝐴 y 𝐵 serán entonces dependientes.
Variable aleatoria : cuantificación de los resultados de un experimento. Queda caracterizada por los valores que toma y las probabilidades con que toma cada uno de esos valores. Pueden ser Discretas : si toma una cantidad finita o numerable de valores distintos Continuas : si toman valores al menos en un intervalo
Funciones asociadas : la probabilidad extiende el concepto de frecuencia relativa, por lo que en el caso de variables discretas el tratamiento será análogo al que hemos hecho hasta el momento. Tenemos que introducir una nueva función en el caso continuo. En el caso discreto, la probabilidad viene inducida por la propia variable aleatoria. Función de probabilidad : si la variable es discreta, puedo calcular la probabilidad de cualquier suceso en función de los valores de los que proviene, es decir, 𝑃(𝑋 ∈ 𝐴) = 𝑃{𝑥 ∈ 𝐸 𝑋(𝑥)⁄ ∈ 𝐴} 3. En algunos textos esto recibe el nombre de probabilidad inducida por la variable aleatoria. Función de densidad : se llama función de densidad a una función no negativa, 𝑓(𝑥) ≥ 0, que permite calcular la probabilidad de que una variable aleatoria continua tome valores en el intervalo [𝑎, 𝑏] como 𝑃(𝑎 ≤ 𝑋 ≤ 𝑏) = ∫ 𝑓(𝑥)𝑑𝑥 𝑏 𝑎. Obsérvese que esto permite obtener la probabilidad de cualquier suceso, en concreto la del suceso seguro, por lo que para que 𝑓(𝑥) sea función de densidad debe verificar, además, que (^) ∫ 𝑓(𝑥)𝑑𝑥 +∞ −∞ = 1. Función de distribución : tanto si la variable es discreta como continua, podemos definir la función de distribución, 𝐹(𝑥), que nos da la probabilidad acumulada, es decir, 𝐹(𝑥) = 𝑃(𝑋 ≤ 𝑥). En el caso discreto, se obtiene sumando las probabilidades de que la variable tome valores menores o iguales a 𝑥, es decir, 𝐹(𝑥) = ∑ 𝑃(𝑋 = 𝑥𝑖) 𝑥𝑖≤𝑥 y en el caso continuo integrando la función de densidad en (−∞, 𝑥], es decir,
𝐹(𝑥) = ∫ 𝑓(𝑡)𝑑𝑡
𝑥
−∞ Esperanza (o valor esperado ): generaliza la media, se denota 𝐸[^ ]^ y se define como 4 𝐸[ℎ(𝑋)] = ∑ ℎ(𝑥𝑖)𝑃(𝑋 = 𝑥𝑖) 𝑖
caso discreto
𝐸[ℎ(𝑋)] = ∫ ℎ(𝑥)𝑓(𝑥)𝑑𝑥
+∞
−∞
caso continuo
Por ejemplo, 𝐸[𝑋]^ = ∑^ 𝑖 𝑥𝑖𝑃(𝑋 = 𝑥𝑖) es la media de una v.a. discreta y 𝐸[𝑋^2 ]^ = ∫ 𝑥^2 𝑓(𝑥)𝑑𝑥
−∞ es la media de los cuadrados de una v.a. continua. Para una v.a. cualquiera se verifica la relación 𝑉𝑎𝑟(𝑋)^ = 𝐸[𝑋^2 ]^ − 𝐸[𝑋]^2 Función generatriz de momentos : tanto si la variable 𝑋 es discreta como continua, podemos definir su función generatriz de momentos, 𝑔𝑋(𝑡), en un número real no negativo 𝑡 como 𝑔𝑋(𝑡) = 𝐸[𝑒𝑡𝑋]
(^3) También se puede escribir 𝑃(𝑋 = 𝑥 4 𝑖) = 𝑃{𝑥 ∈ 𝐸 𝑋(𝑥)⁄^ = 𝑥𝑖^ }. Este operador generaliza cualquier operación con la variable aleatoria (es decir, se pueden calcular con él tanto la media, como la varianza, la media de los cuadrados, la media de los cubos, ….). Conviene observar que el resultado de esa operación no siempre existe (es decir, hay variables aleatorias que “no tienen” media, o varianza, o cualquier otro parámetro que la caracterice).
Variables aleatorias discretas : pensaremos en todo momento que lo único que me interesa es el éxito o fracaso de un suceso 𝐴, del que conozco su probabilidad 𝑝. Bernoulli : si realizo el experimento una vez, 𝑋=”número de éxitos de 𝐴 en una repetición del experimento“ sólo podrá tomar los valores 0 y 1. Además, la probabilidad con que toma el valor cero (es decir, hay fracaso para 𝐴) será 1 − 𝑃(𝐴), y la probabilidad con que toma el valor uno, es decir, éxito para 𝐴, será 𝑃(𝐴). La distribución de esta variable será entonces Valores posibles : 0, 1 Probabilidades asociadas : 𝑃(𝑋 = 0) = 1 − 𝑃(𝐴) ≡ 1 − 𝑝 ≡ 𝑞, 𝑃(𝑋 = 1) = 𝑃(𝐴) ≡ 𝑝 Medidas asociadas : media 𝑝 y varianza 𝑝(1 − 𝑝) Binomial se denota habitualmente 𝑩(𝒏, 𝒑): si repito el experimento anterior 𝑛 veces en las mismas condiciones (repeticiones independientes), la probabilidad de éxito permanecerá constante para todas ellas. Tendré entonces, para la variable 𝑋=“número de éxitos de 𝐴 en 𝑛 repeticiones independientes del experimento” Valores posibles: 0,1, … , n Probabilidades asociadas: P(X = k) = ( n k ) pk(1 − p)n−k^ para todo k Medidas asociadas : media 𝑛𝑝 y varianza 𝑛𝑝(1 − 𝑝) Poisson se denota habitualmente 𝓟(𝝀): aunque de origen distinto, la distribución de Poisson aparece asociada con sucesos raros (aquellos que tienen una probabilidad muy baja de verificarse en una unidad de tiempo, espacio o volumen). También mide el número de éxitos, 𝑋=“número de éxitos de 𝐴”, y viene caracterizada por Valores posibles: 0,1,2,3, … Probabilidades asociadas:
P(X = k) =
λk k!
e−λ Medidas asociadas : media 𝜆 y varianza 𝜆 Geométrica se denota habitualmente 𝑮(𝒑): interesa conocer cuántas veces tenemos que repetir el experimento hasta conseguir el primer éxito. 𝑿=“número de fracasos antes del primer éxito de 𝐴”, y viene caracterizada por Valores posibles: 0,1,2,3, … Probabilidades asociadas : 𝑃(𝑋 = 𝑘) = (1 − 𝑝)𝑘𝑝 Binomial negativa se denota 𝑩𝑵(𝒓, 𝒑): generalizando la anterior, nos interesa repetir el experimento hasta obtener el éxito 𝑟-ésimo. 𝑋= “número de fracasos antes del 𝑟-ésimo éxito de 𝐴”, y viene caracterizada por Valores posibles: 0,1,2,3, … Probabilidades asociadas: 𝑃(𝑋 = 𝑘) = ( 𝑘 + 𝑟 − 1 𝑘
) (1 − 𝑝)𝑘𝑝𝑟
Hipergeométrica se denota habitualmente 𝑯(𝑫, 𝑵, 𝒏): este modelo es ligeramente distinto, ya que se conoce toda la población (tamaño 𝑁), y cuántos elementos de la misma presentan (𝐷) la característica de interés. 𝑋=“número de éxitos de 𝐴 en 𝑛 realizaciones del experimento”, y viene caracterizada por Valores posibles : 0,1,2,3, … , n (con restricciones) Probabilidades asociadas:
𝑃(𝑋 = 𝑘) =
( 𝐷 𝑘 ) ( 𝑁 − 𝐷 𝑛 − 𝑘 )
( 𝑁 𝑛 )
Variables aleatorias continuas: en inferencia trabajaremos fundamentalmente con una distribución, la normal, y con las relacionadas con ella por el muestreo, aunque igual que ocurre con las variables discretas hay infinidad de modelos posibles.
Uniforme en un intervalo [𝒂, 𝒃] suele denotarse 𝓤[𝒂, 𝒃]: es aquella cuya función de densidad es constante en el intervalo y nula fuera de él. Se correspondería con la regla de Laplace que se utiliza para definir probabilidades en espacios muestrales finitos cuando no se conoce la distribución. Su función de densidad es
𝑓(𝑥) = {
1 𝑏 − 𝑎
𝑎 ≤ 𝑥 ≤ 𝑏 0 𝑥 ∉ [𝑎, 𝑏]
Normal(mu,sigma) : es así como se leería la expresión 𝑵(𝝁, 𝝈), forma en que se denota una variable aleatoria continua, que puede tomar cualquier valor real, que lo hace según la función de densidad
𝑓(𝑥) =
1 𝜎√2𝜋
𝑒 −(𝑥−𝜇)
2 2𝜎^2
y que tiene media 𝜇 y desviación típica 𝜎
Normal(cero,uno) se denota 𝑵(𝟎, 𝟏): es un caso particular de la anterior, cuando la media es cero y la desviación típica es uno. Esta es la que aparece tabulada, y cualquier otra variable con distribución normal puede transformarse en ella mediante el proceso llamado de tipificación :
si 𝑌 sigue distribución 𝑁(𝜇, 𝜎), entonces 𝑌−𝜇 𝜎 sigue distribución^ 𝑁(0,1)
Exponencial de parámetro 𝝀, se denota 𝑬𝒙𝒑(𝝀), está relacionada con la Poisson y nos mide el tiempo que transcurre entre dos éxitos consecutivos. Su función de densidad es
𝑓(𝑥) = {𝜆𝑒
−𝜆𝑥 (^) 𝑥 > 0 0 𝑥 ≤ 0 Tiene por media el valor 1 𝜆 y por varianza^
1 𝜆^2.
Gamma (𝒑, 𝒂) se denota 𝜸(𝒑, 𝒂), con ambos parámetros no negativos. Es una generalización de la anterior 5 , y tiene por función de densidad
𝑓(𝑥) = {
𝑎𝑝 𝛤(𝑝)
𝑒−𝑎𝑥𝑥𝑝−1^ 𝑥 > 0
0 𝑥 ≤ 0 donde Γ(𝑝) = ∫ 𝑒−𝑥𝑥𝑝−1𝑑𝑥 ∞ 0 es la función gamma de Euler. Su media es^
𝑝 𝑎 y su varianza^
𝑝 𝑎^2.
Beta(p,q) , con ambos parámetros no negativos, está asociada a proporciones y tiene a la uniforme en el intervalo (0,1) como caso particular. Su función de densidad es
𝑓(𝑥) = {
𝑥𝑝−1(1 − 𝑥)𝑞− 𝛽(𝑝, 𝑞)
𝑥 ∈ [0,1]
0 𝑥 ∉ [0,1] donde 𝛽(𝑝, 𝑞) se conoce como función beta y se calcula a partir de la función gamma de Euler como 𝛽(𝑝, 𝑞) = Γ(𝑝)Γ(𝑞) Γ(𝑝+𝑞)^.
(^5) La distribución exponencial es un caso particular de la gamma (𝑝 = 1, 𝑎 = 𝜆).