¡Descarga datos y más Apuntes en PDF de Psicología solo en Docsity!
PARTE 2: COMPARACIONES DE MEDIAS EN DISEÑOS
UNIVARIABLES
DISEÑOS UNIVARIABLES ENTREGRUPOS
- Diseños entregrupos univariables bicondicionales Índice de contenido
- 1.1. Prueba t de Student para muestras independientes
- 1.2. ANOVA de un factor y F de Snedecor
- 1.3. Redacción de resultados
- 1.4. Alternativas de análisis
- Diseños entregrupos univariables multicondicionales
- 2.1. Estrategias de análisis adecuadas en función del tipo de hipótesis
- 2.2. Incremento del riesgo de error tipo I
- 2.3. Validación de hipótesis generales.............................................................
- 2.3.1. Redacción de resultados
- 2.4. Validación de hipótesis específicas
- 2.4.1. Coeficientes
- 2.4.2. Contrastes a priori (ANOVA de un factor)
- 2.4.3. Contrastes a priori (MLG: Univariante)
- 2.4.4. Aplicación de la corrección de Bonferroni
- 2.4.5. Redacción de resultados
- 2.5. Supuesto de homocedasticidad y alternativas de análisis.........................
- 2.6. Supuesto de normalidad y alternativas de análisis....................................
- Referencias
DISEÑOS UNIVARIABLES ENTREGRUPOS
En las investigaciones denominadas entregrupos los distintos niveles de la VI se estudian en grupos diferentes de sujetos, aunque estos grupos diferentes pueden haberse conformado de diversas formas. Así, en la investigación experimental se utiliza el principio del azar para asignar los sujetos a los distintos grupos del estudio. En cambio, en la investigación cuasi-experimental los grupos se encuentran formados previamente en función de algún criterio no probabilístico o desconocido. Finalmente, en los estudios correlacionales selectivos los grupos se forman seleccionando sujetos que posean determinadas características. Pues bien, dichos grupos deben ser lo más similares posibles, de forma que la única diferencia entre ellos sea el nivel de la VI. Sólo así se evitará la confusión entre las variaciones atribuibles a la VI y a las características individuales de los sujetos que componen cada muestra. Sin embargo, esta ausencia de confusión sólo puede garantizarse probabilísticamente en los diseños experimentales, gracias a la utilización de la técnica de control de la aleatorización. En el resto, las posibles confusiones dependerán de las VVEE implicadas en el estudio y su relación con la VI, por lo que se requiere una evaluación pormenorizada de cada estudio particular. Supongamos, por ejemplo, que utilizamos como VI el sexo y seleccionamos a un grupo de mujeres y otro de hombres para evaluar su grado de desempeño en una tarea probabilística con el tema de los deportes como contexto. Es posible que encontremos diferencias estadísticamente significativas entre sexos y a favor de los hombres. El problema será la interpretación de tales resultados. Así, debemos tener en cuenta que el hecho de ser hombre o mujer correlaciona, entre otras cuestiones, con aspectos educativos y preferencias, por lo que no podremos determinar a qué se deben las diferencias encontradas. En otros tiempos se recurriría sin duda al sexo biológico para explicar tales diferencias y seguir perpetuándolas, pero está claro que también pueden deberse a diferencias educativas en cuanto a la enseñanza de los conceptos probabilísticos o a las preferencias por los temas deportivos, que a su vez podrían venir determinadas por la mayor exclusión de las mujeres del ámbito deportivo. En cualquier caso, en términos estadísticos se hace referencia a las puntuaciones proporcionadas por estos diferentes grupos de sujetos como muestras independientes. Y los análisis estadísticos correspondientes serán los mismos con independencia de la metodología, experimental, cuasi-experimental o selectiva, utilizada. Las principales diferencias estarán en el tipo de explicación que se pueda dar a los resultados obtenidos, reservando las explicaciones causales para el diseño experimental. Sí deberemos tener en cuenta en cambio el número de variables, sus escalas de medida, el número de grupos o muestras independientes y, como siempre, el grado de cumplimiento de los supuestos estadísticos de cada prueba. En cuanto a la VD, sólo incluiremos en este curso técnicas univariadas (una única VD) y VVDD medidas cuantitativamente. Este tipo de escalamiento es preferido en muchas áreas de investigación debido a que proporciona mayor cantidad de información sobre las diferencias entre unos sujetos y otros. Como consecuencia, las técnicas de análisis apropiadas para este tipo de VVDD han sido las más desarrolladas, conocidas y utilizadas, principalmente la regresión lineal (RL) y los modelos de ANOVA. En cuanto a la VI, comenzaremos por los diseños univariables (una VI) con variables predictoras categóricas. Englobamos en este grupo los casos en que la escala de medida es cualitativa, por ejemplo el sexo, cuantitativa categorizada o segmentada convencionalmente, por ejemplo, de 4 a 8 y de 10 a 14 años, e incluso cuantitativa con unos pocos valores discretos elegidos previamente por el investigador/a, por ejemplo 2, 4 y 6 tazas de cafeína. En condiciones de cumplimiento de los supuestos, las técnicas de análisis estadístico más utilizadas en este tipo de diseños son la t de Student (cuando sólo se comparan dos grupos) y el ANOVA de un factor con su correspondiente prueba F de Snedecor (cuando se comparan simultáneamente dos o más grupos). Sin embargo, debemos tener en cuenta que el ANOVA no es más que una concreción particular del modelo de RL, por lo que también podría aplicarse dicha
DISEÑOS UNIVARIABLES ENTREGRUPOS
cualquiera, por ejemplo el 1 para el grupo a 1 (primeras filas) y el 2 para el grupo a 2 (últimas filas). Aunque utilicemos códigos numéricos, siempre debemos tener presente que no se trata en realidad de una variable cuantitativa, por lo que nunca tendrá sentido calcular su media, su desviación tipo…; los cálculos se realizarán siempre sobre los datos de la VD. Por último, para facilitar la interpretación de los resultados, es conveniente indicar (en Vista de Variables: Valores) qué significan dichos códigos numéricos, de forma que podamos localizar fácilmente qué cálculos corresponden a los sujetos de las primeras filas (Valor 1 = Etiqueta “primeras filas”) y cuáles a los de las últimas (Valor 2 = Etiqueta “últimas filas”). El archivo en cuestión podría tener el siguiente aspecto (la vista de la derecha es el resultado de activar las etiquetas de valores en la barra de iconos):
vi vd vi vd 1 6 primeras filas 6 1 7 primeras filas 7 1 4 primeras filas 4 1 8 primeras filas 8 1 5 primeras filas 5 1 9 primeras filas 9 1 3 primeras filas 3 1 7 primeras filas 7 1 6 primeras filas 6 1 5 primeras filas 5 2 4 últimas filas 4 2 5 últimas filas 5 2 6 últimas filas 6 2 7 últimas filas 7 2 4 últimas filas 4 2 7 últimas filas 7 2 1 últimas filas 1 2 3 últimas filas 3 2 2 últimas filas 2 2 1 últimas filas 1
1.1. Prueba t de Student para muestras independientes Con el comando Analizar: Comparar medias: Prueba T para muestras independientes podemos obtener la prueba t de Student para muestras independientes, es decir para diseños entregrupos. Para ejecutarlo es necesario definir cuál es la variable a contrastar o VD (nota) y cuál es la variable de agrupación o VI (posición), especificando además los códigos numéricos utilizados para Definir los grupos... o condiciones experimentales. El análisis solicitado en nuestro ejemplo sería el siguiente:
DISEÑOS UNIVARIABLES ENTREGRUPOS
Con esta definición de los grupos le estamos indicando al procesador que le reste a la media del Grupo 1 la media del Grupo 2. Una vez definidos los grupos, podemos Aceptar el análisis solicitado. Aunque habitualmente conviene visitar antes el menú de Opciones , en el caso de la prueba t dicho menú únicamente permite modificar el intervalo de confianza, que convencionalmente suele mantenerse en el 95%, y lo que debe hacerse con los valores perdidos, bien excluir los casos con valores perdidos en la variable que se vaya a contrastar ( Excluir casos según análisis ), bien los casos con valores perdidos en cualquiera de las variables del archivo ( Excluir casos según lista ). Las tablas de resultados proporcionados por SPSS se reproducen a continuación. En primer lugar nos encontramos algunos estadísticos descriptivos de cada grupo:
En esta tabla aparece el número de datos de cada grupo o muestra independiente ( N = 10, aunque sería más correcto utilizar para ello el símbolo n minúscula); la media de las puntuaciones de cada grupo:
sus desviaciones típicas:
y el error típico de la media:
DISEÑOS UNIVARIABLES ENTREGRUPOS
supuesto, aunque en ocasiones podemos encontrar incluso niveles superiores, por ejemplo .10. La cuestión es que en este tipo de pruebas de hipótesis nula, de comprobación de supuestos, lo que nos interesa es aceptar H 0 , para poder utilizar las pruebas paramétricas convencionales. Por tanto, debemos protegernos respecto a los errores tipo II. Para conseguir que el riesgo de error tipo II sea bajo, seleccionamos riesgos de error tipo I altos. En nuestro ejemplo, puesto que .449 > .05, aceptamos H 0 y concluimos que el azar es una explicación plausible de las diferencias entre las varianzas del error de ambos grupos. De acuerdo con los resultados de esta prueba de comprobación de supuestos, elegiríamos la prueba paramétrica clásica t de Student como la alternativa de análisis más adecuada para comparar la nota media de ambos grupos. En caso contrario, si se incumpliera el supuesto de homocedasticidad, sería preferible la prueba heterocedástica de Welch. SPSS aporta ambas pruebas, t de Student, con N -2 = 20-2 = 18 grados de libertad en la fila superior de la tabla (se han asumido varianzas iguales), y t de Welch en la inferior (no se han asumido varianzas iguales). La definición técnica de estos grados de libertad corresponde con el número de observaciones independientes utilizadas para realizar los cálculos oportunos. Muy brevemente, puesto que se calculan distancias a una media, y éstas deben sumar cero, es posible predecir algunas de las distancias conociendo otras, de forma que no todas ellas son independientes. Pero en cualquier caso, la cuestión es que están relacionados con las condiciones de número de sujetos y grupos de la investigación, y por tanto, con la representatividad de la muestra respecto a la población. En este sentido, recordemos que existe una estrecha relación entre la significación estadística, el tamaño del efecto y el tamaño muestral, determinante del número de grados de libertad. Como puede observarse, el valor empírico de estos estadísticos es el mismo, en ambos casos, positivo debido a que la diferencia de medias analizada también lo es, 6-4 = 2 (en la definición de grupos especificamos como grupo 1 al que tiene una media de 6 y como grupo 2 al que tiene una media de 4). Estos estadísticos resultan de dividir la diferencia de medias, 2, entre el error típico de la diferencia de medias:
La prueba t de la fila inferior corresponde al procedimiento de Welch para corregir los grados de libertad del error de acuerdo con el grado de heterogeneidad encontrado entre las varianzas (pueden encontrarse pequeñas variaciones en función de los decimales utilizados en el cálculo):
En nuestro ejemplo, existe muy poca diferencia entre los grados de libertad utilizados por una y otra prueba, debido a que existe muy poca diferencia entre las varianzas de error de uno y otro grupo. Como consecuencia, la significación de ambas pruebas es muy similar. La conclusión estadística en un contraste de dos colas (indicado en la tabla como significación bilateral) sería el rechazo de H 0 con α = .05 ( p = .043 < .05) y la aceptación de H 0 con α = .01 ( p = .043 > .01). Lógicamente, la elección de un determinado nivel de significación debe hacerse a priori y en función de lo que resulte más habitual en cada área de investigación. Por su parte, para desarrollar un contraste de una cola, en caso de contar con una hipótesis unidireccional (por ejemplo, el rendimiento de los sujetos que se sientan en las
DISEÑOS UNIVARIABLES ENTREGRUPOS
primeras filas será superior al de los sujetos que se sientan en las últimas), bastaría con dividir entre 2 dicha significación, p (una cola) = .043/2 = .0215, y comparar dicho valor con el nivel α previamente fijado. Así por ejemplo, rechazaríamos H 0 con un contraste de una cola y α = .05, ya que .0215 es inferior a .05. Por último, SPSS aporta el intervalo de confianza del 95% alrededor de la diferencia de las medias observadas:
donde tα es el valor teórico de la distribución t de Student para el nivel de significación determinado y los grados de libertad del error. En nuestro ejemplo, para α = .05 y 18 grados de libertad del error, t = 2.101, de forma que:
Este intervalo de confianza nos da una idea de la precisión de la diferencia de medias muestral como estimador de la diferencia de medias poblacional. A medida que aumenta el tamaño del intervalo de confianza, disminuye la precisión de la estimación. Con los datos de nuestro ejemplo, para tener un 95% de confianza en que el parámetro diferencia de medias está contenido en el intervalo, tenemos que situar los límites de éste entre 3.93 y .07, de forma que sólo podemos afirmar que la diferencia de medias poblacional es igual o superior a .07 e igual o inferior a 3.93. Aunque los intervalos de confianza y las pruebas de significación de hipótesis nula dependen ambos en último término de α y utilizan la misma información, estimadores de parámetros y error típico, los intervalos de confianza aportan información adicional, lo que permitirá una interpretación más precisa de los resultados de un experimento. Esta información adicional resulta útil para conocer la magnitud del efecto encontrado y es especialmente valiosa en los casos de aceptación de la hipótesis nula (Aron y Aron, 1999; Frick, 1995), aunque no es frecuente que aparezca en los informes de investigación. Supongamos por ejemplo dos casos de aceptación de la hipótesis nula en la comparación de un promedio de 10 con otro de 14 (14-10 = 4), el primero con un intervalo de confianza pequeño alrededor de la diferencia de medias encontrada, [3-5], y el segundo con uno más amplio, [0-8]. En este segundo caso tendríamos resultados menos concluyentes, ya que es posible que el efecto no exista en realidad, tal y como indica la prueba de hipótesis, pero también es posible que no se haya detectado como significativo un efecto sustancial de hasta 8 puntos de diferencia entre ambas medias. Finalmente, es necesario destacar la ausencia de índices de tamaño del efecto en los resultados proporcionados por SPSS a través de este comando. Para obtenerlos será necesario recurrir al cálculo manual o a algún calculador en la Web. Así por ejemplo, con tamaño muestral constante puede calcularse el índice d a partir de la fórmula:
Comprobamos así que se trata de un tamaño de efecto grande (igual o superior a .80). Puesto que tanto la significación estadística (se rechaza H 0 ) como el tamaño de efecto encontrado (grande) apuntan hacia la existencia de diferencias entre los grupos, concluiríamos que probablemente el efecto es importante y existe en la realidad. También contamos con datos suficientes para calcular el índice de tamaño de efecto R^2 :
DISEÑOS UNIVARIABLES ENTREGRUPOS
Como puede comprobarse, SPSS ofrece un descriptivo algo más amplio a través de este comando, incluyendo también los estadísticos correspondientes al total de la muestra experimental ( N = 20). Por otro lado, también proporciona algunos estadísticos adicionales, como los valores mínimos y máximos de cada grupo e intervalos de confianza del 95% alrededor de cada media:
donde puede estimarse de forma común a ambos grupos como:
Aplicando dicha fórmula obtendríamos, por ejemplo, los siguientes límites inferior y superior para el grupo de las primeras filas ( j = 1):
El interés de estos intervalos de confianza es comprobar el rango de valores que habrían dado lugar a la aceptación de la hipótesis nula y cuán alejado están nuestros valores empíricos de dicho rango. Tomemos por ejemplo el intervalo calculado alrededor de la media (6) de los sujetos que se sentaron en las primeras filas, que oscila entre 4.63 y 7.37. La media del otro grupo (4) no está incluida en dicho intervalo, de ahí el rechazo de la hipótesis nula con un nivel de significación de .05, pero tampoco es un valor muy alejado del intervalo (recordemos que con un nivel de significación menor, .01, se aceptaba la H 0 ). SPSS nos proporciona a continuación la prueba F de Levene para comprobar la homogeneidad de las varianzas del error:
Y una vez comprobado el supuesto de homocedasticidad, nos ofrece el cuadro de Análisis de la Varianza convencional, con su correspondiente F de Snedecor, y la prueba F de Welch, más adecuada en caso de que no se cumpliese la homocedasticidad:
DISEÑOS UNIVARIABLES ENTREGRUPOS
Los datos aportados en el cuadro de ANOVA son fáciles de entender. En la primera columna del cuadro de Análisis de la Varianza se establecen las fuentes de variación propias de cada diseño. En los diseños entregrupos univariables bicondicionales contamos con una parte de variación entre los grupos (inter-grupos) de la que sería supuestamente responsable la VI, ya que a cada grupo le corresponde un nivel de la VI distinto. Contamos, por otro lado, con una porción de variación provocada por las características personales de los sujetos dentro de cada grupo (intra-grupos), responsable de que los distintos sujetos de un mismo grupo obtengan diferentes puntuaciones a pesar de haber recibido el mismo nivel de VI. A continuación se calculan las sumas cuadráticas ( SSCC ) correspondientes a cada fuente de variación. Se trata de una medida de variación basada en la suma de las distancias cuadráticas a la media, de forma que las puntuaciones cercanas a ésta aportan poca cantidad de variación, mientras que las muy alejadas provocan un incremento importante de la misma y hacen la estimación menos precisa. La diferencia entre ellas radica en el tipo de variación analizada en cada caso. Así, para la variación entregrupos se utilizan las distancias entre la media de cada grupo y la media total; para la variación intragrupos se suman las distancias al cuadrado entre cada puntuación individual y la media de su grupo; y para la total se usan las distancias entre cada puntuación individual y la media total. Como puede observarse, la SC total no es más que la suma de las SSCC entre e intragrupos (96 = 20 +76). El siguiente paso en el desarrollo de un ANOVA consiste en calcular los grados de libertad ( gl ) correspondientes a cada fuente de variación:
Como puede observarse, los grados de libertad totales no son más que la suma de los grados de libertad entre e intragrupos (19 = 1 + 18). A continuación se estiman los cuadrados medios ( CM ) medias cuadráticas o varianzas^1. Para obtenerlas bastará con dividir las SSCC entre sus correspondientes gl :
Por último, se comparan ambas varianzas a través del cociente F de Snedecor:
(^1) Puesto que para estimar las varianzas poblacionales estamos utilizando en el denominador
no el número de observaciones, sino los grados de libertad, estamos trabajando en realidad con las cuasi-varianzas muestrales, estimadores insesgados de las varianzas poblacionales.
DISEÑOS UNIVARIABLES ENTREGRUPOS
También será necesario solicitar algunos otros datos de interés en el menú de Opciones :
Obtendríamos así las siguientes tablas de resultados:
DISEÑOS UNIVARIABLES ENTREGRUPOS
Como puede observarse, el análisis descriptivo obtenido es más simple que en los comandos anteriores, aunque también podríamos haber obtenido intervalos de confianza alrededor de cada media seleccionando Mostrar las medias para: posición en el menú de Opciones :
En este caso, el cálculo proporcionado, por ejemplo para el grupo que se sentó en las primeras filas, j = 1, es mucho más similar al obtenido manualmente que en el comando anterior:
El resto de las tablas proporcionadas corresponden a la prueba de Levene y al cuadro de ANOVA:
DISEÑOS UNIVARIABLES ENTREGRUPOS
En cambio, su principal desventaja respecto a los comandos anteriores es no proporcionar una alternativa de análisis heterocedástica utilizable en caso de incumplimiento del supuesto de homocedasticidad.
1.3. Redacción de resultados
A continuación se presentan algunas posibles redacciones de los resultados obtenidos en un informe de investigación (α = .05), dependiendo de que se decida utilizar una prueba t de Student o F del ANOVA y de que se decida desarrollar un contraste de una o dos colas:
“Se encontraron diferencias estadísticamente significativas entre el grupo que se sentó en las primeras filas ( M = 6, DT = 1.83) y el que se sentó en las últimas ( M = 4, DT = 2.26), F (1,18) = 4.74, p = .043, R^2 = .21.”
“Los sujetos que se sentaron en las primeras filas ( M = 6, DT = 1.83) obtuvieron una nota significativamente superior a la de los sujetos que se sentaron en las últimas filas ( M = 4, DT = 2.26), t (18) = 2.18, p (una cola) = .022, R^2 = .21.”
Como puede comprobarse, esta redacción de resultados presenta las siguientes características de acuerdo con las recomendaciones de la APA (2001, 2009):
Aporta datos descriptivos de los grupos. En nuestro caso, cada vez que se nombra a un grupo diferente, se aportan entre paréntesis su media y su desviación tipo. Sin embargo, cuando van a redactarse resultados sobre un mayor número de comparaciones, ello puede provocar que la lectura se vuelva demasiado engorrosa. Para evitarlo, en ocasiones se extraen estos datos descriptivos en una tabla a la que se hace referencia en la redacción:
“Los sujetos que se sentaron en las primeras filas obtuvieron una nota significativamente superior a la de los sujetos que se sentaron en las últimas filas, t (18) = 2.18, p (una cola) = .022, R^2 = .21 (ver Tabla 1).”
Indica la prueba estadística utilizada, su valor empírico y los grados de libertad de la misma entre paréntesis. Como puede comprobarse, en el caso de la t de Student, sólo se indican los gl del error, ya que los del numerados siempre son 2- = 1. En cambio, con la prueba F es necesario aportar los gl tanto del denominador (error) como del numerador, ya que puede aplicarse con cualquier número de grupos. Aporta el valor de significación o probabilidad empírico, .022, indicando explícitamente que se ha desarrollado un contraste de una cola si es el caso; si no se indica nada al respecto se entenderá que es de dos colas.
Aporta alguna medida de tamaño de efecto, en nuestro caso R^2. En nuestro ejemplo, puesto que tanto la significación como el tamaño de efecto indicaban la existencia de diferencias en la población, no es necesario resaltar nada en especial. Sin embargo, en caso de que hubiese una contradicción entre los índices debería resaltarse en la redacción de resultados. Por ejemplo, suponiendo significación estadística y tamaño de efecto pequeño, podríamos redactar los resultados como sigue:
“Aunque el tamaño de efecto encontrado resultó pequeño, R^2 = .05, la diferencia entre ambos grupos resultó significativa...”
DISEÑOS UNIVARIABLES ENTREGRUPOS
Finalmente, también existen algunas recomendaciones más formales: o Redondear todos los datos a dos decimales, excepto las probabilidades, que deben tener al menos 3. o Sustituir las comas por puntos para separar las posiciones decimales. o No escribir nunca el valor 0 delante del punto (.05 en vez de 0.05).
En los ejemplos anteriores de redacción de resultados nos hemos circunscrito exclusivamente a los datos específicos de una prueba de significación. No obstante, el apartado de resultados de un informe de investigación contendrá muy probablemente resultados de diversas pruebas y debería hacer referencia previamente a otros aspectos generales del análisis desarrollado, como la comprobación de supuestos, el tipo de contrastes… Por ejemplo:
“Se utilizó un nivel de significación de .05 para cada prueba de hipótesis realizada, desarrollando contrastes de una cola en el caso de las hipótesis unidireccionales. Previamente, se contrastó el cumplimiento del supuesto de homocedasticidad mediante la prueba F de Levene, optando por la prueba heterocedástica de Welch frente al ANOVA en caso de incumplimiento del mismo.”
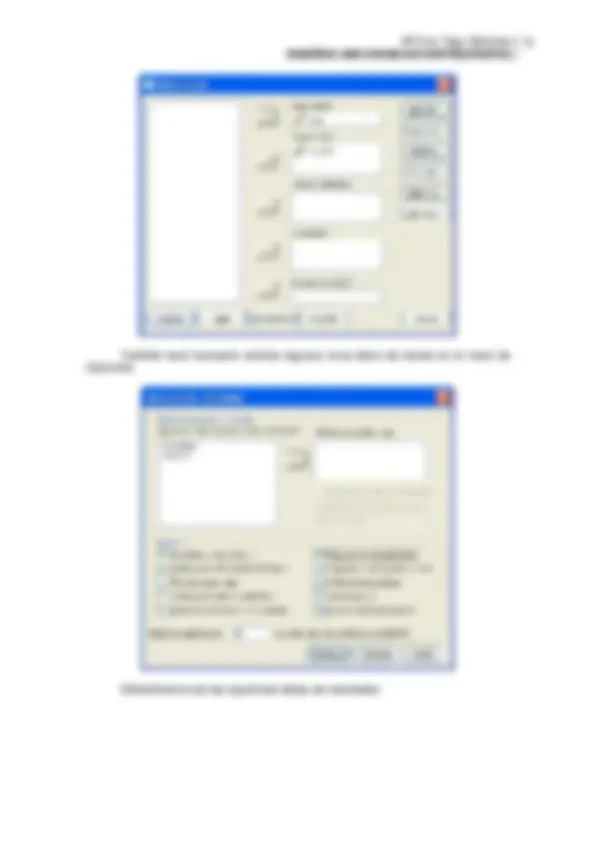
1.4. Alternativas de análisis Como hemos podido comprobar en el apartado anterior, los comandos Analizar: Comparar medias: Prueba T para muestras independientes y ANOVA de un factor nos permiten obtener una alternativa de análisis heterocedástica, las pruebas t o F de Welch para aquellos casos en que no se cumple el supuesto de homogeneidad de las varianzas del error. Por su parte, la prueba no paramétrica U de Mann-Whitney sería más recomendable por su mayor potencia cuando no se cumple el supuesto de normalidad. En SPSS podemos obtenerla a través del comando Analizar: Pruebas no paramétricas: Cuadros de diálogo antiguos: 2 muestras independientes , que nos mostraría el siguiente cuadro de diálogo:
Los resultados obtenidos serían los siguientes:
DISEÑOS UNIVARIABLES ENTREGRUPOS
2.2. Incremento del riesgo de error tipo I Siempre que se realizan comparaciones múltiples, ya sean a priori o a posteriori, sobre un mismo conjunto de datos, será necesario tener en cuenta el incremento del riesgo de error tipo I. En este sentido, hay que distinguir entre la tasa de error tipo I por contraste (per comparison = PC ) y por conjunto o familia de contrastes (familywise = FW ). Cuando se realizan c contrastes con un determinado riesgo de error tipo I en cada contraste, α, el riesgo de error tipo I para el conjunto de contrastes realizados no es igual a α, sino que se aproxima, aunque sobreestimado, como:
Así por ejemplo, si se realizaran 3 comparaciones distintas sobre los mismos datos con un riesgo de error tipo I por contraste de .05, el error tipo I para la familia de contrastes se iría incrementando aproximadamente así:
Comparaciones C1 .05. C2 .05 .052 =. C3 .05 .053 =.
Aunque el incremento del riesgo de error tipo I se produce independientemente de que las comparaciones sean a priori o a posteriori, la mayoría de los autores trata de forma muy diferente el problema en función del tipo de hipótesis que vayan a contrastarse. Así, suelen coincidir en que la tasa de error importante cuando se desarrollan unas pocas comparaciones planificadas a priori, en función del marco empírico-teórico previo, es la tasa de error por contraste, y se permite por ello no corregir el nivel α en dicha situación (e.g. Keppel, 1991; Keppel y Zedeck, 1989; Kirk, 1995). Como límite se impone que el número de comparaciones realizada no exceda el número de grupos independientes menos 1 (a-1). Recomendar lo contrario sería como recomendar la corrección del nivel α de diferentes investigaciones sobre un mismo tema y conllevaría una gran falta de potencia. No obstante, hay autores que optan por una protección del riesgo de error incluso en estas situaciones (e.g. Maxwell y Delaney, 1990). Por otro lado, también existe un acuerdo mayoritario en el extremo opuesto, es decir, cuando se realizan más comparaciones del límite marcado por a-1, será necesario aplicar algún tipo de corrección. Todos los procedimientos de corrección se basan en el aplicado por Dunn (1961) de acuerdo con la desigualdad de Bonferroni:
Este consiste en fijar el riesgo de error tipo I por familia de contrastes que se está dispuesto a asumir y utilizar como nuevo α por contraste el derivado de la expresión:
Otra alternativa para realizar la misma corrección consistiría en mantener constante el nivel α y multiplicar la probabilidad obtenida por el número de contrastes realizados. En definitiva, si no queremos que se produzca un incremento de la tasa de error tipo I por familia de contrastes, tendremos que utilizar un riesgo de error tipo I por contraste menor o una probabilidad por contraste mayor. Así, si fijamos la tasa de error tipo I por familia de contrastes que estamos dispuestos a sumir en .05 para las tres comparaciones de nuestro ejemplo, obtendríamos la siguiente corrección:
DISEÑOS UNIVARIABLES ENTREGRUPOS
que daría lugar a la siguiente tasa de error tipo I aproximada para la familia de tres comparaciones realizadas:
Comparaciones C1 .017. C2 .017 .0172 =. C3 .017 .0173 =.
Los distintos autores difieren, sin embargo, en aspectos concretos de la aplicación de este procedimiento. Así, mientras que para la mayoría el riesgo de error tipo I por familia de contrastes debe mantenerse en los niveles α convencionales, .05 ó .01, para otros como Keppel y Zedeck (1989) debe fijarse en α(a–1), es decir, .05(a-1) ó .01(a-1). Maxwell y Delaney (1990) y Myers y Well (1995) resaltan además la posibilidad de utilizar niveles diferentes para cada comparación en función de la importancia a priori de la misma, siempre que su suma no supere el previamente fijado.
2.3. Validación de hipótesis generales Supongamos una investigación sobre Psicología del Deporte realizada para estudiar si existe relación entre el tiempo de reacción de atletas principiantes y el tipo de retroalimentación recibido sobre dicho tiempo de reacción^2. El entrenamiento con cada tipo de retroalimentación se realizó a través de 60 salidas de los tacos en una pista de atletismo, asignándose aleatoriamente 6 sujetos a cada tratamiento experimental. Los distintos tipos de entrenamientos fueron: sin retroalimentación alguna (a 1 : 0%); con retroalimentación continua (a 2 : 100%); con disminución progresiva de la retroalimentación a través de los distintos ensayos, con un 50% de ensayos retroalimentados como promedio (a 3 : progresiva 50%); y con retroalimentación autorregulada por el/la propio/a atleta (a 4 : autorregulada). Posteriormente se realizó una prueba de 12 ensayos sin retroalimentación, registrándose el tiempo de reacción en milisegundos mediante células fotoeléctricas situadas en los tacos de salida. Estaríamos ante un diseño entregrupos, ya que contamos con grupos diferentes de sujetos para cada nivel de VI; univariable, ya que contamos con el tipo de retroalimentación como única VI; multicondicional, ya que dicha VI presenta 4 valores diferentes; y experimental, ya que la VI ha sido manipulada y se ha utilizado la aleatorización para asignar los sujetos a las condiciones de la misma. No obstante, recordemos que el tipo de análisis será independiente de que la investigación sea o no experimental, dependiendo exclusivamente del número de variables y de valores de éstas. A continuación se muestran unos posibles datos de esta investigación:
a 1 : 0% a 2 : 100% a 3 : progresiva 50% a 4 : autorregulada 385 387 393 375 369 383
M 382 373 358 371 371
En SPSS podemos conseguir el análisis de una hipótesis general como la planteada en nuestro ejemplo a través del comando Analizar: Comparar medias: ANOVA de un factor. Al igual que en los diseños bicondicionales, recordemos que el cuadro de Opciones nos permitirá solicitar un análisis descriptivo de los distintos
(^2) El tema de investigación está basado en Zubiaur, Oña, y Delgado (1998).