¡Descarga Modelos de Regresión Lineal: Aprenda a Resolver Ejercicios y Problemas Estadísticos y más Apuntes en PDF de Estadística Aplicada solo en Docsity!
IACC
Todos los derechos de autor son de la exclusiva propiedad de IACC o de los otorgantes de sus licencias. No está permitido copiar, reproducir, reeditar, descargar, publicar, emitir, difundir, poner a disposición del público ni utilizar los contenidos para fines comerciales de ninguna clase.
Regresión lineal
SEMANA 6
ESTADÍSTICA
IACC
APRENDIZAJES ESPERADOS
El estudiante será capaz de resolver ejercicios y problemas estadísticos, empleando modelos de regresión lineal.
IACC
INTRODUCCIÓN
Uno de los principales objetivos de la estadística es el de predecir el valor de una variable conociendo el valor de otra con el fin de establecer una relación de dependencia entre ellas.
Así, se podría pensar que, si hay una línea o curva en torno a la cual se agrupan los puntos de un diagrama (de dispersión), esta ha de ser un valor cercano, una aproximación de los valores reales. En esta semana se
estudiará el análisis que permite aproximar los datos en un diagrama de dispersión, llamado modelos de regresión.
Existen varios modelos de regresión, dependiendo de la forma que se adquieren los datos dispersos en un diagrama de puntos. Se pueden encontrar modelos de regresión lineal, exponencial y logarítmico, entre otros.
IACC
- MODELOS DE REGRESIÓN LINEAL SIMPLE
El modelo de regresión lineal simple consiste en aproximar los valores de una variable ( Y : variable dependiente) a partir de los de otra ( X : variable independiente), usando una relación funcional de tipo lineal, es decir, se busca cantidades a y b determinadas por:
Y ˆ a b x
Donde los factores no controlados que se consideran bajo el nombre de error aleatorio , ε. Este factor provoca que la dependencia entre las variables dependiente (Y) e independiente (X) no sea exacta y perfecta, si no que esté sujeta a la incertidumbre, es decir, idealmente tenga el menor error posible (o en su defecto que tienda a cero).
Para determinar los coeficientes (cantidades) de a y b del modelo, se debe minimizar la suma de
los cuadrados de la diferencia entre Y e Y ˆ. Debido a este proceso, este método de regresión es
llamado método de los mínimos cuadrados.
Desde el punto de vista estadístico, los modelos de regresión son curvas que minimizan el error. En este sentido, se denomina error a la distancia que existe entre el dato observado y el dato pronosticado por el modelo de regresión.
Las cantidades a y b que minimizan dicho error son los llamados coeficientes de regresión :
a Y b X
2 X
XY
S
S
b
Donde el coeficiente a es llamado ordenada en el origen o coeficiente de posición (diferencia entre el promedio de Y y la multiplicación con b y el promedio de X ) y b es la pendiente de la recta (se obtiene dividiendo la covarianza entre las variables X e Y y la varianza de la variable X ).
Gráficamente se puede observar lo siguiente:
IACC
a Y b X 1 , 71 0 , 5027 1 , 71 0 , 8503
Así, la ecuación del modelo de regresión es:
Y ˆ 0 , 8503 0 , 5027 x
Por lo que el modelo es:
Altura madre 0 , 8503 0 , 5027 Alturahijo
Interpretación de los coeficientes:
Coeficiente b :
La interpretación del coeficiente b se puede realizar de dos formas complementarias. El signo indica si la relación es directa (signo positivo) o indirecta (signo negativo).
o Si b > 0, las dos variables aumentan o disminuyen a la vez (modelo creciente). o Si b < 0, una variable aumenta, la otra disminuye (modelo decreciente).
Por otro lado, se debe interpretar el número. En este caso, representa la razón de cambio entre las variables, es decir, la variación de la variable Y , cuando la variable X aumenta en una unidad. Considerando los resultados obtenidos anteriormente: se podría concluir que por cada unidad de crecimiento de la variable X , la variable crece 0,5027. Esto representa en el problema que: si dos madres poseen estaturas que se diferencian en un centímetro, las estaturas de sus hijos se diferenciarán en medio centímetro.
Coeficiente a:
El coeficiente a es el valor de la variable Y ˆcuando X = 0, por lo que no siempre tiene sentido su
interpretación. En el ejemplo anterior X = 0 cuando la estatura de una madre es 0 cm. Luego la interpretación de a , en este caso, carece de sentido.
IACC
PORCENTAJE DE EXPLICACIÓN ENTRE LAS VARIABLES
Del ejemplo anterior se podría preguntar: ¿cuánto explica la variable X a la variable Y ?, es decir, qué tan confiable es la predicción de un valor para la variable Y a partir de la variable X. La respuesta a esta interrogante se encuentra en la bondad de ajuste^1.
En un modelo de regresión lineal el grado de bondad de ajuste se establece a partir del coeficiente de determinación , denotado por R^2 , que se calcula:
2 2 2
x y
XY
XY s s
R r S
Donde:
SXY es la covarianza entre las variables X e Y.
Sx y Sy son las desviaciones estándar de ambas variables.
Ejemplo 2:
El dueño de un camping ha observado durante la temporada de verano los siguientes datos registrados de la temperatura media y los litros de agua embotellada que los clientes han comprado en el minimarket del camping en cada semana. Los datos son los siguientes:
(^1) En la construcción del modelo de simulación es importante decidir si un conjunto de datos se ajusta
apropiadamente a una distribución específica de probabilidad. Al probar la bondad del ajuste de un conjunto de datos, se comparan las frecuencias observadas (FO) realmente en cada categoría o intervalo de clase con las frecuencias esperadas teóricamente (FE). Ver más en: http://www.sites.upiicsa.ipn.mx/polilibros/portal/polilibros/p_terminados/SimSist/doc/SIMULACI-N- 128.htm
IACC
Para el coeficiente a , se tiene:
a Y b X 1511 , 11 87 , 35 25 , 56 721 , 556
De este modo, la ecuación del modelo de regresión es:
Y ˆ 721. 556 87. 35 x
Por lo que el modelo es:
Litros 721 , 556 87 , 35 Temperatura
b) Interpretación de los coeficientes de regresión:
b = 87,35. Si la temperatura aumenta en un grado, la cantidad de litros aumenta en 87,35 litros.
a = -721,37. En el contexto del problema no tiene sentido, ya que si no hay temperatura, los litros no pueden ser negativos.
c) Interpretación del coeficiente de correlación:
El valor de r se obtiene:
x y
XY
XY s s
S
r
Por lo que existe una alta correlación lineal, con pendiente positiva.
Ejemplo 3:
Una empresa con el fin de realizar un estudio obtiene la siguiente información, sobre el sueldo de sus trabajadores (en miles de $) y los años de servicio en la empresa. Observar los datos en la siguiente tabla:
IACC
Sueldo (miles de $) Años de servicio 5 10 12 100 – 200 0 1 3 200 – 300 1 0 4 300 – 400 2 3 5 400 – 500 4 5 7
De acuerdo con esta información, estimar los años de servicio de una persona que tiene un sueldo de $320.000.
Solución:
Para responder se debe determinar el modelo de regresión lineal simple:
Primero, se calcula la covarianza:
Si se tienen los promedios de los sueldos y los años de servicio.
Sueldo
Años ^353
N
XY
Sueldo Años
S xy XY X Y 3555 , 714 358 , 571 10 , 086 60 , 833
Se puede concluir que la relación es inversa, es decir, si los años aumentan, el sueldo disminuye.
Ahora la covarianza:
2 2
^
N
X
N
X
S x i i i i
n n
IACC
0
5
10
15
0 5 10 15
% Aumento ventas
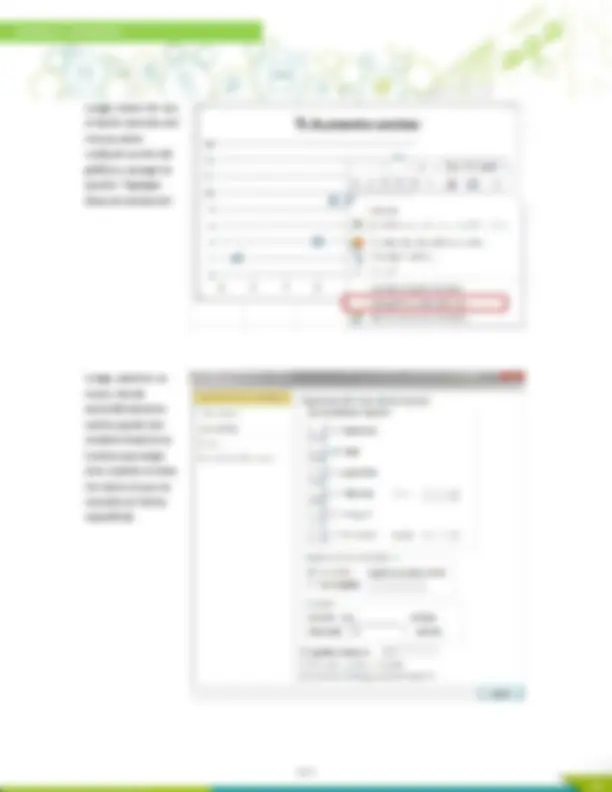
Seleccione ambas columnas de datos, luego Insertar → Gráficos → Dispersión:
Y se obtiene el siguiente gráfico:
: % de aumento de ventas
IACC
Luego, hacer clic con el botón derecho del mouse sobre cualquier punto del gráfico y escoger la opción: “Agregar línea de tendencia”:
Luego, aparece un menú, donde automáticamente está la opción del modelo lineal (si se tuviese que elegir otro modelo se hace clic sobre el que se necesita en forma específica).
IACC
Al hacer clic en las opciones anteriores automáticamente sobre el gráfico aparece el modelo de regresión lineal, además del coeficiente de determinación.
b) La segunda manera para calcular el modelo de regresión es ocupando la herramienta análisis de datos:
En la pestaña Datos pinchar la herramienta “Análisis de datos” y en ella elegir la opción “Regresión”:
Se ingresan los datos de la columna A en el “Rango de X de entrada” y los datos de la columna Y en el “Rango de Y de entrada”:
IACC
Luego, se obtiene la siguiente tabla resumen:
Ejemplo 3:
Suponga que usted como experto en estadística fue contratado con la Conaf para realizar un estudio ambiental sobre la concentración de fosfato en la cuenca de un lago en mg/L y la superficie afectada por el crecimiento de algas, utilizando los datos están en el archivo Excel: “Datos ejemplo 3 semana 6.xlsx”.
Determine lo siguiente:
a) Gráfico de dispersión entre las variables.
b) Determine el coeficiente de correlación entre las variables.
IACC
Otro punto importante es considerar otros modelos de regresión, como son los modelos de línea de tendencia exponencial y logarítmica. Para que aparezcan dichos modelos, en vez de elegir el modelo lineal (en “Agregar línea de tendencia central”) se escoge exponencial o logarítmica, sin olvidar marcar el ticket de la ecuación y el de R cuadrado, ya que permitirá saber qué modelo se ajusta mejor a los datos. Si tomamos como ejemplo la misma base de datos tenemos:
Modelo exponencial Modelo logarítmico
IACC
Se obtiene para el modelo exponencial:
Superfie 38 , 272 e^0 ,^0117 Concentracion , con un coeficiente de determinación de 0,7433 o 74,33%.
Y para modelo logarítmico se obtiene:
Superfie 357 , 43 ln( Concentración ) 1387 , 6 , con un coeficiente de determinación equivalente a 0,8699 o 86,99%.
Por lo que si se comparan los tres modelos, el modelo lineal es más confiable, es decir es el que mejor se ajusta a los datos, ya que su coeficiente de determinación es mayor, por lo que en este último las estimaciones serán más confiables.
Según el ejemplo planteado, en el modelo lineal el coeficiente de determinación es de 0,9674 o 96,74%, lo que significa que es mayor que los resultados de los otros modelos.
COMENTARIO FINAL
En esta semana se aprendió a ocupar una de las ramas más aplicadas de las estadísticas. De aquí se puede obtener una gran información de estimaciones, modelos y confiabilidad. De hecho, la rama de la estadística que estudia esto es llamada inferencia, la que permite obtener una mayor información de las variables y, por ende, de sus estimaciones, especialmente controlando el error que se debe asumir como cero.
La invitación para usted como futuro profesional es seguir ejercitándose, creando modelos con nuevas variables y formulado otras interrogantes que resolver, formando lo que se llama modelo de regresión múltiple, y convertirse en un experto en esta materia, prestando invaluables conclusiones en su trabajo diario.