¡Descarga Introducción a la Estadística: Variables Discretas, Medición, Asimetría y Correlación - Pr y más Resúmenes en PDF de Estadística solo en Docsity!
ESTADÍSTICA APLICADA A LA PSICOLOGÍA
Clases teóricas
Clase 1
¿Qué entendemos por estadística? Son los métodos a través de los cuales podemos recolectar, organizar, resumir, presentar y analizar datos numéricos relativos a un conjunto de individuos u observaciones que nos permitan extraer conclusiones válidas y efectuar decisiones lógicas, basadas en dichos análisis. Cortada de Kohan, 1994 La estadística nos permite tener criterio de decisión para analizar los hechos cuando prevalecen fenómenos que están basados en la incertidumbre, es decir, nos permite formular estrategias para luego resolver de la mejor manera dichos fenómenos. ¿Qué es método? El método de una manera simple es, el modo, manera o forma de realizar algo con un formato sistemático, organizado y/o estructurado. La Estadística tiene dos funciones: ■ Descriptiva: recolectar, organizar, analizar e interpretar datos para sacar conclusiones. ■ Inferencial: sirve para realizar generalizaciones, predicciones y estimaciones. Tiene dos objetivos fundamentales: la estimación de parámetros y la prueba de hipótesis. Entonces, la Estadística, nos permite satisfacer el objetivo de resumir y transmitir de un modo comprensible la información procedente de datos empíricos (estadística descriptiva) así como, cuando sea oportuno, generalizar a partir de la información recogida de un conjunto reducido de sujetos a una población más amplia a la que éstos representen (estadística inferencial). ¿Qué es un dato? La estadística nos brinda datos, que hace que rompamos con el sentido común. Tal como se lo conceptualiza desde la metodología, un dato es el valor que toma una variable en una unidad de análisis. Por esta razón se dice que su estructura es “tripartita”. La unidad de análisis (UA) es cada uno de los elementos sobre los que se desea recoger información en un determinado estudio, son los sujetos u objetos de estudio. Por ejemplo, las personas que se contagiaron de COVID-19. La variable, son las características o propiedades que pueden asumir distintos valores en cada una de las UA. Por ejemplo, el sexo y la edad de los muertos por COVID-19. Las variables desde el punto estadístico pueden dividirse en cualitativas y cuantitativas. A su vez estás últimas pueden dividirse en discretas y continuas. La variable cualitativa , son las variables que pueden tomar como valores cualidades. El sexo de los contagiados, sus categorías o valores que son varón y mujer. La variable cuantitativa , toma valores numéricos. Las variables discretas son aquellas que entre un valor y otro de la variable no tienen valores intermedios, por ejemplo, el número de hijos de una familia, la cantidad de dedos que tienes en la mano, el número de faltas en un partido de fútbol, el número de personas que llegan a un consultorio en una hora, etc. Las variables continuas son aquellas que entre un valor y otro de la variable poseen valores intermedios, por ejemplo, la cantidad de horas que utilizan el respirador los pacientes
hospitalizados (un paciente 24 horas y 30 minutos, otro 3hs y 45 minutos), la estatura exacta de una persona (1,57), el peso de una persona (49,5), el tiempo que tarda un delivery en entregar un pedido, etc. Valor de la variable : es la cantidad de valores que puede asumir una característica o propiedad. Por ejemplo, la variable “edad” de los muertos tiene los siguientes valores en años, 60 y 72 años. Una vez que hemos recolectado los datos los ordenamos en una matriz de datos. Es un cuadro de doble entrada donde se visualiza claramente la estructura tripartita del dato. Unidad de análisis Variable 1 Variable 2 Variable 3 1 Valor Valor Valor 2 Valor Valor Valor 3 Valor Valor Valor Nos permite hacer una lectura horizontal donde podemos analizar todas las variables en una UA en particular, y una lectura vertical donde se puede analizar una variable en particular en todas las UA. Otra decisión que tenemos que tomar al realizar un trabajo estadístico es si trabajamos con toda la población o con una muestra. La población la definimos como el conjunto total de sujetos o elementos que presentan características comunes. En el caso de la pandemia en nuestro país serían todos los habitantes de la Argentina. Generalmente no trabajamos con toda la población porque es muy costoso, se necesita más personal para realizar el trabajo y lleva más tiempo procesar los datos. Entonces trabajamos con una muestra que es un subconjunto representativo de la población, podría ser los conglomerados urbanos de más de 500. habitantes. Una muestra representativa debe contener todas las características de la población o universo, para que los resultados sean generalizables. Siempre en la vida cotidiana estamos midiendo, necesitamos saber en qué magnitud se dan las cosas. El problema de la medición posiblemente es más controversial en psicología que en otros dominios del conocimiento, debido a la complejidad del comportamiento humano y las limitaciones de los instrumentos utilizados. El objeto de estudio de la psicología es complejo, subjetivo, multivariado. El psicólogo que investiga, analiza, evalúa, diagnostica, está midiendo; aunque no se lo imagine, aunque lo niegue. La medición en Psicología constituye una herramienta que le permite al psicólogo cuantificar características humanas y objetivizar procesos de evaluación. En cualquier disciplina técnica o científica, la validez de la medición se basa en el respeto a los principios de la teoría general de la medición. En este sentido, una representación por medición de un atributo es adecuada si es coherente con la idea conceptual sobre dicho atributo comúnmente aceptada por los expertos. Así, los datos obtenidos como medidas deben representar los atributos de las entidades reales que pretendemos caracterizar, y el manejo de dichos datos debe preservar las relaciones que existen entre dichas entidades. Para establecer medidas, debemos partir entonces de la observación del mundo real. Debemos identificar cuáles son las entidades que queremos medir y definir qué atributo deseamos caracterizar. Además, es importante identificar las relaciones empíricas que se pueden establecer entre las entidades reales en relación con el atributo que nos interesa. Entre los psicólogos es muy habitual estudiar actitudes, conceptos, opiniones, valoraciones, tendencias, motivos y obligatoriamente los investigadores los organizan a partir de los datos e información obtenida, en categorías que permitan agrupar esos datos y aproximarse a una valoración grupal o poblacional del hecho estudiado. En ocasiones han podido llegar hasta el establecimiento de un cierto orden jerárquico entre una categoría u otra. Cuando un investigador realiza estas acciones en el análisis de sus datos está midiendo. Se encuentra en una primera etapa del proceso de medición o de construcción de una escala o de un instrumento; pero ya lo está haciendo.
Hay dos definiciones que me parece importante tener en cuenta una más clásica, donde se define a la medición como: “Asignar números, símbolos o valores a las propiedades de los objetos de acuerdo a ciertas reglas” (Stevens, 1951) Y otra más actual que la define como: “El proceso de vincular conceptos abstractos con indicadores empíricos (Carmines, 1991). Una escala de medición es el conjunto de los posibles valores que una cierta variable puede tomar. El nivel en que una variable puede ser medida determina las propiedades de medición de una variable, el tipo de operaciones matemáticas que puede usarse apropiadamente con dicho nivel, las fórmulas y procedimientos estadísticos que se utilizan para el análisis de datos y la prueba de hipótesis teóricas. Las escalas o niveles de medición se utilizan para medir variables o atributos. Por lo general, se distinguen cuatro escalas o niveles de medición: nominal, ordinal, intervalos y escalas de proporción, cociente o razón. Los niveles de medición nominal y ordinal se conocen como escalas categóricas , y se usan comúnmente para variables cualitativas Los niveles de medición intervalar y racional se conocen como escalas numéricas , son adecuadas para la medición de variables cuantitativas. Las propiedades que tienen los valores finales de una variable, son el orden, la distancia y el origen. Estas propiedades hacen que se generen las cuatro escalas de medición: nominal , ordinal , intervalar y racional. Nivel nominal Es la escala más elemental y la forma más rudimentaria de medir. En una escala como esta se clasifica a las unidades de análisis (objetos, personas, etc.) en categorías, basándose en una o más características, atributos o propiedades distintivas y observadas, dándole a cada categoría un nombre (de ahí lo de «nominal»). Con las escalas nominales (categóricas), los números asignados definen cada grupo distinto y sirven meramente como etiquetas o identificadores. Los números hacen distinciones categóricas más que cuantitativas; cumplen una función puramente de clasificación y no se pueden manipular aritméticamente; cada cifra representa una categoría diferente. Las categorías deben ser exhaustivas y excluyentes. Cuando hablamos de excluyentes si tomamos como ejemplo la variable caso sospechoso tenemos que incluir cada UA en la categoría Si o en NO. Un individuo no puede estar en las dos categorías. Cuando nos referimos a exhaustiva es que tenemos que tener en cuenta todas las categorías en que se puede presentar la variable. Los números (1 y 2) no refleja orden (ascendente o descendente) o jerarquía (mayor o menor) de alguna de las cosas a las que fueron asignados. En nuestro ejemplo podría tomar la variable caso sospechoso y definir las categorías como si o no. Caso sospechoso 1 2 1 corresponde a Si, y 2 corresponde a No. Cuando una variable tiene dos categorías mutuamente excluyentes, se llama variable dicotómica. Las observaciones NO pueden ser ordenadas de menor a mayor o de pequeño a grande, es decir, ninguna de las categorías tiene mayor jerarquía que la otra, únicamente están reflejando diferencias en la variable. Las únicas relaciones matemáticas adecuadas a las escalas nominales son las de equivalencia (=) o no equivalencia (≠). Así, una entidad u objeto particular posee la característica que define la clase (=) o no la tiene (≠). Las escalas nominales sólo admiten el cálculo de proporciones, porcentajes y razones. Caso sospechoso Si No
Escala ordinal Una escala de medición ordinal se logra cuando las observaciones pueden colocarse en un orden relativo con respecto a la característica que se evalúa, es decir, las categorías de datos están clasificadas u ordenadas de acuerdo con la característica especial que poseen. Aquí, las etiquetas o símbolos de las categorías SI indican jerarquía. Si utilizamos números, la magnitud de estos no es arbitraria, sino que representa el orden del rango del atributo observado. Se supone un continuo subyacente en los números de modo que las relaciones típicas son, en este caso, «más alto que», «mayor que» o «preferible a». Sólo las relaciones «mayor que», «menor que» e «igual a» tienen significado en una escala de medición ordinal. Ejemplo: Presentación del cuadro de coronavirus en un caso confirmado. Cuadro Muy leve Leve Grave Muy grave Puedo poner 1= muy leve 2= leve 3=grave 4=muy grave. Aquí las etiquetas muestran jerarquías. Cuando los objetos o eventos se clasifican por una característica, es posible determinar qué objeto o evento tiene más o menos de la característica comparando con otro; pero no podemos decir, basados en el orden solamente, en cuánto difieren. Desde el punto de vista matemático, y al igual que las escalas nominales, las escalas ordinales sólo admiten el cálculo de proporciones, porcentajes y razones. Escala Intervalar Aquí puede establecerse orden entre sus valores, hacerse comparaciones de igualdad, y medir la distancia existente entre cada valor de la escala. El valor cero de la escala no es absoluto, sino un cero arbitrario: no refleja ausencia de la magnitud medida, por lo que las operaciones aritméticas de multiplicación y división no son apropiadas. Cumple con las propiedades de identidad, magnitud e igual distancia. La igual distancia entre puntos de la escala significa que puede saberse cuántas unidades de más tiene una UA comparada con otra, con relación a cierta característica analizada. Por ejemplo, en la escala de temperatura centígrada puede decirse que la distancia entre 25° y 30°C es la misma que la existente entre 20° y 25°C, pero no puede afirmarse que una temperatura de 40°C equivale al doble de 20°C en cuanto a intensidad de calor se refiere, debido a la ausencia de cero absoluto. Ejemplo: Las edades de los casos sospechosos. La diferencia entre 24 y 26 años es la misma que hay entre 28 y 30 años. El cero es arbitrario porque se mide desde el nacimiento (no hay ausencia de variable). Escala racional También llamada escala de cociente, estas escalas tienen las propiedades de las ordinales y de intervalo (intervalos iguales entre categorías) pero, además, el cero es real, es absoluto, no es arbitrario. Es decir, el cero representa la ausencia de la característica en cuestión; en consecuencia, los números pueden compararse como proporciones y nos permite indicar cuántas veces es más grande un objeto que otro, además de señalar la cantidad en que difieren. En esta escala sólo es arbitraria la unidad de medida. El hecho de fijar
Procesamiento de la información Una primer forma de procesar la información es hallando la frecuencia. Tipos de frecuencias Frecuencias absolutas (cantidad de veces que se repite cada valor de la variable). Frecuencias relativas (relación de frecuencia entre una categoría y el total de casos) Frecuencias relativas porcentuales (planteo en porcentajes) Frecuencias acumuladas (acumulación de los valores de la variable) Frecuencias relativas y acumuladas Frecuencia relativa y relativa porcentual Total, de casos confirmados, cuyo origen de contagio es importado 718 casos. Total, de casos confirmados=1628 fr=718/1628= 0,441 fr%=44,10% EDAD Frec. absoluta Frec. acumulada 18 4 4 19 1 5 20 3 8 21 1 9 22 2 11 N 11 Proporción y razón
1. Cuando ambos números son el mismo tipo de magnitud, existen dos tipos de indicadores, “proporción” y “razón”, que se distinguen según el numerador sea o no un subconjunto del denominador: 1.a. Proporción. Cociente que resulta de dividir un subconjunto por el conjunto total en que está incluido (p.ej. las mujeres de una población respecto a la población total) 1.b. Razón. Cociente que resulta de dividir dos conjuntos o subconjuntos distintos que no tienen elementos comunes (p.ej. los hombres de una población respecto a las mujeres de esa población, la llamada “razón de masculinidad “). Proporciones y tasas ■ Tasa: Cociente que resulta de dividir un número de acontecimientos sucedidos durante un periodo de tiempo (un flujo) por la población existente durante ese periodo (por ejemplo, la tasa de mortalidad, número de defunciones durante un periodo de tiempo, dividido por la población de ese mismo periodo). Ejemplos de tasas y proporciones Razón de masculinidad: Esla relación entre el número de hombres y de mujeres en una población dada y se expresa como el número de varones por cada 100 mujeres. r=V/M r=912/716=1,27 hay 1,27 varones por cada mujer. Tasa de incidencia de casos: (1628/44.560.000) x100000=3,65 0/ Tasa de letalidad: (54/1628) x100= 3,31 % La incidencia y la prevalencia son dos medidas de frecuencia de la enfermedad, es decir, miden la frecuencia (el número de casos) con que una enfermedad aparece en un grupo de población. ■ Prevalencia: describe la proporción de la población que padece la enfermedad, que queremos estudiar, en un momento determinado, es decir es como una foto fija. No tiene en cuenta la variable tiempo.
Tasa de Prevalencia=n° de casos conocidos de una determinada Enfermedad/Población x 10ⁿ ■ Tasa de incidencia: va a contabilizar el número de casos nuevos, de la enfermedad que estudiamos, que aparecen en un período de tiempo previamente determinado Tasa de Incidencia=n° de casos nuevos de una enfermedad en determinada comunidad en cierto período de tiempo/n° de personas expuestas al riesgo de adquirir la enfermedad en el período referidox10ⁿ Tasa de letalidad Es la proporción de personas que mueren por una enfermedad entre los afectados por la misma en un periodo y área determinados. Es un indicador de la virulencia o de la gravedad de una enfermedad. L%: tasa de letalidad. F: Número de muertes por una enfermedad en un periodo y área determinados. E: Número de casos diagnosticados por la misma enfermedad en el mismo periodo y área. Cantidad de personas muertas por coronavirus L%=------------------------------------------- x Cantidad de personas con diagnóstico de la enfermedad. Tasas de mortalidad infantil: indica la cantidad de niños menores de 1 año que fallecieron en relación a los niños que nacieron, en un tiempo y lugar determinado. Tasa de mortalidad infantil total por 1.000 nacidos vivos, según provincia de residencia de la madre. Total del país. Años 2012-
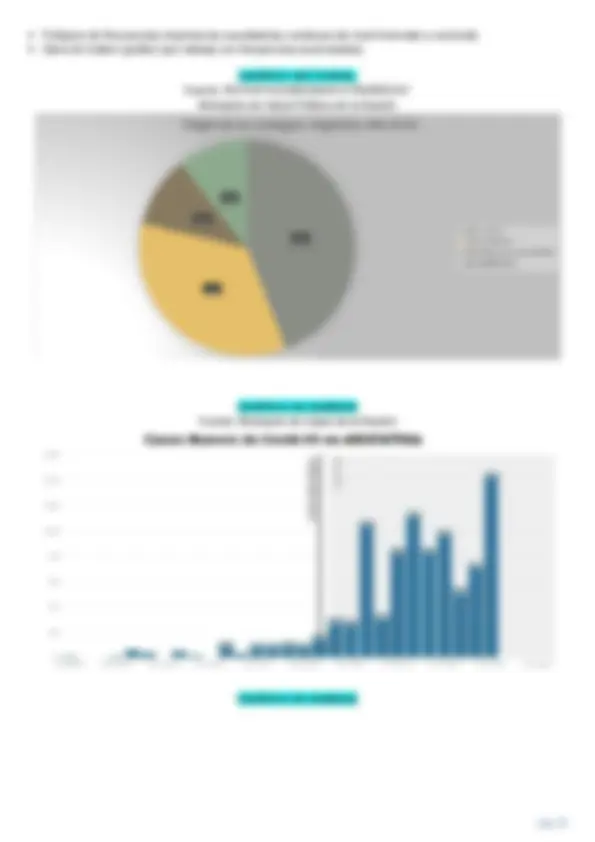
Polígono de frecuencias (representa cuantitativas continuas de nivel intervalar y racional). Ojiva de Galton (grafico que trabaja con frecuencias acumuladas). GRÁFICO SECTORIAL Fuente: REPORTEDIARIOMATUTINONRO47. Ministerio de Salud Pública de la Nación GRÁFICO DE BARRAS Fuente: Ministerio de Salud de la Nación GRÁFICO DE BARRAS
HISTOGRAMA DE PEARSON
OJIVA DE GALTON
Modo = Mo Es aquel valor de la variable que se presenta con mayor frecuencia, es decir es el valor de variable más común, la moda puede no existir, incluso si existe puede no ser única. Si una distribución presenta dos modas se la denomina bimodal y si presenta una sola moda se la denomina unimodal. Si presenta más de dos modas, se llama multimodal. Lo utilizamos cuando queremos saber cuál es el valor de la variable que más se repite. Se puede calcular en todos los niveles de medición. Modo: contacto con casos confirmados Mediana = Md Es el valor de la variable que divide a la distribución en dos partes iguales de un 50% cada una. Quiero averiguar cuál es la mediana de edad de las personas que hoy dieron positivo en el test de coronavirus me dicen que la Md. es 50 años, esto quiere decir que el 50% de los casos que hoy dieron positivo tienen 50 o menos años. Utilidad de la mediana La calculamos cuando queremos saber el orden medio de un conjunto de datos. Se utiliza cuando las distribuciones son asimétricas. También cuando hay intervalos abiertos, cuando no tenemos todos los valores de la escala. Se puede hallar a partir del nivel de medición ordinal. La podemos calcular también en el nivel intervalar y racional. Media Aritmética = M es el promedio de los valores de la variable. Es la suma de todos los valores dividido por el número de casos. La calculamos cuando queremos saber el promedio de una distribución. Se calcula la media cuando la distribución es simétrica. Cuando queremos estimar parámetros. Se utiliza con variables cuantitativas en el nivel intervalar y racional Propiedades de la Media Aritmética
La suma de los desvíos o diferencias de todos los valores de la variable respecto de la media aritmética es cero. Ej: 2-4-6-8-10 Media=6 puntos La suma de los cuadrados de los desvíos de los valores respecto a la media aritmética es menor que la suma de los cuadrados de los desvíos respecto a cualquier valor. 38< Se puede calcular la Media total. Tengo tres grupos con las notas promedio de los parciales y el número total de alumnos Grupos Media aritmética Total de casos A 6 puntos 25 B 5 puntos 30 C 7 puntos 20 Mt : Ma.na+Mb.nb+Mc.nc/na+nb+nc=6.25+5.30+7.20/25+30+20=5,86 puntos. Propiedades aritméticas : si sumamos, restamos, multiplicamos y dividimos a cada valor de la variable por una constante X, la media aritmética va a ser igual a M+c M-c M/c Mxc. Medidas NO centrales de posición: Medidas de Orden Cuartiles : son tres: C1-C2-C3 Dividen la serie ordenada de observaciones en 4 partes iguales, de un 25% cada una. Deciles : son 9: D1, D2, D3, D4, D5, D6, D7, D8 y D9. Dividen la serie ordenada de observaciones en 10 partes iguales, de un 10% cada una. Percentiles : son 99: P1………P99. Dividen la serie ordenada de observaciones en 100 partes iguales, de un 1% cada una. Cuartiles = Q₁ Q₂ Q₃
Rango o amplitud total También Llamado recorrido, es la diferencia entre el valor mayor y el valor menor de una distribución. At = VM-Vm Casi no se emplea debido a que depende solamente de dos valores. No proporciona una medida de variabilidad de las observaciones con respecto a la centralidad de la distribución. Por ejemplo, para una serie de datos de carácter cuantitativo, como lo es la estatura medida en centímetros (Figura 1). Es posible ordenar los datos como (Figura 2). ¿Cuál es el rango? R. 30 centímetros. Figura 1 Figura 2 Desviación semi-intercuartil Es la mitad del intervalo entre el C1 y el C3. Está relacionada con la Mediana. Me da información sobre la dispersión del 50% central de casos. Utilizar los cuartiles para analizar la forma de la distribución Utilizando los cuartiles podemos analizar la forma de la distribución, Si es simétrica o asimétrica (negativa o positiva) SIMETRIA (C3 - C2) = (C2 - C1) C1+ Q = C ASIMETRIA POSITIVA (C3 - C2) > (C2 - C1) C1+ Q > C ASIMETRIA NEGATIVA (C3 - C2) < (C2 - C1) C1+ Q < C Desvío estándar o típica Es la raíz cuadrada del promedio de los desvíos a la media al cuadrado. Propiedades del desvío estándar
1. Si se suma o resta una constante a todas las observaciones, la desviación estándar NO varia.
2. Si multiplicamos o dividimos a todos los valores de la variable por una constante, la desviación estándar queda multiplicada o dividida por la constante. Para distribuciones normales resulta que: a) El 68,34% de los casos están comprendidos en la Media y más/menos un desvío estándar. Es decir, el valor de la desviación estándar a ambos lados de la media aritmética. b) El 95,45% de los casos están comprendidos entre la Media y más/menos dos desvíos estándar. Es decir, el doble del valor de la desviación estándar a ambos lados de la media aritmética. c) El 99,74% de los casos están comprendidos entre la Media y más/menos 3 desvíos estándar. Es decir, el triple del valor de la desviación estándar a ambos lados de la media aritmética. ZONA DE NORMALIDAD ESTADÍSTICA
Escriba aquí la ecuación.
Varianza Esta medida nos permite identificar la diferencia promedio que hay entre cada uno de los valores respecto a su punto central (Media aritmética). Este promedio es calculado, elevando cada una de las diferencias al cuadrado (Con el fin de eliminar los signos negativos), y calculando su promedio o media; es decir, sumado todos los cuadrados de las diferencias de cada valor respecto a la media y dividiendo este resultado por el número de observaciones que se tengan. Ventajas de la varianza Es útil cuando se compara la variabilidad de dos o más conjuntos de datos. Utiliza toda la información disponible. Desventajas de la varianza No proporciona ayuda inmediata cuando se estudia la dispersión de un solo conjunto de datos. Difícil de interpretar por tener sus unidades elevadas al cuadrado. Desviación estándar y Varianza Ventajas Se pueden utilizar en estimaciones de parámetros de población. Considera todos los valores de la distribución. Es la más sensible de las medidas.
Cómo interpretar el resultado Si el resultado de Cu es menor a 0,263 la distribución es Leptocúrtica. Si el resultado de Cu es 0,263 la distribución es Mesocúrtica. Si el resultado de Cu es mayor a 0,263 la distribución es Platicúrtica.
Clase 4
PROBABILIDAD
El concepto de probabilidad es a veces parte de nuestra vida cotidiana, frecuentemente escuchamos preguntas como: ¿Cuál es la probabilidad de que me saque la lotería? ¿Qué probabilidad hay de que hoy llueva? ¿Existe alguna probabilidad de que apruebe el primer parcial? La Estadística nos brinda herramientas para estudiar fenómenos en los cuales no se conocen las leyes que los rigen, a los que llamamos fenómenos aleatorios. La base matemática de estos fenómenos aleatorios la proporciona la Teoría de la Probabilidad. ¿Cuál es la importancia de la teoría de la probabilidad en Psicología? La Psicología tiene como objetivo la descripción, la comprensión, la predicción y el control de la conducta y los procesos mentales. Por predicción se entiende la capacidad para prever una conducta con certeza, es decir, para que la psicología pueda en su momento predecir la conducta es necesario que sea capaz de hacer que todos los datos particulares que obtiene mediante la investigación sean capaces de ser generalizados y de ahí poder inferir, con una tasa de certeza suficiente, un comportamiento, acción o situación. La importancia de la probabilidad radica en que, mediante este recurso matemático, es posible ajustar de la manera más exacta posible los imponderables debidos al azar en los más variados campos tanto de la ciencia como de la vida cotidiana. La probabilidad y la estadística son usadas, por un lado, como forma de obtener, interpretar y generalizar los datos, y por el otro, para poder predecir de ahí mismo ciertos eventos futuros. ¿A qué llamamos fenómeno aleatorio? Un fenómeno aleatorio es aquel que ejecutado bajo las mismas condiciones puede tener varios resultados. En cada ocurrencia del fenómeno es imposible predecir el resultado, atribuyéndose al azar. Para considerar que un experimento es aleatorio se tienen que dar las siguientes condiciones:
1. Se puede repetir indefinidamente, siempre en las mismas condiciones; 2. Antes de realizarlo, no se puede predecir el resultado que se va a obtener;
3. El resultado que se obtenga, pertenece a un conjunto conocido previamente de resultados posibles. Por ejemplo: si tiramos un dado puede tener seis resultados (que salga 1, 2, 3, 4, 5 o 6) Antes de su lanzamiento ¿puede predecirse el resultado? No lo podemos saber de antemano. Si no lo podemos saber ¿cómo podemos estudiar los fenómenos aleatorios? Pese a su naturaleza aleatoria hay algunos comportamientos que podemos esperar, por ejemplo, si tiramos muchas veces (1000) una moneda podríamos esperar que más o menos la mitad salga cara y la otra mitad ceca. Siempre que el evento sea equiprobable quiere decir que todos los posibles resultados tienen las mismas oportunidades de salir. Si una moneda tiene una cara con alguna modificación que influya en que salga más veces, no sería un evento equiprobable. A veces se habla de los dados cargados, significa que está alterado ligeramente la distribución del peso de una cara, por ejemplo, en el número 2, entonces uno puede hacer que caiga más seguido en ese número. Los dados de casino suelen fabricarse en material transparente, para que pueda verse su interior y se vea que no está trucado. Se procura que la densidad del material se distribuya uniformemente por todo el dado, para que no haya unas caras más favorecidas que otras. Vamos a plantear algunos conceptos de la teoría de la probabilidad: ¿A qué llamamos espacio muestral? Cuando tenemos un suceso aleatorio, el conjunto de cada uno de los resultados individuales posibles de ese suceso se denomina espacio muestral , y suele denotarse con la letra omega mayúscula: Ω Ejemplo: tirar una moneda, tengo 2 resultados posibles cara o ceca Ω lanzar una moneda = {cara, ceca} Tirar un dado, tengo 6 resultados posibles Ω lanzar un dado = {1, 2, 3, 4, 5 o 6} ¿A qué llamamos evento? Es cualquier subconjunto del espacio muestral. Ya vimos que el espacio muestral al tirar un dado es 6, pero si yo estoy buscando que salga par el evento está conformado por 3 resultados posibles (2, 4 y 6). ¿Cómo podemos definir qué es Probabilidad? La probabilidad de que ocurra un evento se mide por un número entre cero y uno, inclusive. Si un evento nunca ocurre, su probabilidad asociada es cero , mientras que si ocurriese siempre su probabilidad sería igual a uno. Así, las probabilidades suelen venir expresadas como decimales , fracciones o porcentajes. Existen diferentes formas para definir la probabilidad de un evento basadas en formas distintas de calcular o estimar la probabilidad. Hay tres formas de obtener la probabilidad de un suceso. La elección dependerá de la naturaleza del problema. Puede obtenerse de tres formas: 1- Teórica 2- Empírica 3- Subjetiva Teórica : es la definición clásica de probabilidad fue una de las primeras que se dieron (1900) y se atribuye a Laplace; también se conoce con el nombre de probabilidad a priori pues, para calcularla, es necesario conocer,