Scarica come utilizzare trados e più Schemi e mappe concettuali in PDF di Traduzione solo su Docsity!
STRUMENTI INFORMATICI PER LA TRADUZIONE: TRADUZIONE
ASSISTITA E LOCALIZZAZIONE – AIRAGHI
LEZIONE 2 – 30/
User accedere al PC: 01-trass039 poi diventerà 02-trass password: sdl. Strumenti per la traduzione assistita: intesi come tutti gli strumenti di natura informatica che assistono ed aiutano un traduttore nel suo lavoro. In senso ampio, questa categoria comprende tutto ciò che va dal software per la l’elabroazione dei testi al software per la linguistica dei corpora Nel corso del tempo, però, da circa 25 anni più o meno cioè da quando questo genere di strumenti si è affermato, come strumenti per la traduzione assistita si è stabilito di identificare quegli strumenti che, basati su archivi detti memoria di traduzione, aiutano un traduttore nel suo lavoro consentendogli di memorizzare all’interno di questi archivi porzioni di testo associate alle traduzioni che il traduttore stesso stabilisce essere le più idonee per quelle particolari porzioni di testo in quei particolari contesti. Ciò comporta che l’uso di strumenti del genere trova applicazione nell’ampissimo ambito della traduzione commerciale e non nella
traduzione editoriale (e soprattutto non per narrativa e poesia). Discorso a parte per la saggistica. Per traduzione commerciale si intende tutto il resto, chiamata anche traduzione tecnica: intendiamo tutto ciò che non è narrativa, poesia, saggistica quindi contratto, brevetto, norma di legge, manuali e libretti di istruzioni, traduzione in ambito giuridico, ma anche tutto il materiale di marketing che correda un prodotto (brochure, pieghevole, comunicato stampa che annuncia il lancio di un prodotto, tutorial per imparare ad usare il prodotto che si acquista). Quasi mai questi materiali vengono redatti in lingua italiana, anzi, è raro. La maggior parte dei prodotti soprattutto tecnologici vengono redatti in inglese Quindi cosa succede? Se io traduco un manuale riferito ad un certo prodotto (es. iPhone 7), le probabilità che le istruzioni d’uso dell’iPhone 7 siano in buona misura uguali o simili a quelle dell’iPhone 6 + tutta la parte di novità insita nel nuovo prodotto, non è particolarmente produttivo ricominciare a tradurre da 0 la documentazione corredata all’iPhone 7. È molto più sensato recuperare ciò che si può recuperare della documentazione relativa all’iPhone 6, tenere inalterate le parti che sono state replicate tali e quali + tradurre ex novo le novità e modificare ciò che
Chiaramente poi dovrò cambiare anche tutti i maschili/femminili -> the qui sta per la e lo Se esiste una porzione di testo non uguale ma simile il computer se ne accorge e mi dice dove stanno le differenze. Questo archivio è un database che si chiama memoria di traduzione (traslation memory), che contiene porzioni di testo e traduzioni. Le coppie formate da porzione di testo originale e traduzione si chiamano TU (translation unit) La porzione di testo originale che viene identificata autonomamente dal software si chiama segmento. La lingua di partenza è la source language e la lingua di arrivo target language.
La memoria di traduzione, però, funziona con 2 lingue per volta in una ben precisa direzione (se traduco da inglese ad italiano uso una memoria inglese-italiano, quando traduco verso il francese sto usando un’altra memoria) la memoria ING- ITA non posso usarla per tradurre da italiano ad inglese
Da un’altra parte avrò un altro archivio in cui ho termini e traducenti:
Quindi il mio software per ogni segmento del quale mi sto occupando esegue contemporaneamente due ricerche: una nella memoria di traduzione per cercare porzioni di segmento uguale, e l’altra nella term base dove per ogni segmento mi cerca e mi dice se nella term base sono presenti termini che ricorrono nel mio segmento corrente e rispettivi traducenti. Queste sono le due funzioni principali di un software di
traduzione assistita: da un lato la consultazione della memoria ovvero ricerca di segmenti uguali o simili al mio segmento originale corrente e dall’altra la ricerca nella term base di eventuali parole presenti nel mio segmento ed eventuali traducenti.
quando il mio software trova che nella memoria è presente un segmento perfettamente identico al mio segmento corrente mi dice che ho trovato un FULL MATCH. Stabilisce che le due porzioni di testo sono identiche se io scrivo the pen is on the table e lui mi trova the pen is on the tabel FULL MATCH/match 100% se io scrivo the pen is on the table e lui mi trova the pen is under the table FUZZY MATCH/match parziale il mio strumento in qualche modo riesce a quantificare ed esprimere numericamente la somiglianza tra due porzioni di testo. fa un confronto carattere per carattere. Se non trova differenze, deduce che la somiglianza sia pari al massimo previsto: 100
Il software non riesce ad interpretare il significato di una virgola o di un trattino, non è in grado di esprimersi sulla correttezza o meno dell’utilizzo di quel segno di interpunzione.
il testo suddivide il testo in porzioni minime chiamate segmenti. Ma che regole applica? Non applica regole di natura grammaticale: non è detto che un segmento sia una frase. I segni di interpunzione che segnano la fine di un segmento sono il punto, punto e virgola, due punti non sempre (dipende dall’impostazione), il segno di paragrafo (quando vado a capo, per Trados il segmento finisce), punto esclamativo, punto esclamativo, segno di tabulazione (contenuti delle celle)
il file check spelling and grammar è stato pre-segmentato, ovvero scomposto secondo le regole viste prima, ovvero secondo segni di punteggiatura e paragrafo. Abbiamo sulla destra lo spazio predisposto per accogliere la traduzione di ciascun segmento, quindi qui ho segmenti che vanno dall’1 al 34, una parte dei quali è corredata da una traduzione, la quale è l’esito dell’operazione di
ricerca che Trados ha svolto: ha segmentato il testo, ha identificato le unità
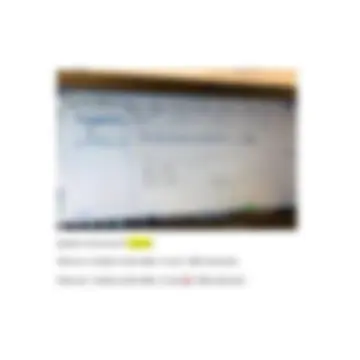
Nel caso del segmento numero 4 mi dice invece che in memoria non ha trovato alcun segmento che somigliasse al mio numero 4 in misura pari o superiore alla soglia impostata, perciò non mi mette niente ciò non vuol dire che non esiste nemmeno un segmento simile in memoria; semplicemente non nella misura da noi richiesta (%) Casellina azzurra AT: vuol dire che quello che noi troviamo sulla destra è frutto di quella che lui chiama traduzione automatica (automatic translation): contrassegna come risultati di traduzione automatica tutti i tentativi che lui fa per popolare lo spazio destinato alla traduzione senza ricorrere alla memoria di traduzione né all’intervento umano. Ci sono infatti soltanto URL, siti internet.
- Perde il colore dello sfondo. Fuzzy match modificato da un traduttore umano:
Altra cosa che il software ci dice relativamente allo stato dei segmenti è che io ho dei segmenti non tradotti se hanno il riquadro bianco: se io mi posiziono infatti col cursore sulla casellina colorata, mi dà dei dettagli:
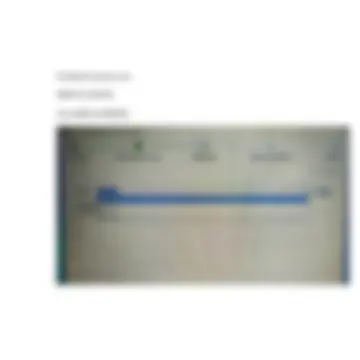
modificherò in qualche misura questa traduzione, allora potrò confermarla e allora a quel punto il segmento assumerà lo stato tradotto. Confermando la traduzione, io contemporaneamente farò un’altra cosa: invierò alla memoria di traduzione la nuova coppia di originale segmento numero 5 + traduzione adeguata e confermata da me, creando così una nuova TU COME TENERE SOTTO CONTROLLO LO STATO DI AVANZAMENTO La situazione generale del mio file, ovvero quanta parte ho tradotto e quanta me ne manca e quanta ho in bozza, mi viene costantemente riassunta in fondo allo schermo:
L’icona del foglio bianco (non tradotto), l’icona della matita blu senza spunta (bozza), l’icona della matita con la spunta (confermata): la loro somma fa sempre 100 (a volte sballa, perché arrotonda). !! Non si consegna mai una traduzione i cui segmenti non siano stati prima tutti consegnati Lo stato di avanzamento lo controllo anche da qui:
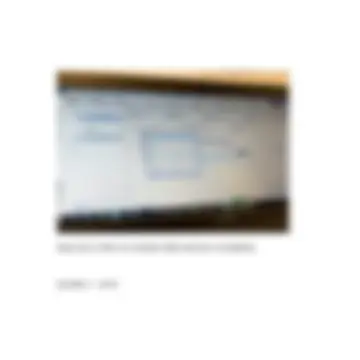
Quando io vado ad occuparmi del segmento numero 5, trados mi mostra i risultati delle sue ricerche: quel fuzzy match pari all’85% la cui traduzione mi è stata proposta, mi viene mostrata e Trados mostra dove risiedono le differenze tra ciò che c’è in memoria e il mio nuovo originale corrente. Dal suo punto di vista, dunque, la differenza sta nel fatto che in memoria c’era un segmento originale con una parte in più rispetto al mio segmento corrente, quella barrata in rosso (barrata come se Trados ci dicesse cancella questa parte per far si che il contenuto della memoria sia uguale al mio segmento corrente ). Dovrei cancellare , often called spell check, (quindi con rispettive virgole)
In memoria c’è: the spelling and grammar checker, often called spell check, is located in different places on the ribbon, depending on your program.
testo di inserirlo Visitate il sito www.iulm.it per ulteriori informazioni Oppure posso dire Visitate qui -> è un collegamento ipertestuale formata da una parte testuale (qui) e da un indirizzo (www.iulm.it) questa entità, dal punto di vista di un traduttore, è duplice: da una parte c’è il testo che va tradotto, ma non necessariamente dovrei intervenire sull’indirizzo in sé a meno che l’università non abbia anche una versione in inglese del sito. Il collegamento ipertestuale, essendo un’entità duplice dal punto di vista del traduttore, lo è anche dal punto di vista di trados, il quale mi prende la parte di testo e me la lascia nel segmento al quale appartiene; mi estrapola poi l’indirizzo e me lo mette in un segmento successivo così che io possa tradurre la parte testuale, ed occuparmi come si conviene dell’indirizzo (= il mio cliente potrebbe avermi chiesto nel caso di controllare, in caso di collegamenti ipertestuali, che esista la versione italiana di quella pagina -> a quel punto metti la pagina italiana, non lasciare la pagina inglese)
LEZIONE 3 – 7/
Noi dobbiamo sempre salvare i nostri file sul disco di rete (NON sul disco C, altrimenti il lavoro viene perso, ma solo su disco X). La cartella servizio serve alla prof per distribuirci il materiale -> “servizio 2020”: qui salva i file SOLO la prof (a meno che stiamo facendo un esame). Tutto ciò che noi faremo nell’ambito di traduzione avrà una collocazione in uno spazio denominato “Progetto”, che è l’entità virtuale all’interno del quale Trados registra l’esistenza di determinati file da tradurre, determinate memorie di traduzione da utilizzare nel corso del lavoro, di determinate term base da consultare e tutte le caratteristiche che si assegneranno al progetto (scadenza, cliente per il quale lavoro, la combinazione linguistica…). Come se io avessi una specie di raccoglitore con tutto questo all’interno. Indipendentemente da tutto, nel momento in cui io entro sul trados per svolgere un lavoro di traduzione, la prima cosa che faccio sarà: creare un progetto. Apro Trados studio, e mi chiede di configurarlo: