



Apostila Completa
Aula 3
Aprenda a criar modelos de previsão usando
Ciência de Dados.
Impressionador do absoluto zero!



























Estude fácil! Tem muito documento disponível na Docsity

Ganhe pontos ajudando outros esrudantes ou compre um plano Premium

Prepare-se para as provas
Estude fácil! Tem muito documento disponível na Docsity
Prepare-se para as provas com trabalhos de outros alunos como você, aqui na Docsity
Encontra documentos específicos para os exames da tua universidade
Prepare-se com as videoaulas e exercícios resolvidos criados a partir da grade da sua Universidade
Responda perguntas de provas passadas e avalie sua preparação.
Ganhe pontos para baixar
Ganhe pontos ajudando outros esrudantes ou compre um plano Premium
Aprenda PROGRAMAÇÃO Python FÁCIL e RÁPIDO - 3 Aprenda agora mesmo programação Python com essas apostilas que preparei cuidadosamente e resumidamente pra vocês!
Tipologia: Esquemas
1 / 41

Esta página não é visível na pré-visualização
Não perca as partes importantes!
Impressionador do absoluto zero!
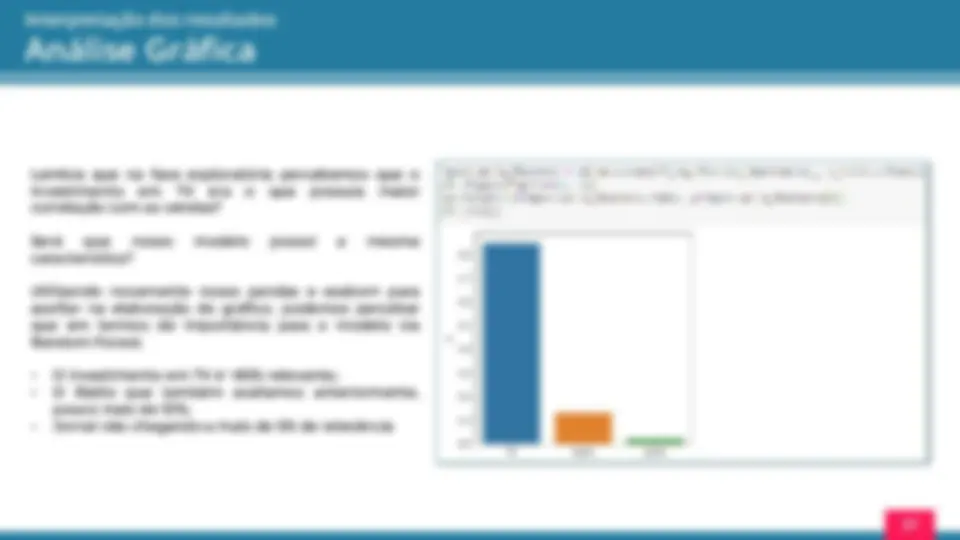
As informações que vão alimentar o nosso código, serão dados dos investimentos em propaganda em diferentes canais e as vendas decorrentes desses investimentos. A imagem ao lado, mostra base “crua”. Apesar de não estar formatada de uma forma que nos ajuda a visualização, podemos perceber que existem 4 colunas (indicadas abaixo) separadas por vírgula: Portanto, para um melhor entendimento, na primeira linha temos os 3 meios de comunicação que a Hashtag usa para vender (TV, Radio, Jornal) e o último item (Vendas) representa a quantidade em vendas resultante desses canais: Usando a segunda linha como exemplo temos que investindo 230 , 1 kBRL no Canal TV, 37 , 8 kBRL no Canal Radio, 69 , 2 kBRL no Canal Jornal foi gerada uma Venda de 22 , 1 MBRL. Como você pode ver, temos muitas informações de vendas nessa tabela, e qualquer interpretação desses dados não é uma tarefa fácil, o que é um problema. TV Jornal Radio
Entendendo a base de dados Vendas
Nosso objetivo é criar um modelo de previsão de vendas a partir do histórico de vendas e investimento em marketing. Para isso, usaremos alguns conhecimentos de Ciência de Dados. Ou seja, baseada nesse modelo, poderemos projetar (com algum grau de incerteza) a quantidade em vendas baseada nos valores investidos. Então, vamos começar!
Entendendo a solução final
P y t h o n O conceito de Ciência de Dados cada dia passa a ser mais difundido nas empresas. Essencialmente, esse conceito, tem por objetivo gerar conclusões, Modelos, a partir de grande quantidade de dados. Através de conhecimentos estatísticos alinhados ao conhecimento do negócio, a Ciência de dados permite “enxergar” além da superfície. Para que isso aconteça, é muito interessante seguir alguns passos desse processos. Preparamos um diagrama simples para você ☺
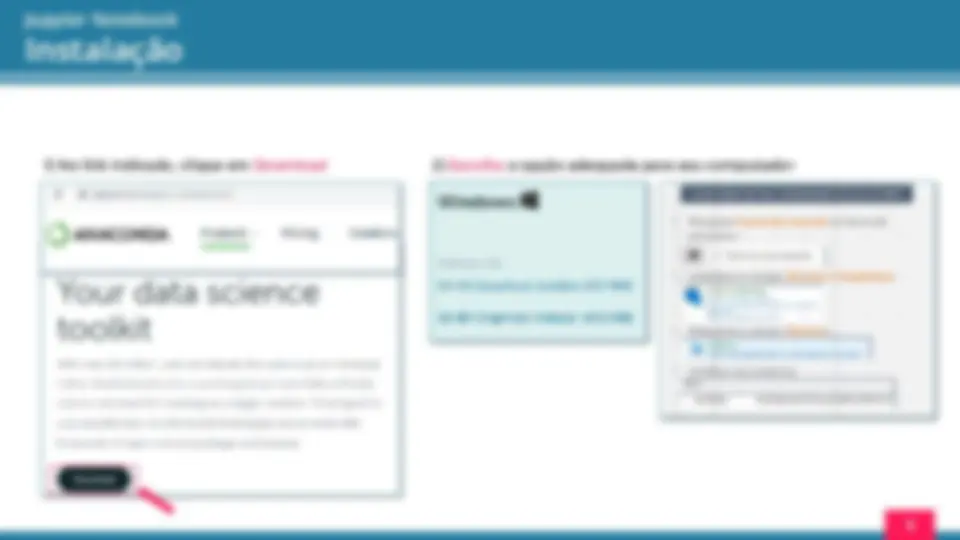
1 ) No link indicado, clique em Download
Instalação 2 ) Escolha a opção adequada para seu computador
3 ) Fazer Download
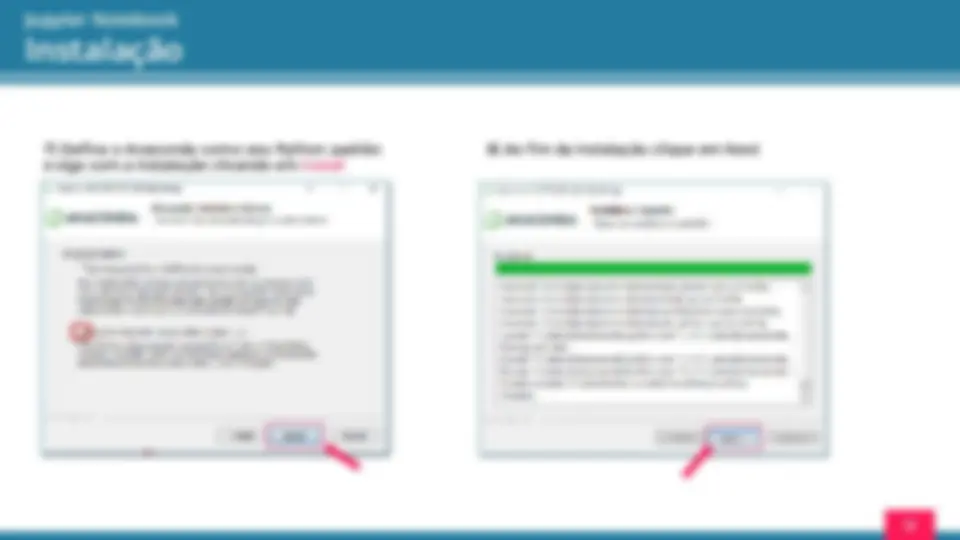
Instalação 3 ) Abra o instalador do Anaconda 4 ) Aceite os termos de uso
7 ) Defina o Anaconda como seu Python padrão e siga com a instalação clicando em Install
Instalação 8 ) Ao fim da instalação clique em Next
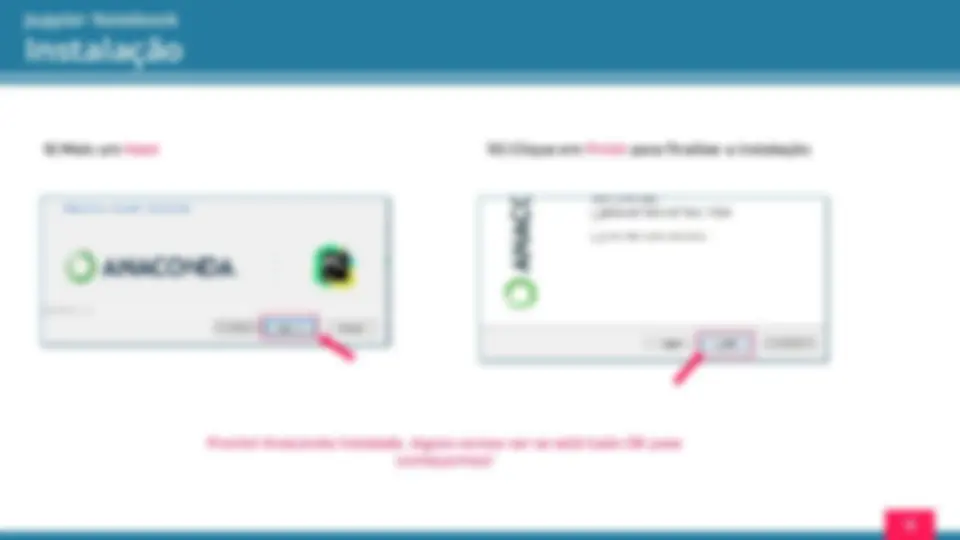
9 ) Mais um Next
Instalação 10 ) Clique em Finish para finalizar a instalação Pronto! Anaconda instalado. Agora vamos ver se está tudo OK para começarmos!
Após os preparativos, vamos acessar o nosso primeiro arquivo para criarmos nosso código em Python. Esse arquivo se chama Notebook e possui o
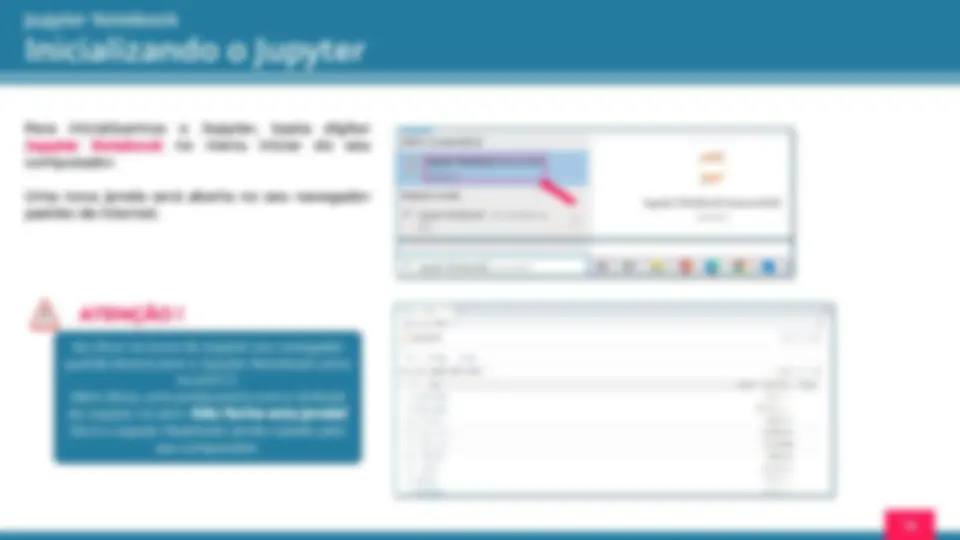
plataformas como o Google Colab ou Jupyter Notebook. Para criarmos um novo Notebook, devemos clicar em New > Python 3 , assim como apresentado na figura ao lado. Ao criar o novo Notebook, o Jupyter Notebook abrirá a janela ao lado. Aqui, é onde escreveremos nosso programa. Mas antes de tudo, vamos entender a interface dessa plataforma.
Inicializando o Jupyter
Entendendo a interface Nome do arquivo. Formato ipynb. Célula onde deve ser escrito o código Região de Output Cria nova célula Executa o código
Parâmetro opcional. Quando utilizado, permite alterar a forma como a biblioteca será acionada. Como vimos no nosso diagrama, as partes 1 e 2 do nosso processo de Ciência de Dados é realizada FORA do Python. De forma bem simples, são as informações que introduzimos no Capítulo 1 dessa apostila. Agora vamos para a primeira etapa DENTRO do Python. A de obtenção de dados de fontes externas. Apesar de agora ter um nome mais bonito, é algo que já vimos nas aulas 1 e 2 da Semana do Python. Usando o PANDAS podemos realizar essa importação dos dados do arquivo CSV e leva-los para o Jupyter Notebook. Para realizar essa etapa, iremos usar a linha de código abaixo: Import pandas as pd Caso você ainda não conheça o Pandas, sugerimos dar uma olhadinha nas apostilas das aulas 1 e 2 ☺.
Importando o Pandas Indica que importaremos uma biblioteca/módulo para ser utilizado no nosso código Biblioteca que está sendo importada. Ela poderá ser usado em todas as linhas de código deste arquivo Ao invés de ser acionado como PANDAS, será acionado como pd. Funciona como um “apelido”.
Como vimos no nosso diagrama, as partes 1 e 2 do nosso processo de Ciência de Dados é realizada FORA do Python. De forma bem simples, são as informações que introduzimos no Capítulo 1 dessa apostila. Agora vamos para a primeira etapa DENTRO do Python. A de obtenção de dados de fontes externas. Apesar de agora ter um nome mais bonito, é algo que já vimos nas aulas 1 e 2 na Semana do Python. Usando o PANDAS podemos realizar essa importação dos dados do arquivo CSV e leva-los para o Jupyter Notebook. Para realizar essa etapa, iremos usar a linha de código abaixo: Import pandas as pd Caso você ainda não conheça o Pandas, sugerimos dar uma olhadinha nas apostilas das aulas 1 e 2 ☺.
Importando os dados de um arquivo .csv df é uma variável criada para receber os valores importados pelo Pandas pd “ativa” a biblioteca Pandas Método que nos permite ler um arquivo .csv Nome do arquivo que queremos importar. Perceba que não indicamos a pasta que ele se encontra. Isso só é possível pois o arquivo está na MESMA PASTA que o arquivo que estamos trabalhando.